

Splice-Junction-Based Mapping of Alternative Isoforms in the Human Proteome
- PMID: 31825849
- PMCID: PMC6961840
- DOI: 10.1016/j.celrep.2019.11.026
Splice-Junction-Based Mapping of Alternative Isoforms in the Human Proteome
Abstract
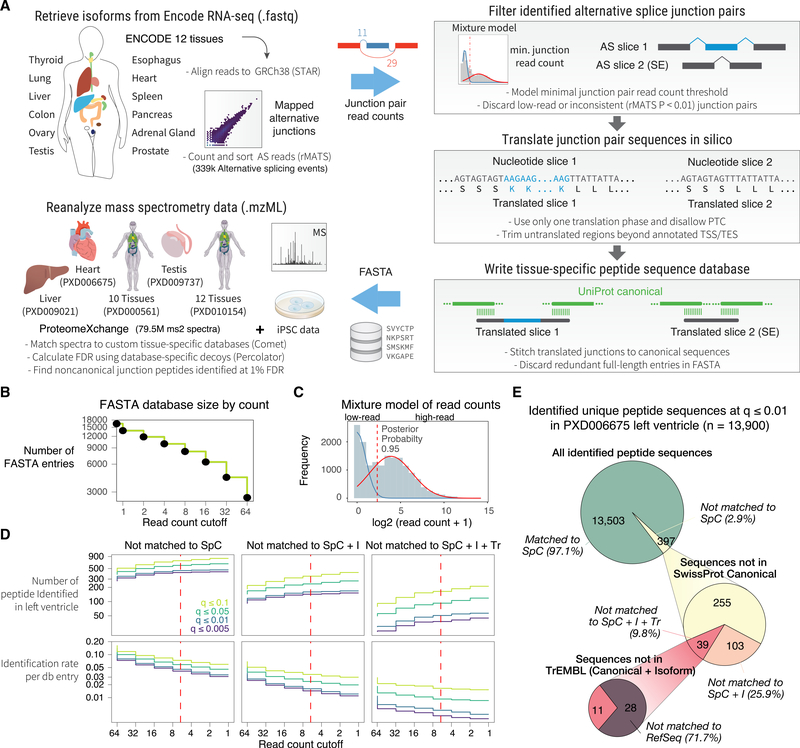
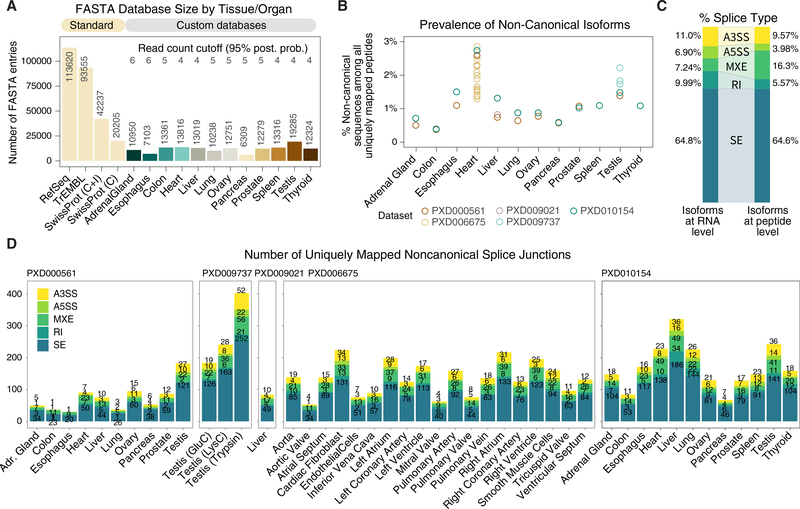
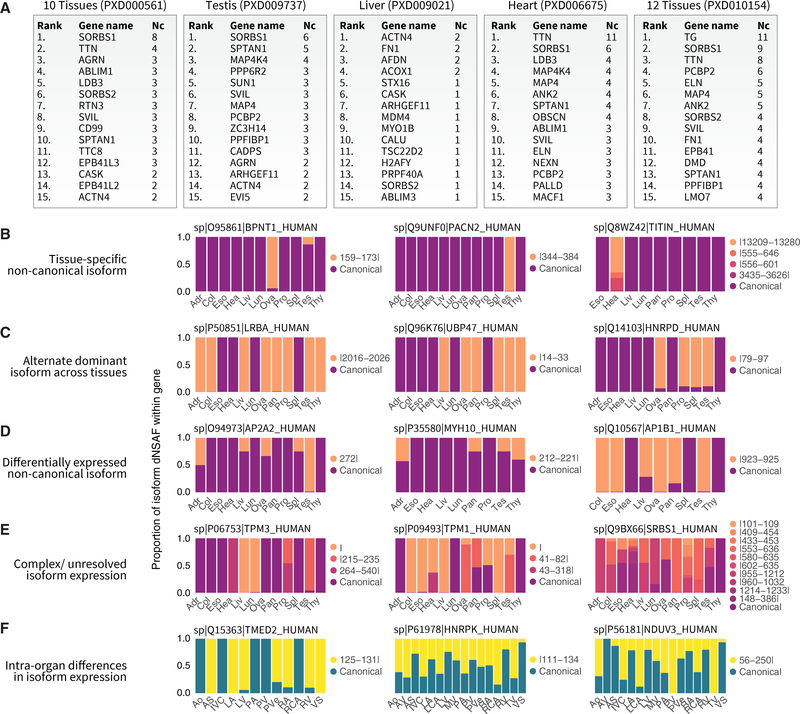
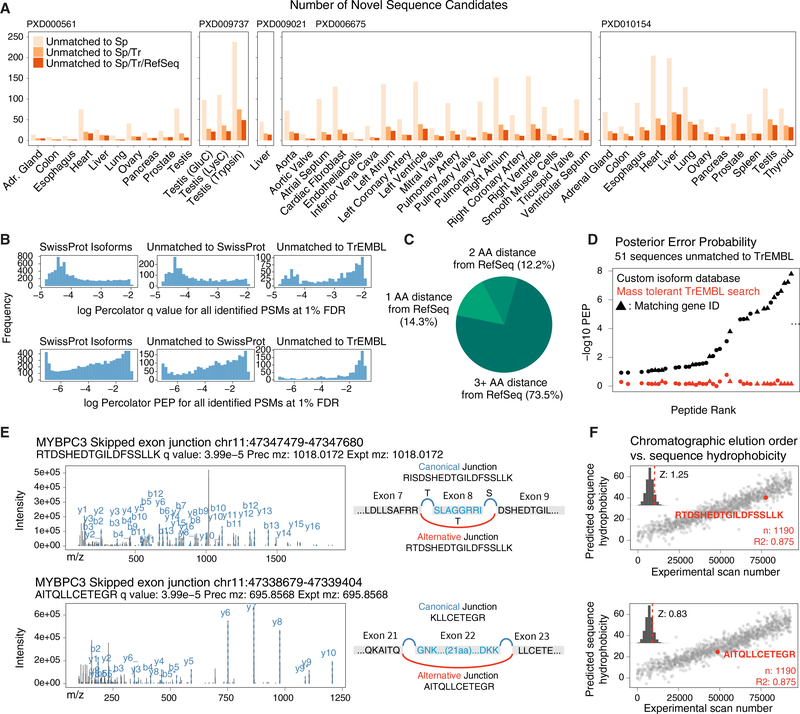
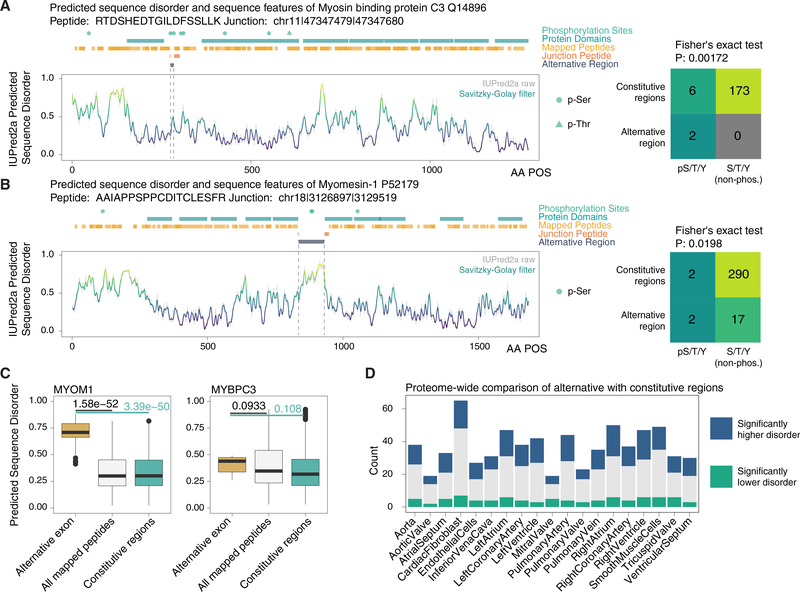
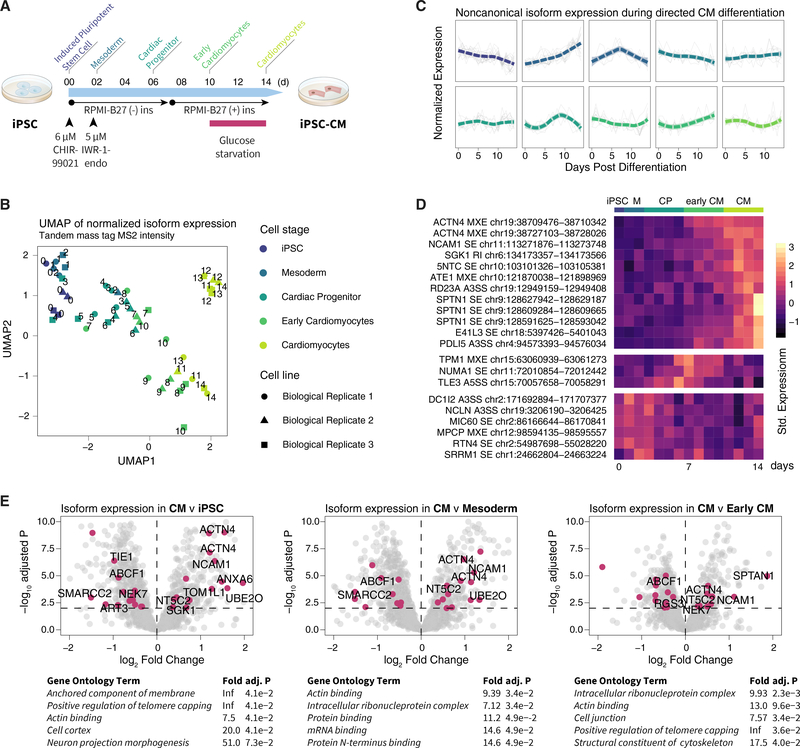
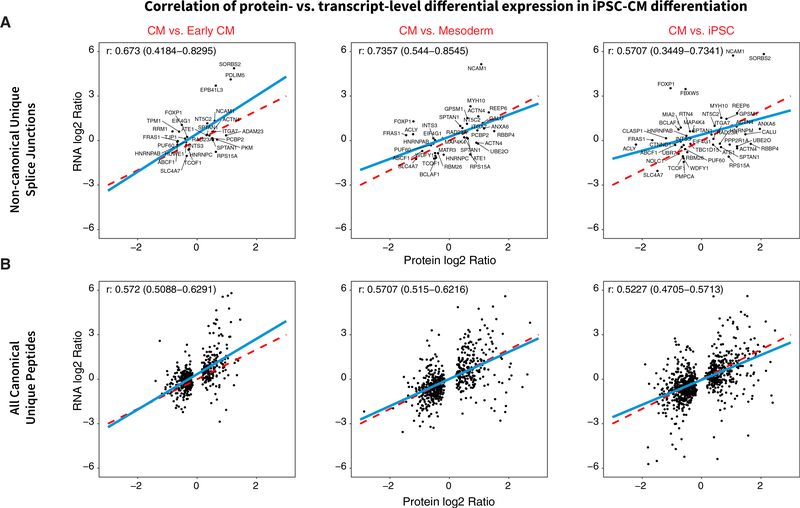
The protein-level translational status and function of many alternative splicing events remain poorly understood. We use an RNA sequencing (RNA-seq)-guided proteomics method to identify protein alternative splicing isoforms in the human proteome by constructing tissue-specific protein databases that prioritize transcript splice junction pairs with high translational potential. Using the custom databases to reanalyze ∼80 million mass spectra in public proteomics datasets, we identify more than 1,500 noncanonical protein isoforms across 12 human tissues, including ∼400 sequences undocumented on TrEMBL and RefSeq databases. We apply the method to original quantitative mass spectrometry experiments and observe widespread isoform regulation during human induced pluripotent stem cell cardiomyocyte differentiation. On a proteome scale, alternative isoform regions overlap frequently with disordered sequences and post-translational modification sites, suggesting that alternative splicing may regulate protein function through modulating intrinsically disordered regions. The described approach may help elucidate functional consequences of alternative splicing and expand the scope of proteomics investigations in various systems.
Keywords: alternative splicing; cardiomyocyte differentiation; human proteome; induced pluripotent stem cells; intrinsically disordered region; mass spectrometry; protein isoforms; proteoforms; proteomics; splice isoforms.
Copyright © 2019 The Author(s). Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
DECLARATION OF INTERESTS
The authors declare no competing interests.
Figures
References
-
- Adusumilli R, and Mallick P (2017). Data Conversion with ProteoWizard msConvert. Methods Mol. Biol 1550, 339–368. - PubMed
-
- Alfaro JA, Sinha A, Kislinger T, and Boutros PC (2014). Onco-proteogenomics: cancer proteomics joins forces with genomics. Nat. Methods 11, 1107–1113. - PubMed
-
- Barbosa-Morais NL, Irimia M, Pan Q, Xiong HY, Gueroussov S, Lee LJ, Slobodeniuc V, Kutter C, Watt S, Colak R, et al. (2012). The evolutionary landscape of alternative splicing in vertebrate species. Science 338, 1587–1593. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
