

Task complexity interacts with state-space uncertainty in the arbitration between model-based and model-free learning
- PMID: 31844060
- PMCID: PMC6915739
- DOI: 10.1038/s41467-019-13632-1
Task complexity interacts with state-space uncertainty in the arbitration between model-based and model-free learning
Abstract
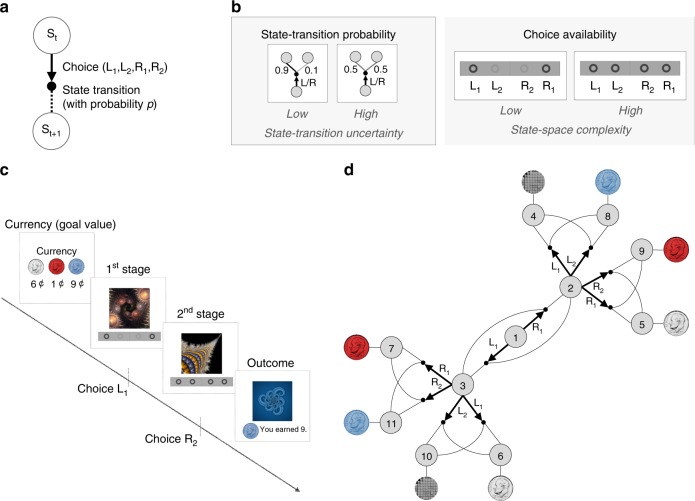
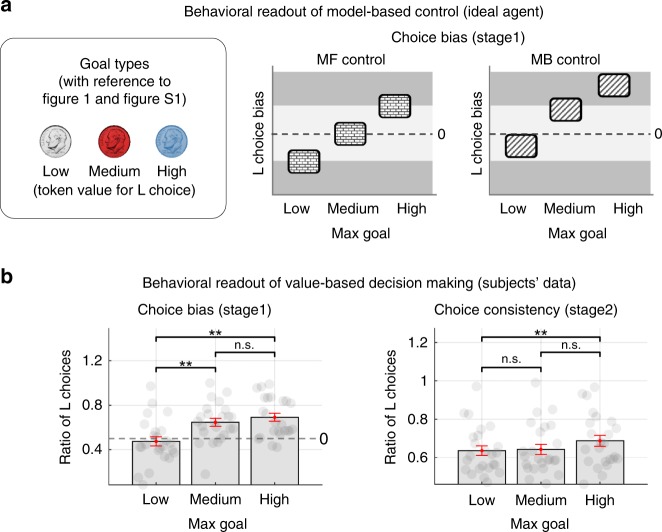
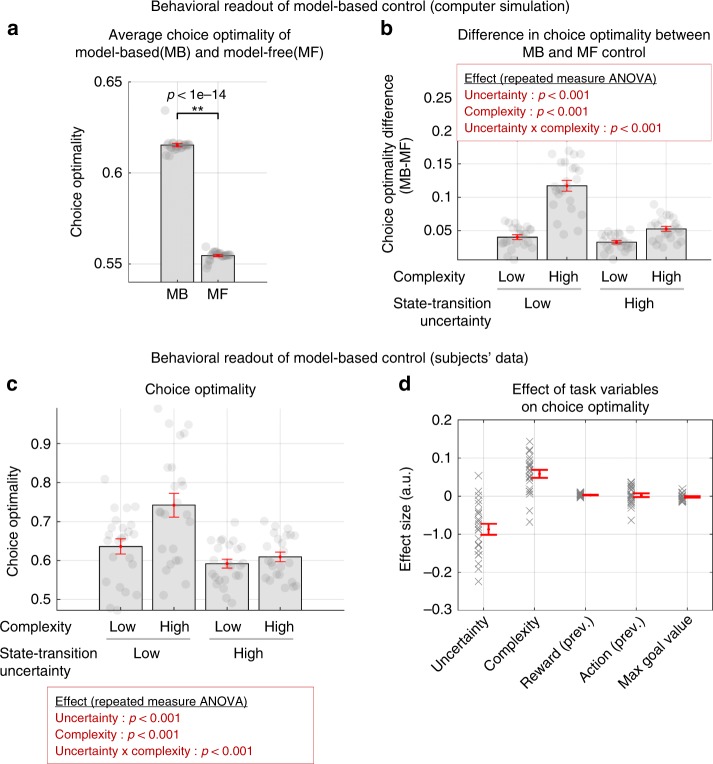
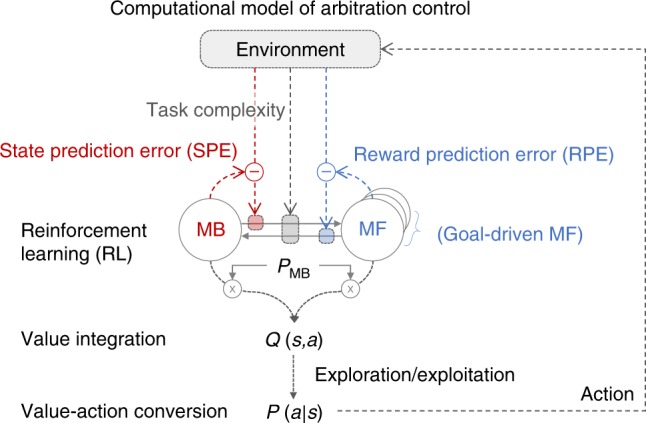
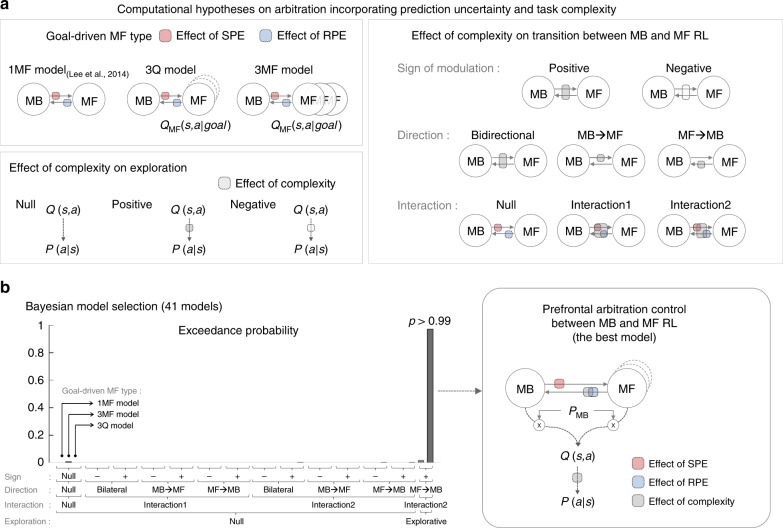
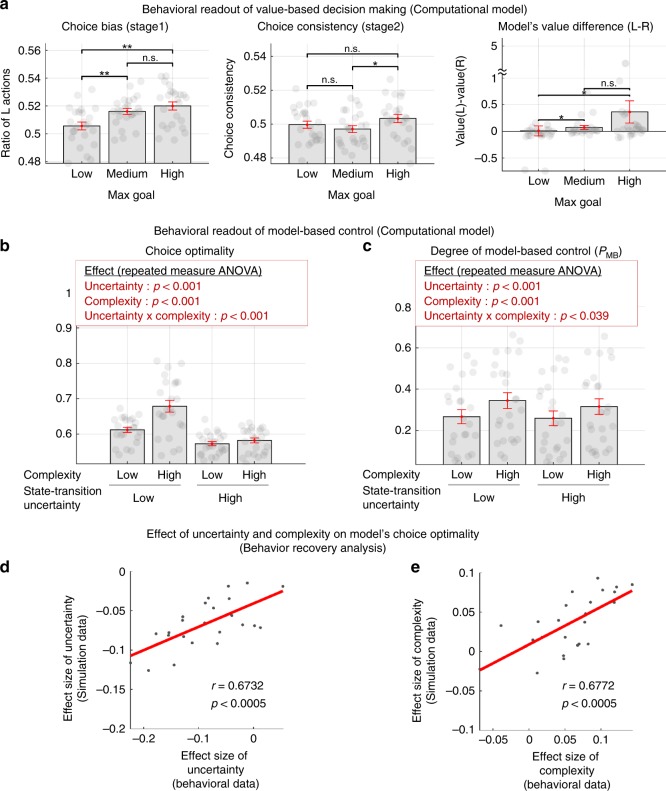
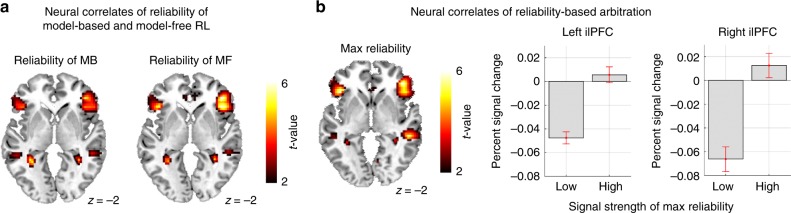
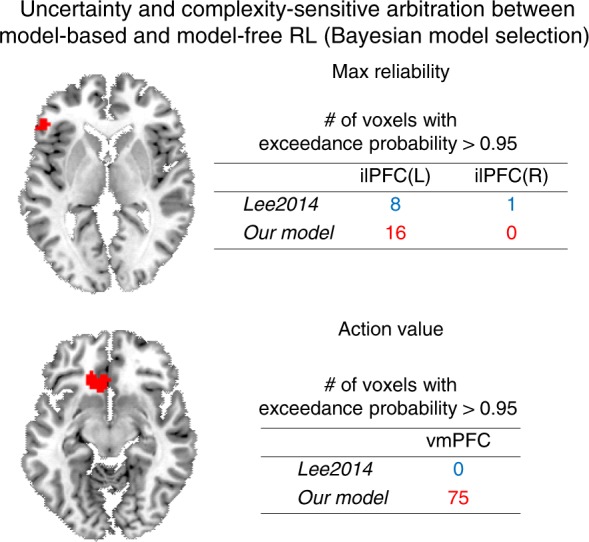
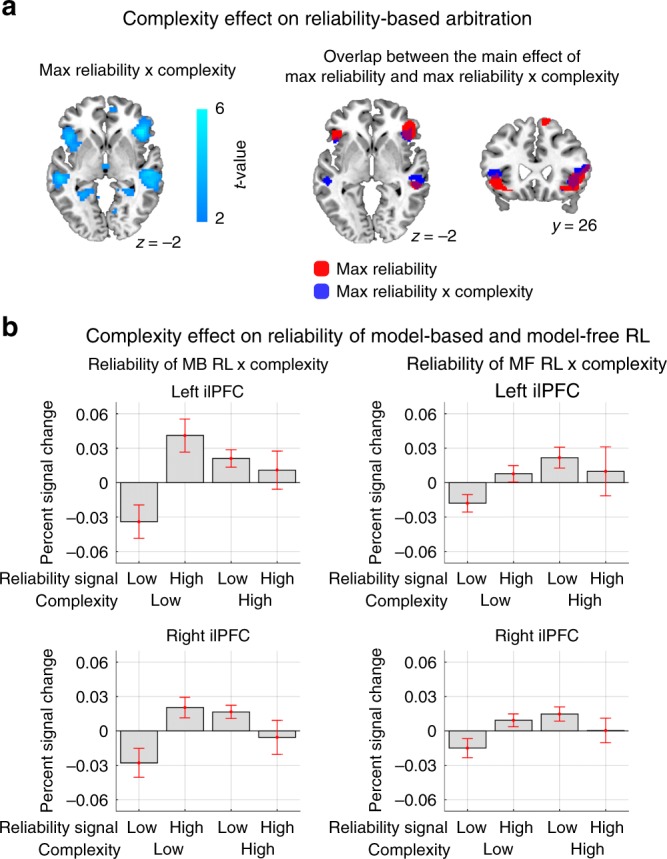
It has previously been shown that the relative reliability of model-based and model-free reinforcement-learning (RL) systems plays a role in the allocation of behavioral control between them. However, the role of task complexity in the arbitration between these two strategies remains largely unknown. Here, using a combination of novel task design, computational modelling, and model-based fMRI analysis, we examined the role of task complexity alongside state-space uncertainty in the arbitration process. Participants tended to increase model-based RL control in response to increasing task complexity. However, they resorted to model-free RL when both uncertainty and task complexity were high, suggesting that these two variables interact during the arbitration process. Computational fMRI revealed that task complexity interacts with neural representations of the reliability of the two systems in the inferior prefrontal cortex.
Conflict of interest statement
The authors declare no competing interests.
Figures
References
-
- Dickinson A. Actions and habits: the development of behavioural autonomy. Philos. Trans. R. Soc. B Biol. Sci. 1985;308:67–78. doi: 10.1098/rstb.1985.0010. - DOI
-
- Kuvayev, L., Kuvayev, L. & Sutton, R. S. Model-based reinforcement learning with an approximate, learned model. In Proc. Ninth Yale Work. Adapt. Learn. Syst. (New Haven, CT) Vol. 8, 101–105 (1996).
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
