

Outcome contingency selectively affects the neural coding of outcomes but not of tasks
- PMID: 31852993
- PMCID: PMC6920387
- DOI: 10.1038/s41598-019-55887-0
Outcome contingency selectively affects the neural coding of outcomes but not of tasks
Abstract
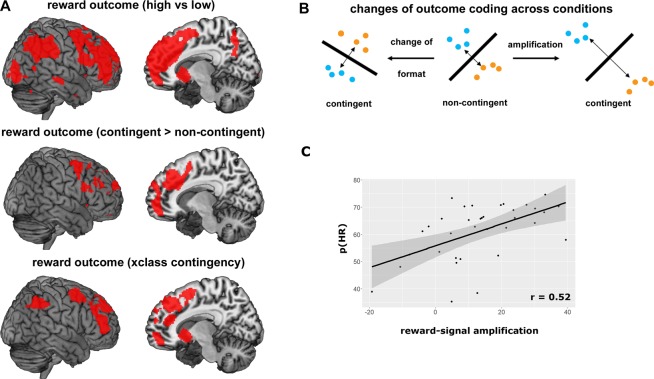
Value-based decision-making is ubiquitous in every-day life, and critically depends on the contingency between choices and their outcomes. Only if outcomes are contingent on our choices can we make meaningful value-based decisions. Here, we investigate the effect of outcome contingency on the neural coding of rewards and tasks. Participants performed a reversal-learning paradigm in which reward outcomes were contingent on trial-by-trial choices, and performed a 'free choice' paradigm in which rewards were random and not contingent on choices. We hypothesized that contingent outcomes enhance the neural coding of rewards and tasks, which was tested using multivariate pattern analysis of fMRI data. Reward outcomes were encoded in a large network including the striatum, dmPFC and parietal cortex, and these representations were indeed amplified for contingent rewards. Tasks were encoded in the dmPFC at the time of decision-making, and in parietal cortex in a subsequent maintenance phase. We found no evidence for contingency-dependent modulations of task signals, demonstrating highly similar coding across contingency conditions. Our findings suggest selective effects of contingency on reward coding only, and further highlight the role of dmPFC and parietal cortex in value-based decision-making, as these were the only regions strongly involved in both reward and task coding.
Conflict of interest statement
The authors declare no competing interests.
Figures



References
-
- Domenech P, Redouté J, Koechlin E, Dreher J-C. The Neuro-Computational Architecture of Value-Based Selection in the Human Brain. Cereb. Cortex. 2018;28:585–601. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
