

The Indian cobra reference genome and transcriptome enables comprehensive identification of venom toxins
- PMID: 31907489
- PMCID: PMC8075977
- DOI: 10.1038/s41588-019-0559-8
The Indian cobra reference genome and transcriptome enables comprehensive identification of venom toxins
Abstract
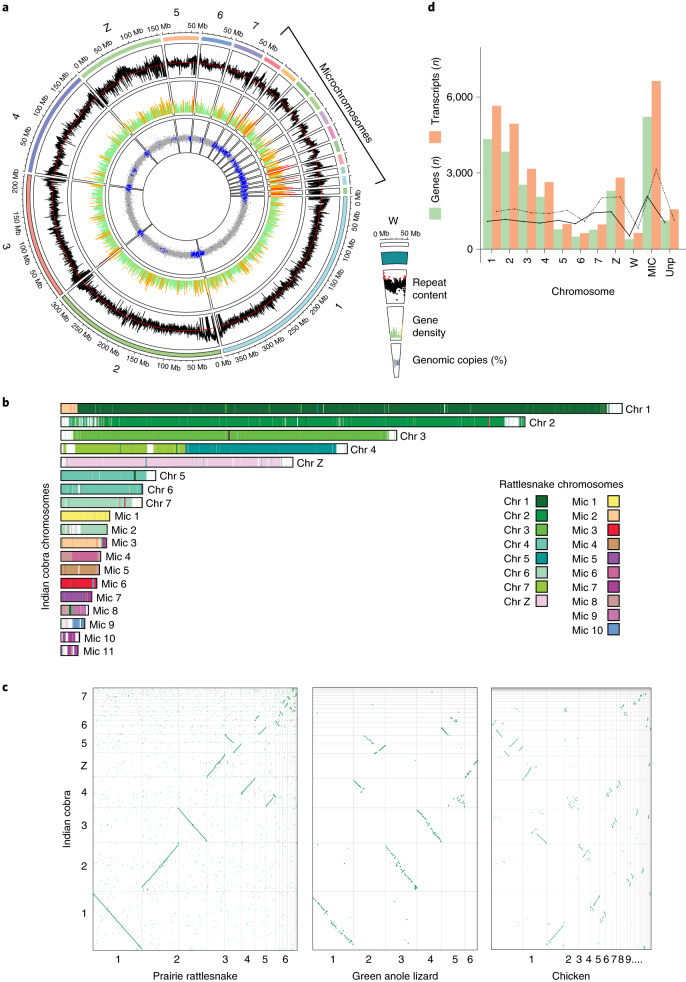
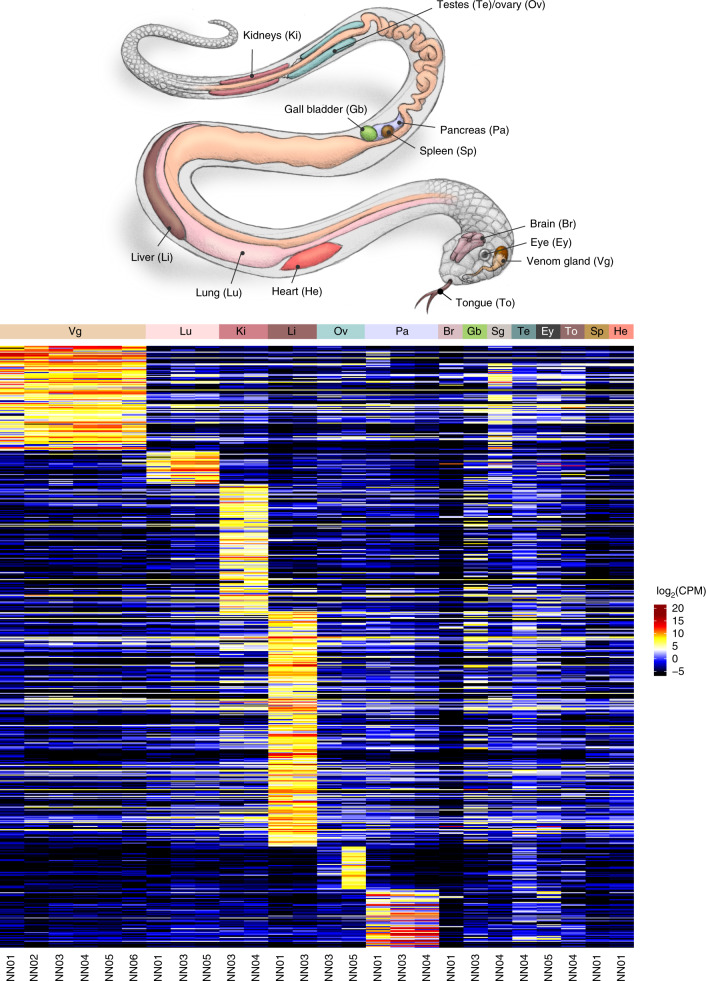
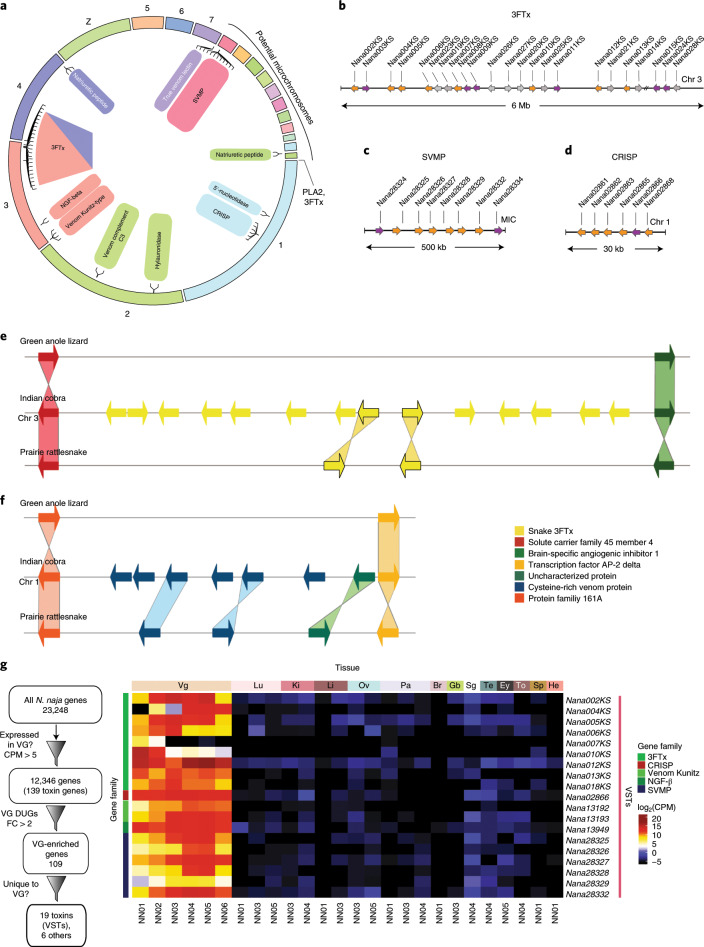
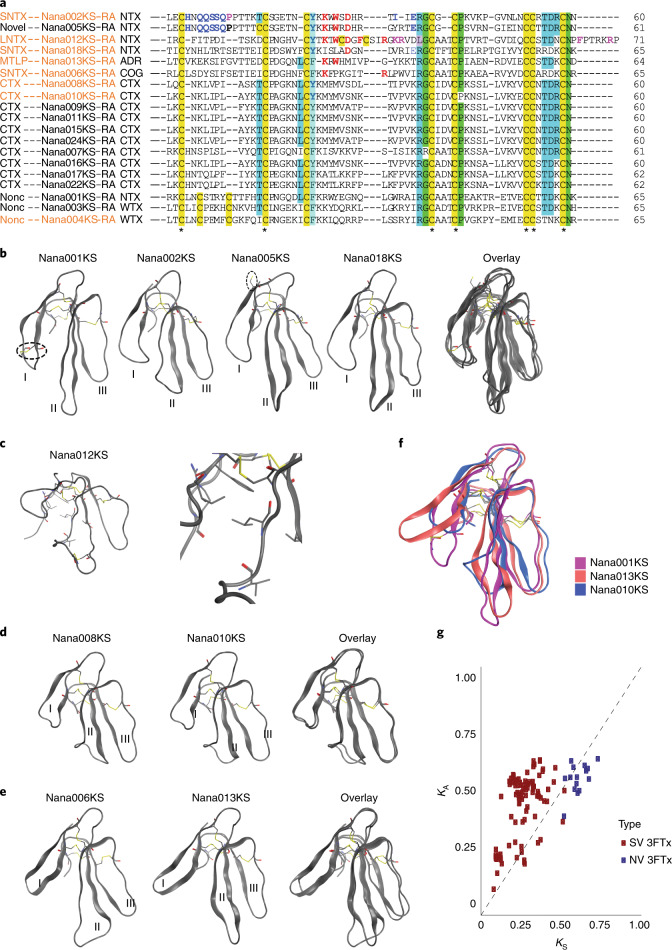
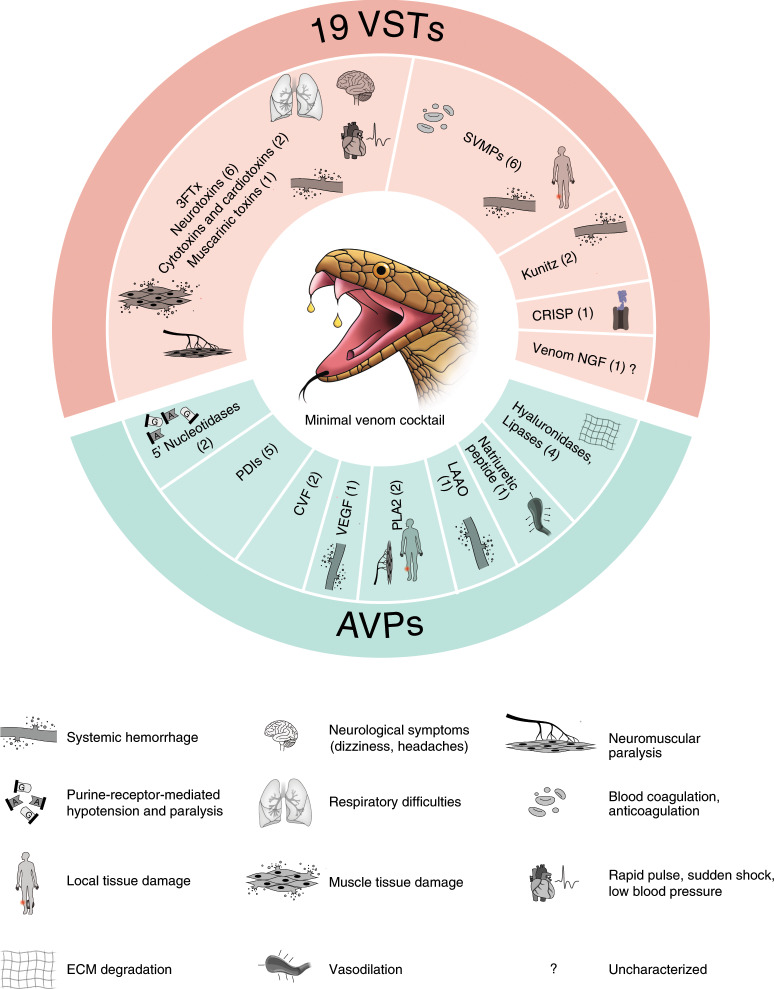
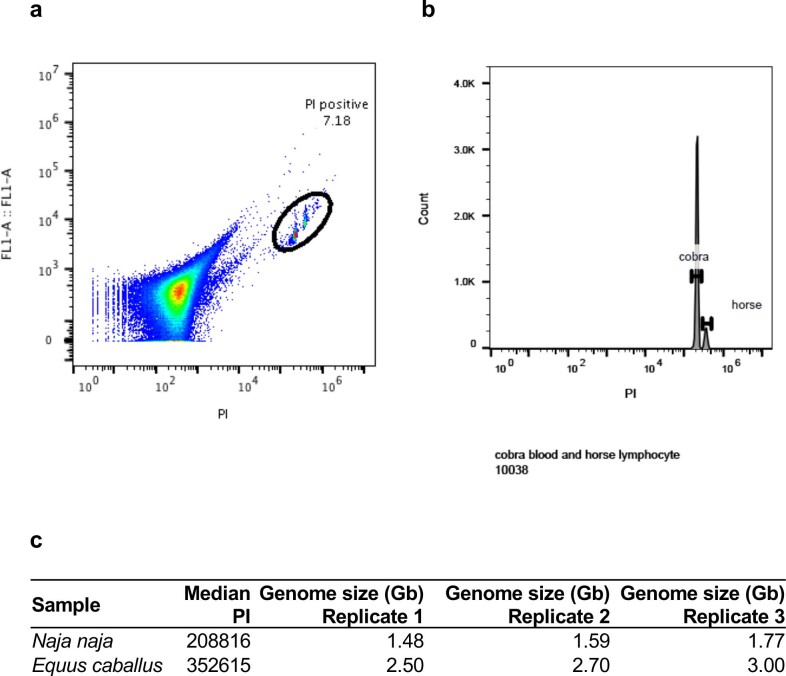
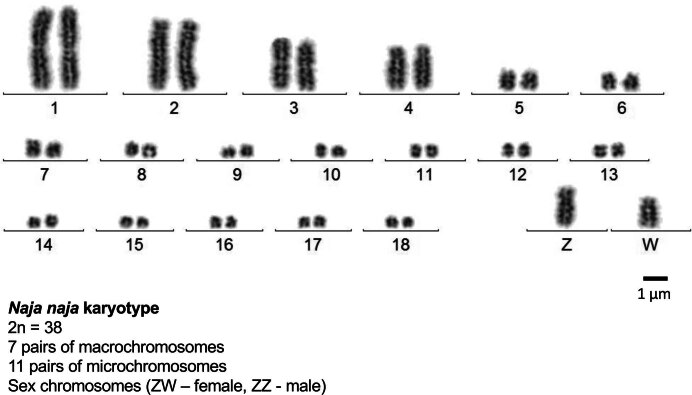
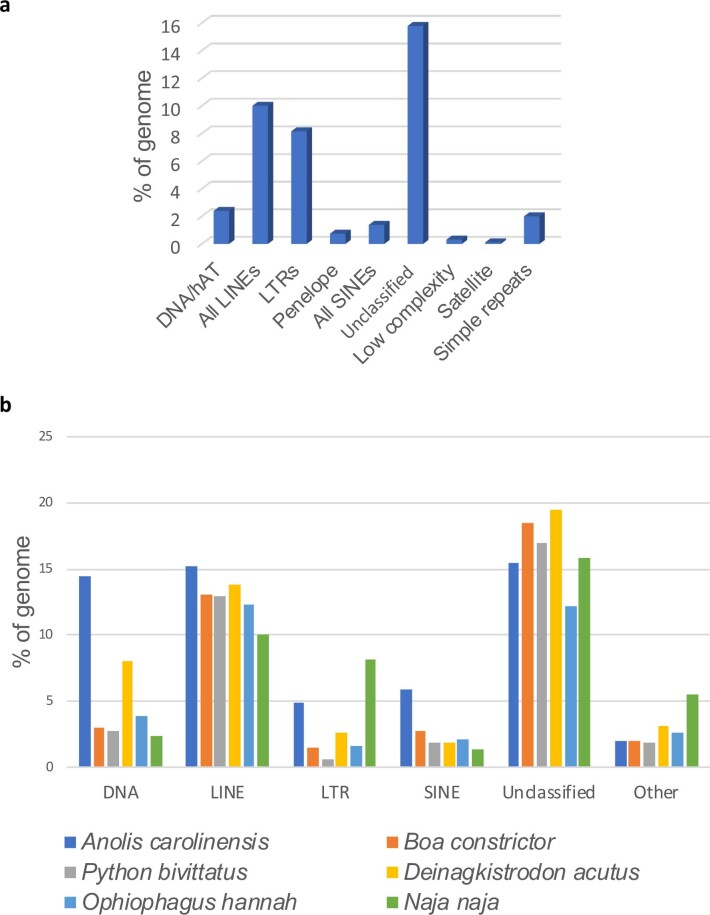
Snakebite envenoming is a serious and neglected tropical disease that kills ~100,000 people annually. High-quality, genome-enabled comprehensive characterization of toxin genes will facilitate development of effective humanized recombinant antivenom. We report a de novo near-chromosomal genome assembly of Naja naja, the Indian cobra, a highly venomous, medically important snake. Our assembly has a scaffold N50 of 223.35 Mb, with 19 scaffolds containing 95% of the genome. Of the 23,248 predicted protein-coding genes, 12,346 venom-gland-expressed genes constitute the 'venom-ome' and this included 139 genes from 33 toxin families. Among the 139 toxin genes were 19 'venom-ome-specific toxins' (VSTs) that showed venom-gland-specific expression, and these probably encode the minimal core venom effector proteins. Synthetic venom reconstituted through recombinant VST expression will aid in the rapid development of safe and effective synthetic antivenom. Additionally, our genome could serve as a reference for snake genomes, support evolutionary studies and enable venom-driven drug discovery.
Conflict of interest statement
Employees of Genentech hold Roche shares/options, and employees of MedGenome hold MedGenome shares/options.
Figures

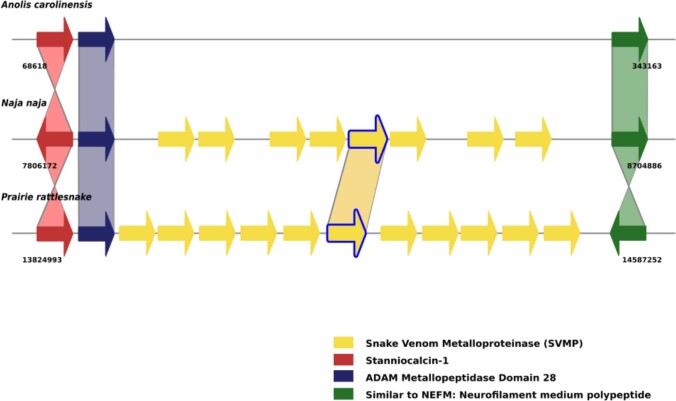
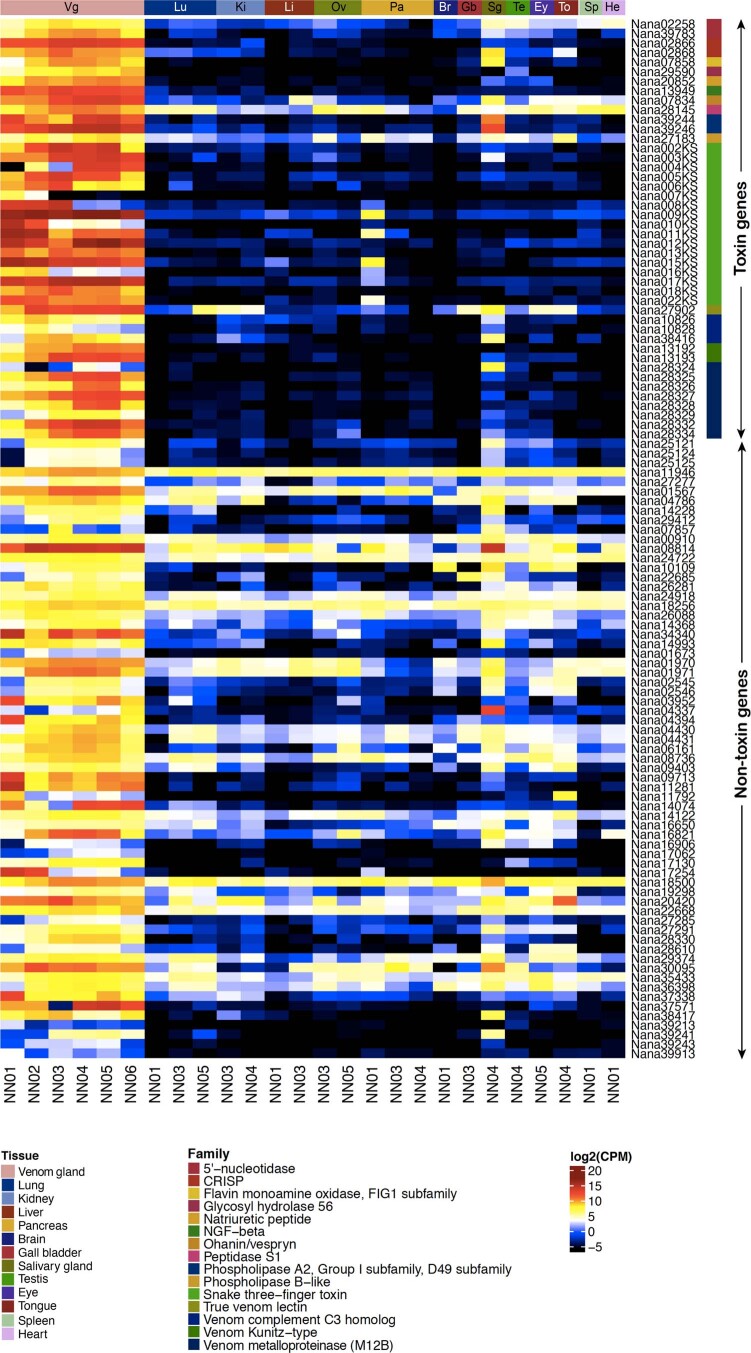
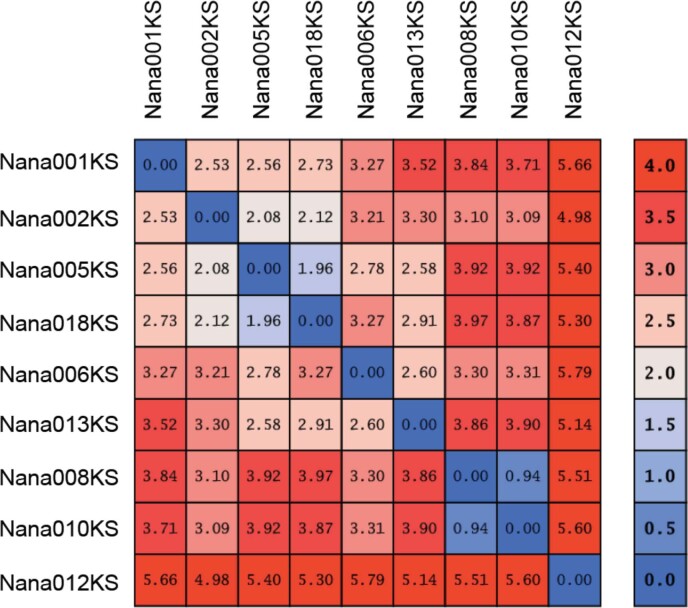

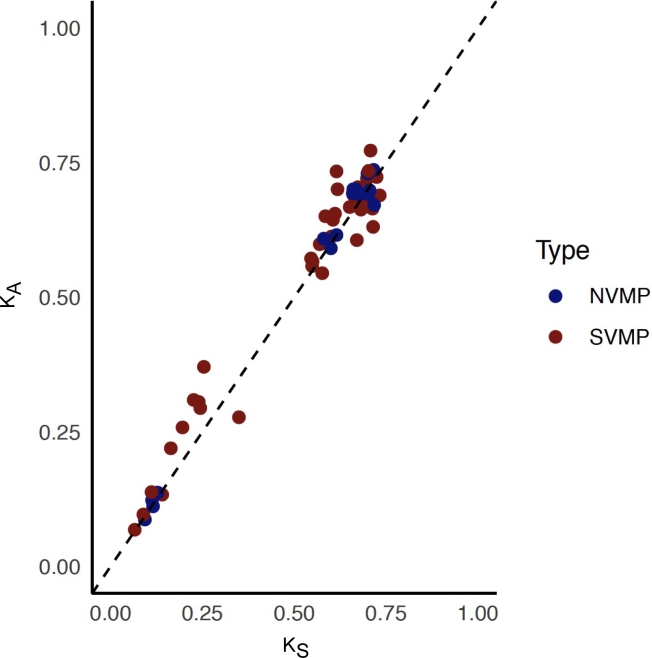


Comment in
-
Omics and organoids - a route to improved anti-venom.Nat Rev Genet. 2020 Mar;21(3):133. doi: 10.1038/s41576-020-0214-3. Nat Rev Genet. 2020. PMID: 31992867 No abstract available.
References
-
- Fry, B. G. & Wuster, W. Assembling an arsenal: origin and evolution of the snake venom proteome inferred from phylogenetic analysis of toxin sequences. Mol. Biol. Evol.21, 870–883 (2004). - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Miscellaneous
