

Deep Learning with Dynamically Weighted Loss Function for Sensor-Based Prognostics and Health Management
- PMID: 32012944
- PMCID: PMC7038523
- DOI: 10.3390/s20030723
Deep Learning with Dynamically Weighted Loss Function for Sensor-Based Prognostics and Health Management
Abstract
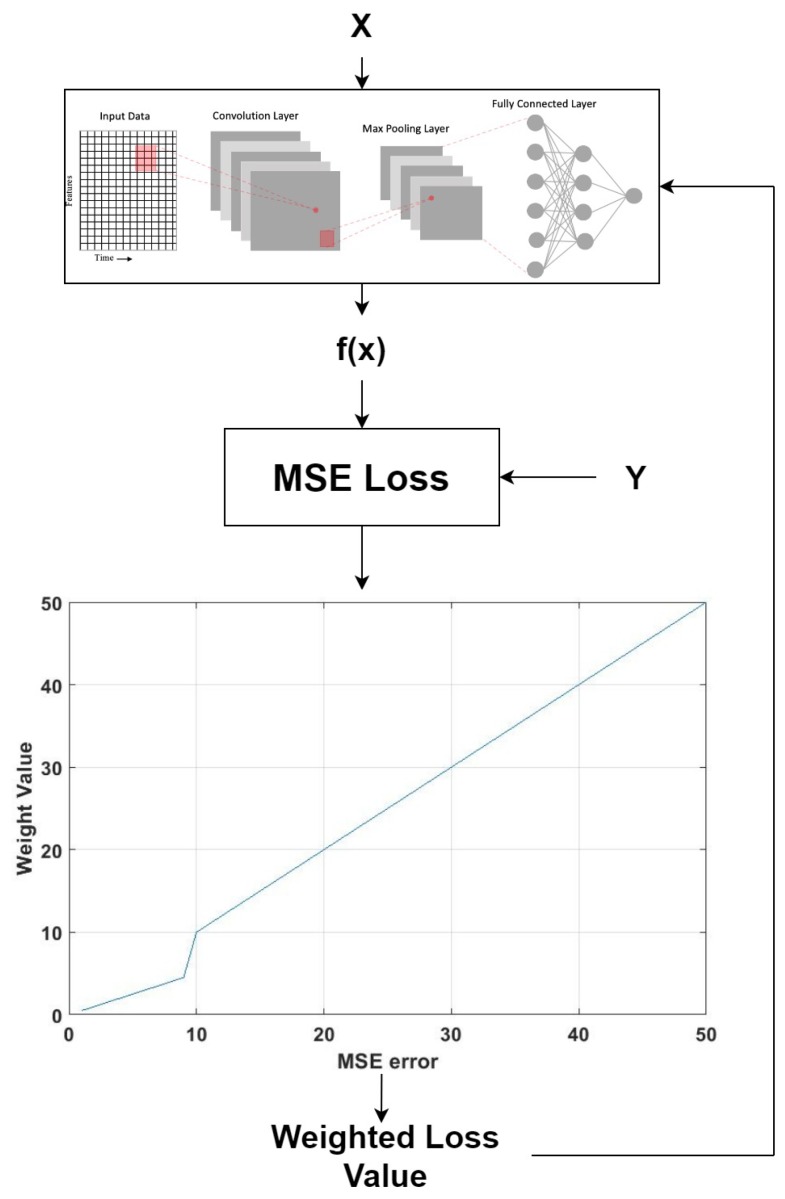
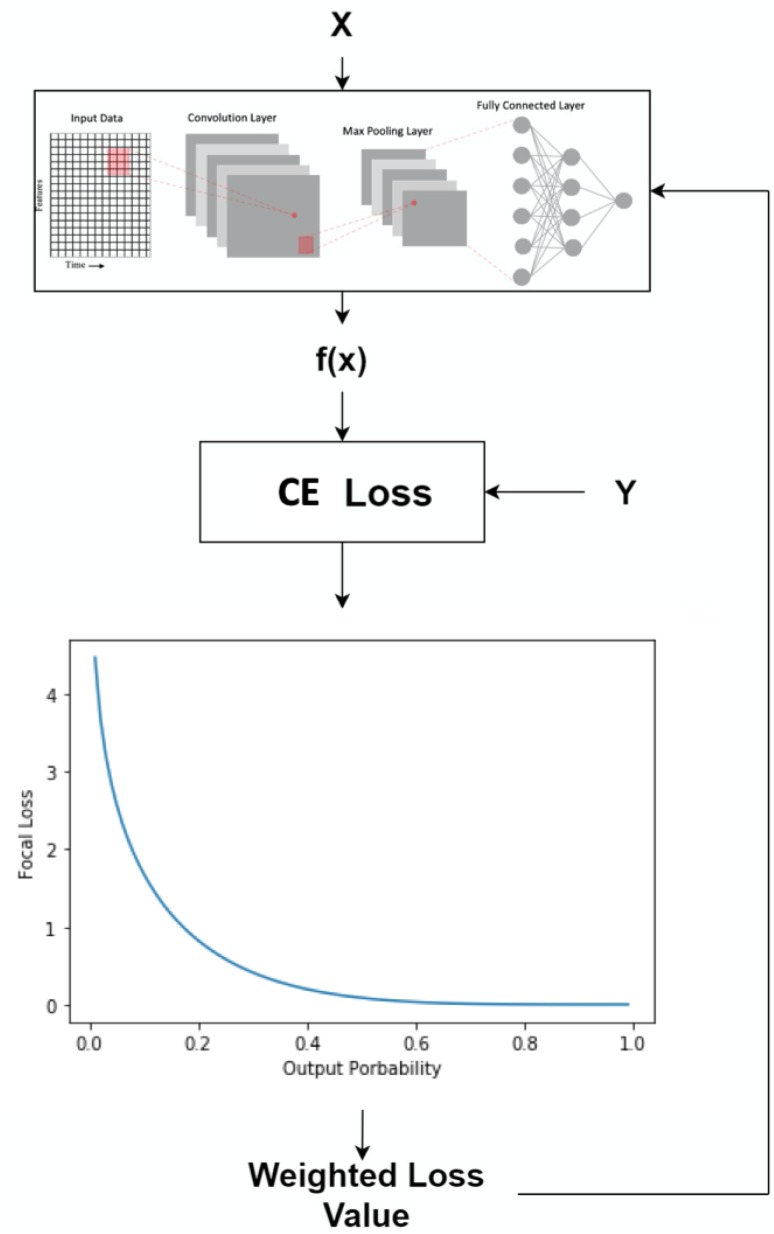
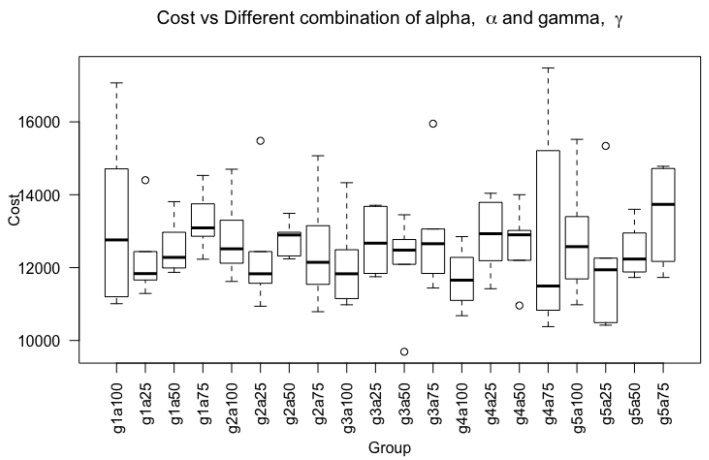
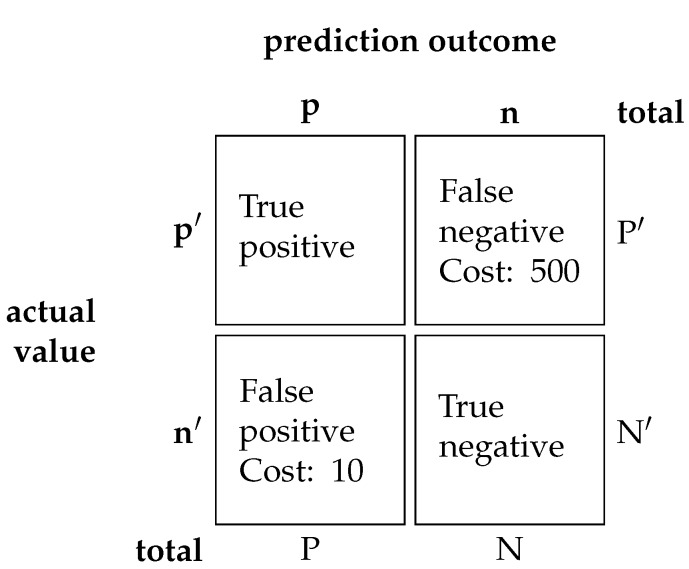
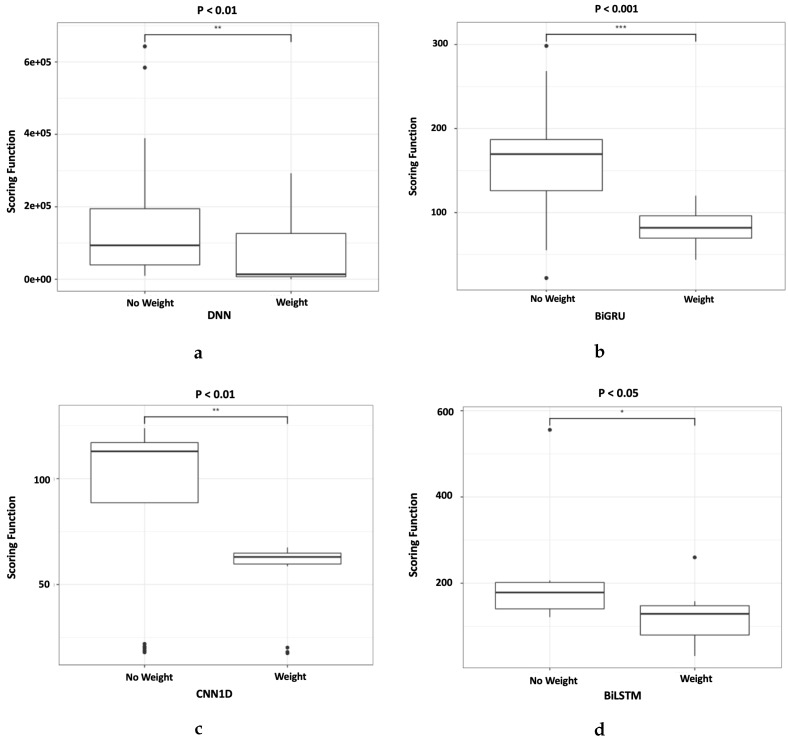
Deep learning has been employed to prognostic and health management of automotive and aerospace with promising results. Literature in this area has revealed that most contributions regarding deep learning is largely focused on the model's architecture. However, contributions regarding improvement of different aspects in deep learning, such as custom loss function for prognostic and health management are scarce. There is therefore an opportunity to improve upon the effectiveness of deep learning for the system's prognostics and diagnostics without modifying the models' architecture. To address this gap, the use of two different dynamically weighted loss functions, a newly proposed weighting mechanism and a focal loss function for prognostics and diagnostics task are investigated. A dynamically weighted loss function is expected to modify the learning process by augmenting the loss function with a weight value corresponding to the learning error of each data instance. The objective is to force deep learning models to focus on those instances where larger learning errors occur in order to improve their performance. The two loss functions used are evaluated using four popular deep learning architectures, namely, deep feedforward neural network, one-dimensional convolutional neural network, bidirectional gated recurrent unit and bidirectional long short-term memory on the commercial modular aero-propulsion system simulation data from NASA and air pressure system failure data for Scania trucks. Experimental results show that dynamically-weighted loss functions helps us achieve significant improvement for remaining useful life prediction and fault detection rate over non-weighted loss function predictions.
Keywords: deep learning; loss function; predictive maintenance; prognostics and health management; weighted loss function.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
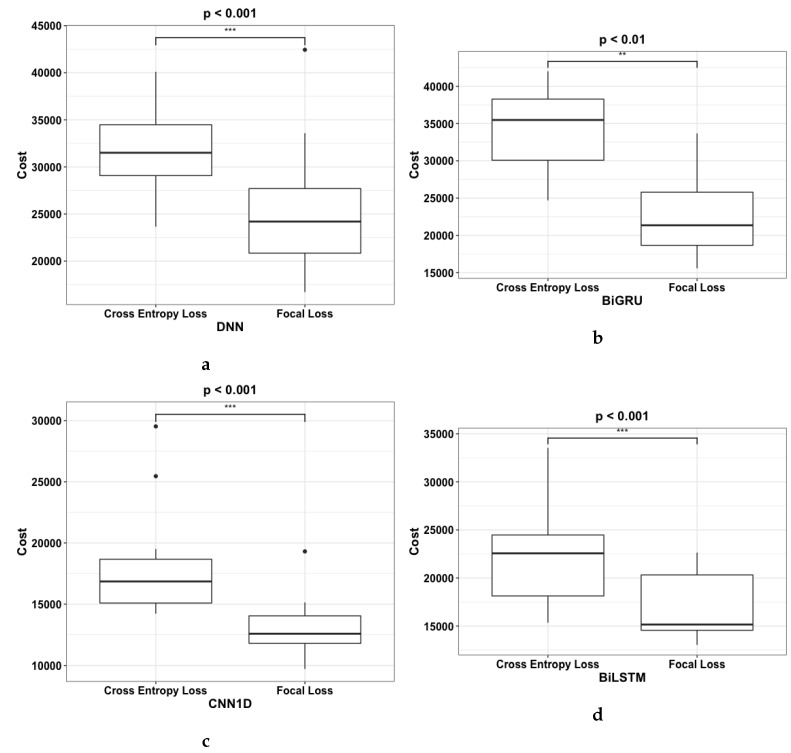
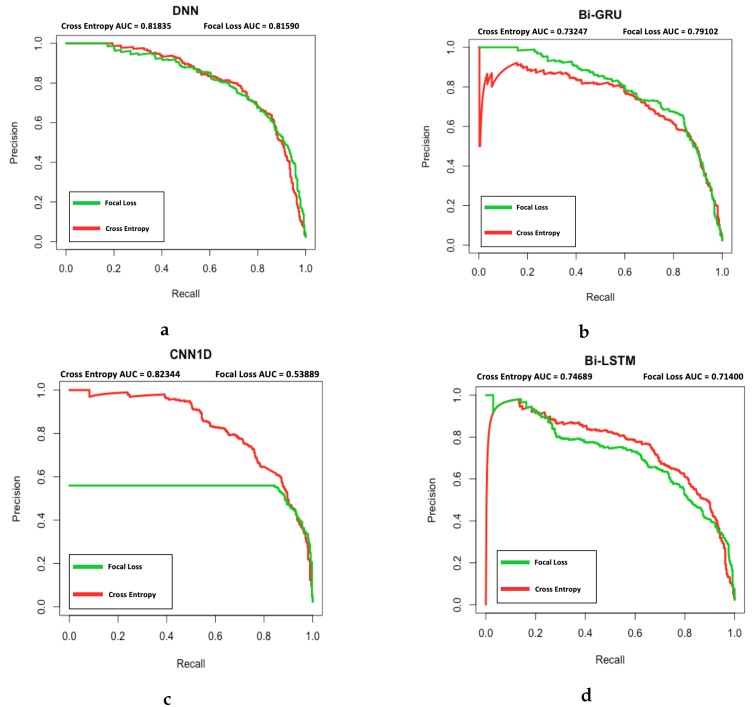
References
-
- He Y., Gu C., Chen Z., Han X. Integrated predictive maintenance strategy for manufacturing systems by combining quality control and mission reliability analysis. Int. J. Prod. Res. 2017;55:5841–5862. doi: 10.1080/00207543.2017.1346843. - DOI
-
- Tsui K.L., Chen N., Zhou Q., Hai Y., Wang W. Prognostics and Health Management: A Review on Data Driven Approaches. Math. Prob. Eng. 2015;2015:793161. doi: 10.1155/2015/793161. - DOI
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous
