

M3C: Monte Carlo reference-based consensus clustering
- PMID: 32020004
- PMCID: PMC7000518
- DOI: 10.1038/s41598-020-58766-1
M3C: Monte Carlo reference-based consensus clustering
Abstract
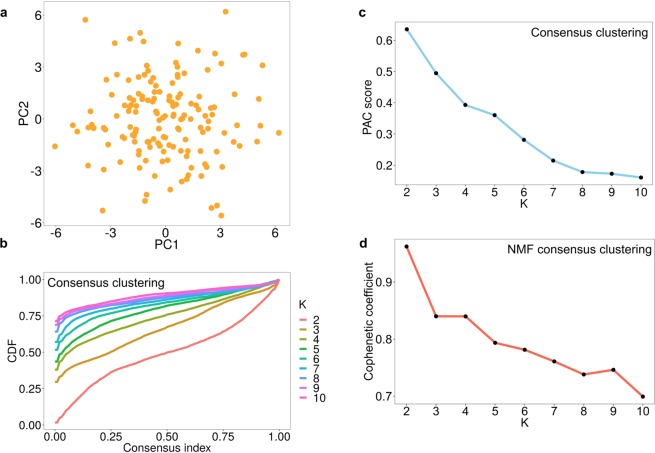
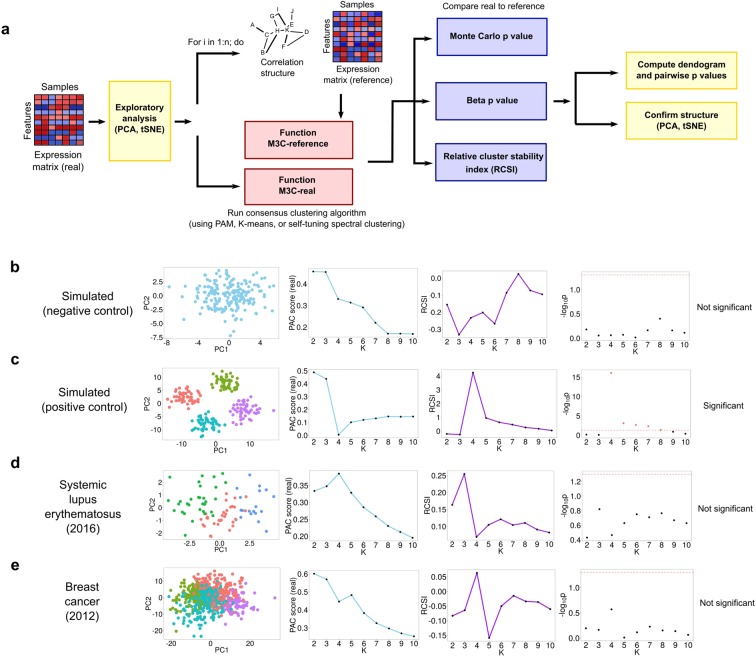
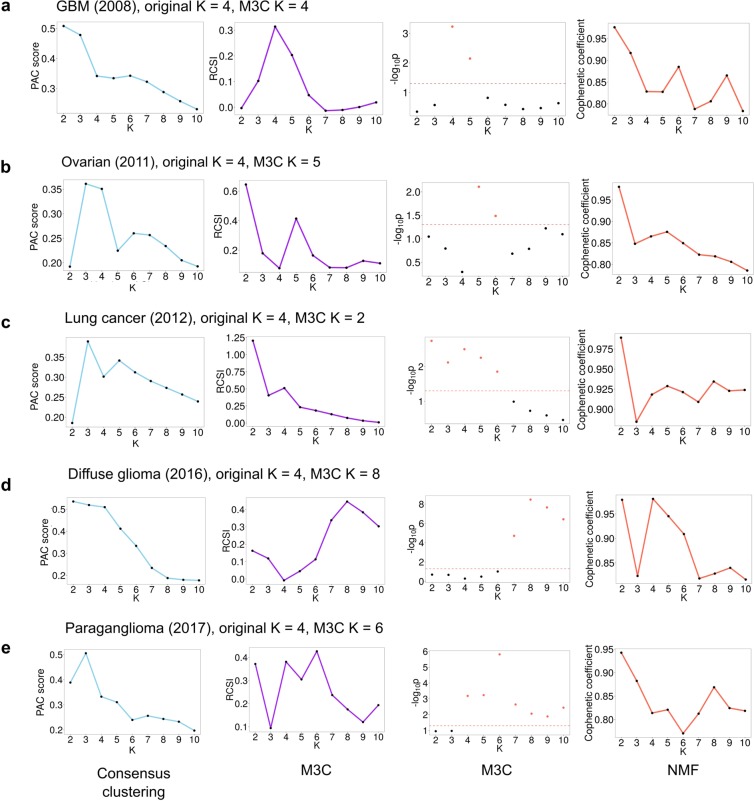
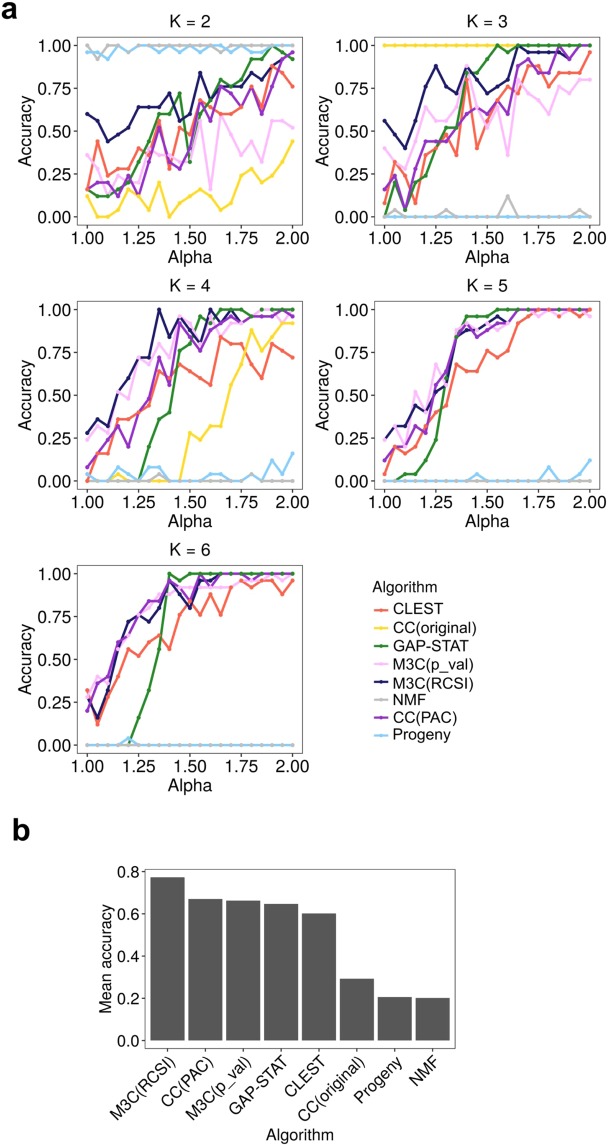
Genome-wide data is used to stratify patients into classes for precision medicine using clustering algorithms. A common problem in this area is selection of the number of clusters (K). The Monti consensus clustering algorithm is a widely used method which uses stability selection to estimate K. However, the method has bias towards higher values of K and yields high numbers of false positives. As a solution, we developed Monte Carlo reference-based consensus clustering (M3C), which is based on this algorithm. M3C simulates null distributions of stability scores for a range of K values thus enabling a comparison with real data to remove bias and statistically test for the presence of structure. M3C corrects the inherent bias of consensus clustering as demonstrated on simulated and real expression data from The Cancer Genome Atlas (TCGA). For testing M3C, we developed clusterlab, a new method for simulating multivariate Gaussian clusters.
Conflict of interest statement
The authors declare no competing interests.
Figures
References
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
