

Hands Holding Clues for Object Recognition in Teachable Machines
- PMID: 32043091
- PMCID: PMC7008716
- DOI: 10.1145/3290605.3300566
Hands Holding Clues for Object Recognition in Teachable Machines
Abstract
Camera manipulation confounds the use of object recognition applications by blind people. This is exacerbated when photos from this population are also used to train models, as with teachable machines, where out-of-frame or partially included objects against cluttered backgrounds degrade performance. Leveraging prior evidence on the ability of blind people to coordinate hand movements using proprioception, we propose a deep learning system that jointly models hand segmentation and object localization for object classification. We investigate the utility of hands as a natural interface for including and indicating the object of interest in the camera frame. We confirm the potential of this approach by analyzing existing datasets from people with visual impairments for object recognition. With a new publicly available egocentric dataset and an extensive error analysis, we provide insights into this approach in the context of teachable recognizers.
Keywords: blind; egocentric; hand; k-shot learning; object recognition.
Figures
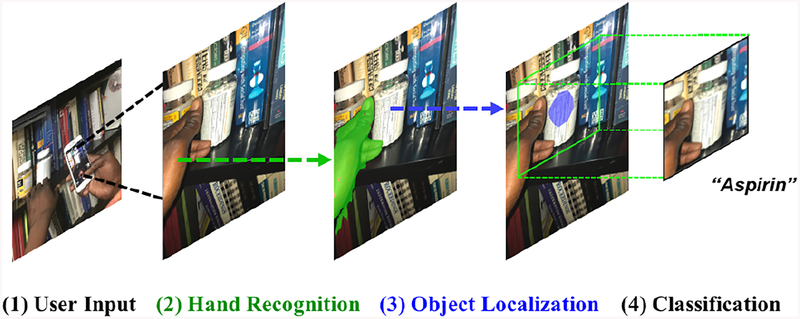
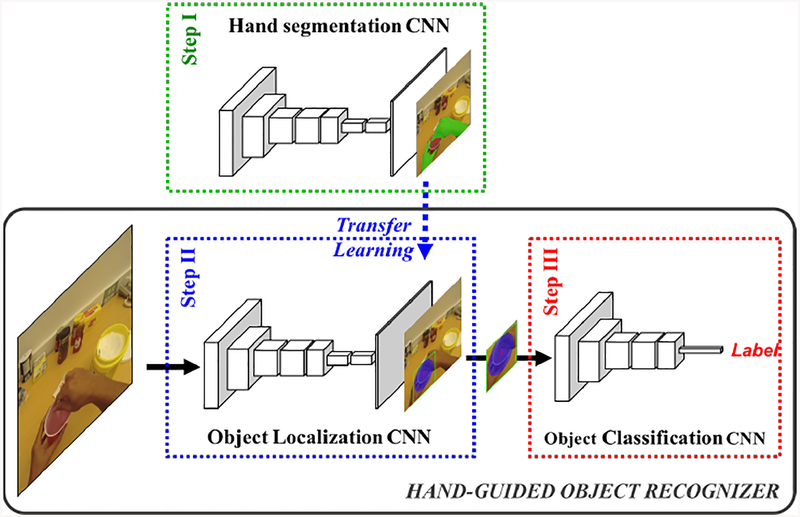



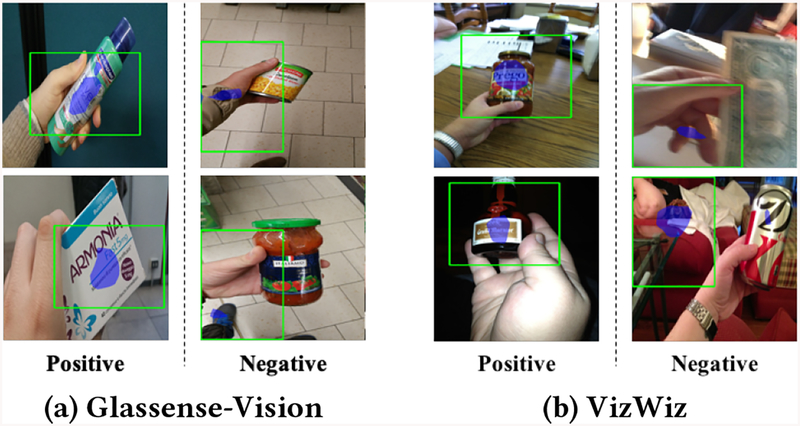
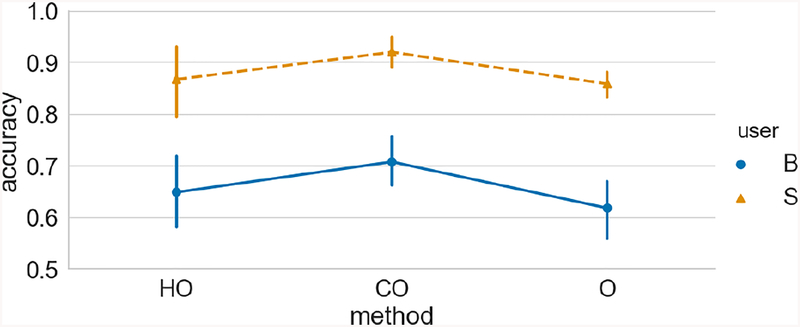

Similar articles
-
Revisiting Blind Photography in the Context of Teachable Object Recognizers.ASSETS. 2019 Oct;2019:83-95. doi: 10.1145/3308561.3353799. ASSETS. 2019. PMID: 32783045 Free PMC article.
-
Blind Users Accessing Their Training Images in Teachable Object Recognizers.ASSETS. 2022 Oct;2022:14. doi: 10.1145/3517428.3544824. Epub 2022 Oct 22. ASSETS. 2022. PMID: 36916963 Free PMC article.
-
Hand-Priming in Object Localization for Assistive Egocentric Vision.IEEE Winter Conf Appl Comput Vis. 2020 Mar;2020:3411-3421. doi: 10.1109/wacv45572.2020.9093353. Epub 2020 May 14. IEEE Winter Conf Appl Comput Vis. 2020. PMID: 32803098 Free PMC article.
-
Review of Learning-Based Robotic Manipulation in Cluttered Environments.Sensors (Basel). 2022 Oct 18;22(20):7938. doi: 10.3390/s22207938. Sensors (Basel). 2022. PMID: 36298284 Free PMC article. Review.
-
Analysis of the Hands in Egocentric Vision: A Survey.IEEE Trans Pattern Anal Mach Intell. 2023 Jun;45(6):6846-6866. doi: 10.1109/TPAMI.2020.2986648. Epub 2023 May 5. IEEE Trans Pattern Anal Mach Intell. 2023. PMID: 32286958 Review.
Cited by
-
AccessShare: Co-designing Data Access and Sharing with Blind People.ASSETS. 2024;4:1-16. doi: 10.1145/3663548.3675612. ASSETS. 2024. PMID: 40568023 Free PMC article.
-
Sharing Practices for Datasets Related to Accessibility and Aging.ASSETS. 2021;1:10.1145/3441852.3471208. doi: 10.1145/3441852.3471208. ASSETS. 2021. PMID: 35187541 Free PMC article.
-
Revisiting Blind Photography in the Context of Teachable Object Recognizers.ASSETS. 2019 Oct;2019:83-95. doi: 10.1145/3308561.3353799. ASSETS. 2019. PMID: 32783045 Free PMC article.
-
Blind Users Accessing Their Training Images in Teachable Object Recognizers.ASSETS. 2022 Oct;2022:14. doi: 10.1145/3517428.3544824. Epub 2022 Oct 22. ASSETS. 2022. PMID: 36916963 Free PMC article.
-
Accessing Passersby Proxemic Signals through a Head-Worn Camera: Opportunities and Limitations for the Blind.ASSETS. 2021;21:10.1145/3441852.3471232. doi: 10.1145/3441852.3471232. ASSETS. 2021. PMID: 35187543 Free PMC article.
References
-
- Adams Dustin, Kurniawan Sri, Herrera Cynthia, Kang Veronica, and Friedman Natalie. 2016. Blind photographers and VizSnap: A long-term study. In Proceedings of the 18th International ACM SIGACCESS Conference on Computers and Accessibility. ACM, 201–208.
-
- Adams Dustin, Morales Lourdes, and Kurniawan Sri. 2013. A qualitative study to support a blind photography mobile application. In Proceedings of the 6th International Conference on PErvasive Technologies Related to Assistive Environments. ACM, 25.
-
- Ahmed Tousif, Hoyle Roberto, Connelly Kay, Crandall David, and Kapadia Apu. 2015. Privacy concerns and behaviors of people with visual impairments. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems. ACM, 3523–3532.
-
- Envision AI. 2018. Enabling vision for the blind. https://www.letsenvision.com
-
- Seeing AI. 2017. A free app that narrates the world around you. https://www.microsoft.com/en-us/seeing-ai
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources