

DTranNER: biomedical named entity recognition with deep learning-based label-label transition model
- PMID: 32046638
- PMCID: PMC7014657
- DOI: 10.1186/s12859-020-3393-1
DTranNER: biomedical named entity recognition with deep learning-based label-label transition model
Abstract
Background: Biomedical named-entity recognition (BioNER) is widely modeled with conditional random fields (CRF) by regarding it as a sequence labeling problem. The CRF-based methods yield structured outputs of labels by imposing connectivity between the labels. Recent studies for BioNER have reported state-of-the-art performance by combining deep learning-based models (e.g., bidirectional Long Short-Term Memory) and CRF. The deep learning-based models in the CRF-based methods are dedicated to estimating individual labels, whereas the relationships between connected labels are described as static numbers; thereby, it is not allowed to timely reflect the context in generating the most plausible label-label transitions for a given input sentence. Regardless, correctly segmenting entity mentions in biomedical texts is challenging because the biomedical terms are often descriptive and long compared with general terms. Therefore, limiting the label-label transitions as static numbers is a bottleneck in the performance improvement of BioNER.
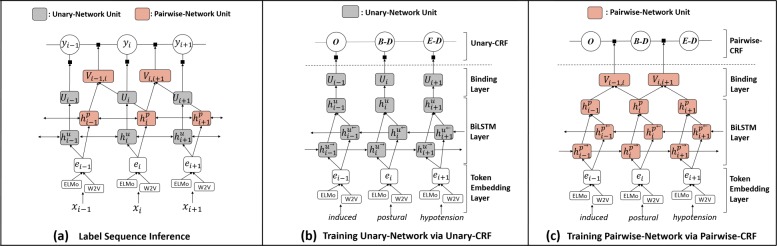
Results: We introduce DTranNER, a novel CRF-based framework incorporating a deep learning-based label-label transition model into BioNER. DTranNER uses two separate deep learning-based networks: Unary-Network and Pairwise-Network. The former is to model the input for determining individual labels, and the latter is to explore the context of the input for describing the label-label transitions. We performed experiments on five benchmark BioNER corpora. Compared with current state-of-the-art methods, DTranNER achieves the best F1-score of 84.56% beyond 84.40% on the BioCreative II gene mention (BC2GM) corpus, the best F1-score of 91.99% beyond 91.41% on the BioCreative IV chemical and drug (BC4CHEMD) corpus, the best F1-score of 94.16% beyond 93.44% on the chemical NER, the best F1-score of 87.22% beyond 86.56% on the disease NER of the BioCreative V chemical disease relation (BC5CDR) corpus, and a near-best F1-score of 88.62% on the NCBI-Disease corpus.
Conclusions: Our results indicate that the incorporation of the deep learning-based label-label transition model provides distinctive contextual clues to enhance BioNER over the static transition model. We demonstrate that the proposed framework enables the dynamic transition model to adaptively explore the contextual relations between adjacent labels in a fine-grained way. We expect that our study can be a stepping stone for further prosperity of biomedical literature mining.
Keywords: Bioinformatics; Data mining; Named entity recognition; Neural network.
Conflict of interest statement
The authors declare that they have no competing interests.
Figures
Similar articles
-
Biomedical named entity recognition using deep neural networks with contextual information.BMC Bioinformatics. 2019 Dec 27;20(1):735. doi: 10.1186/s12859-019-3321-4. BMC Bioinformatics. 2019. PMID: 31881938 Free PMC article.
-
Biomedical named entity recognition using BERT in the machine reading comprehension framework.J Biomed Inform. 2021 Jun;118:103799. doi: 10.1016/j.jbi.2021.103799. Epub 2021 May 6. J Biomed Inform. 2021. PMID: 33965638
-
BioByGANS: biomedical named entity recognition by fusing contextual and syntactic features through graph attention network in node classification framework.BMC Bioinformatics. 2022 Nov 22;23(1):501. doi: 10.1186/s12859-022-05051-9. BMC Bioinformatics. 2022. PMID: 36418937 Free PMC article.
-
Unsupervised and self-supervised deep learning approaches for biomedical text mining.Brief Bioinform. 2021 Mar 22;22(2):1592-1603. doi: 10.1093/bib/bbab016. Brief Bioinform. 2021. PMID: 33569575 Review.
-
Evaluation of a prototype machine learning tool to semi-automate data extraction for systematic literature reviews.Syst Rev. 2023 Oct 6;12(1):187. doi: 10.1186/s13643-023-02351-w. Syst Rev. 2023. PMID: 37803451 Free PMC article.
Cited by
-
Chinese Clinical Named Entity Recognition with ALBERT and MHA Mechanism.Evid Based Complement Alternat Med. 2022 May 23;2022:2056039. doi: 10.1155/2022/2056039. eCollection 2022. Evid Based Complement Alternat Med. 2022. PMID: 35656458 Free PMC article.
-
Do LLMs Surpass Encoders for Biomedical NER?Proc (IEEE Int Conf Healthc Inform). 2025 Jun;2025:352-358. doi: 10.1109/ICHI64645.2025.00048. Epub 2025 Jul 22. Proc (IEEE Int Conf Healthc Inform). 2025. PMID: 40787150 Free PMC article.
-
Parallel sequence tagging for concept recognition.BMC Bioinformatics. 2022 Mar 24;22(Suppl 1):623. doi: 10.1186/s12859-021-04511-y. BMC Bioinformatics. 2022. PMID: 35331131 Free PMC article.
-
A BERT-based ensemble learning approach for the BioCreative VII challenges: full-text chemical identification and multi-label classification in PubMed articles.Database (Oxford). 2022 Jul 15;2022:baac056. doi: 10.1093/database/baac056. Database (Oxford). 2022. PMID: 35849027 Free PMC article.
-
A pre-training and self-training approach for biomedical named entity recognition.PLoS One. 2021 Feb 9;16(2):e0246310. doi: 10.1371/journal.pone.0246310. eCollection 2021. PLoS One. 2021. PMID: 33561139 Free PMC article.
References
-
- Lafferty J, McCallum A, Pereira FC. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In: Proceedings of the 18th International Conference on Machine Learning. ACM: 2001. p. 282–9. http://portal.acm.org/citation.cfm?id=655813.
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
