

Artificial Intelligence for MR Image Reconstruction: An Overview for Clinicians
- PMID: 32048372
- PMCID: PMC7423636
- DOI: 10.1002/jmri.27078
Artificial Intelligence for MR Image Reconstruction: An Overview for Clinicians
Abstract
Artificial intelligence (AI) shows tremendous promise in the field of medical imaging, with recent breakthroughs applying deep-learning models for data acquisition, classification problems, segmentation, image synthesis, and image reconstruction. With an eye towards clinical applications, we summarize the active field of deep-learning-based MR image reconstruction. We review the basic concepts of how deep-learning algorithms aid in the transformation of raw k-space data to image data, and specifically examine accelerated imaging and artifact suppression. Recent efforts in these areas show that deep-learning-based algorithms can match and, in some cases, eclipse conventional reconstruction methods in terms of image quality and computational efficiency across a host of clinical imaging applications, including musculoskeletal, abdominal, cardiac, and brain imaging. This article is an introductory overview aimed at clinical radiologists with no experience in deep-learning-based MR image reconstruction and should enable them to understand the basic concepts and current clinical applications of this rapidly growing area of research across multiple organ systems.
Keywords: MRI; deep learning; image reconstruction.
© 2020 International Society for Magnetic Resonance in Medicine.
Figures
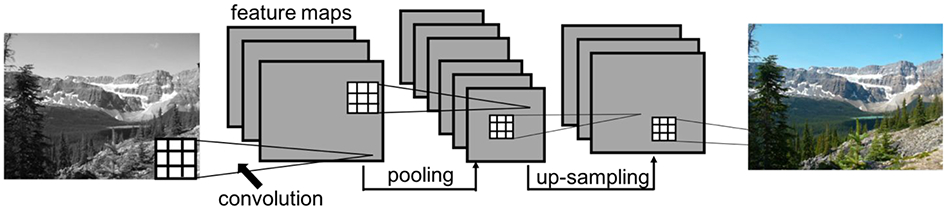
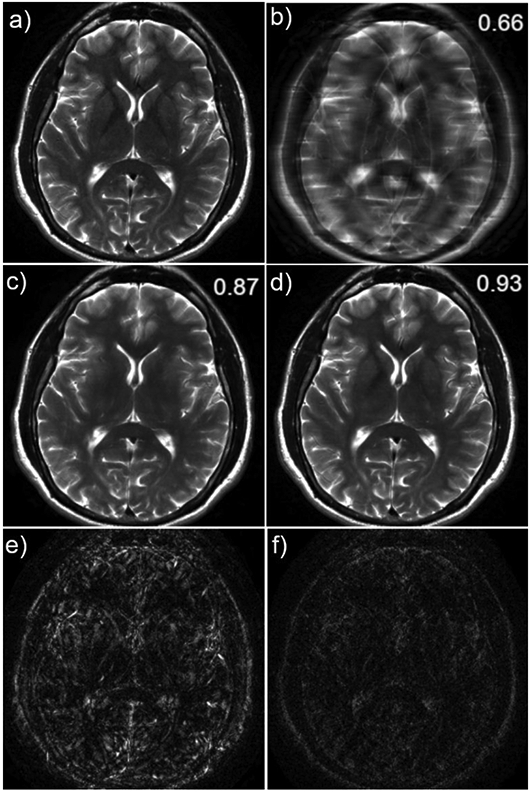
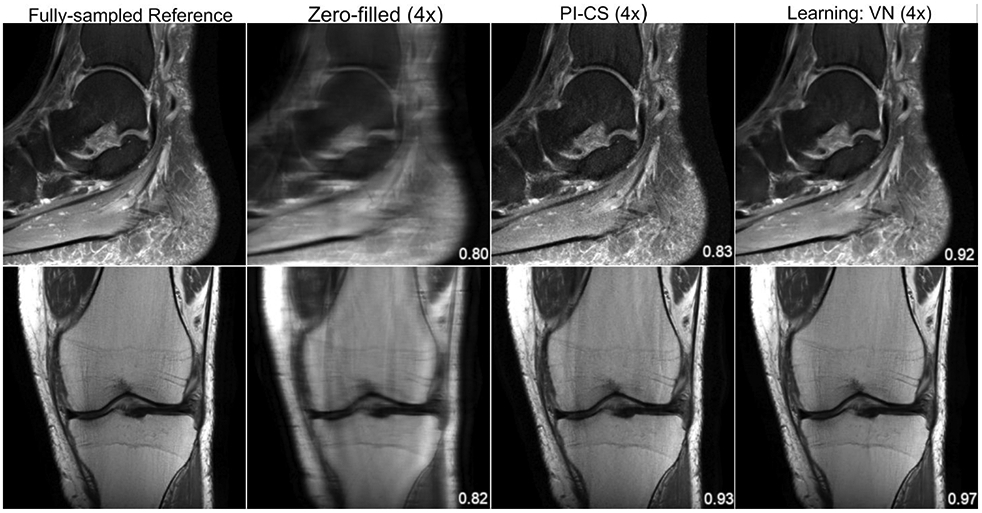
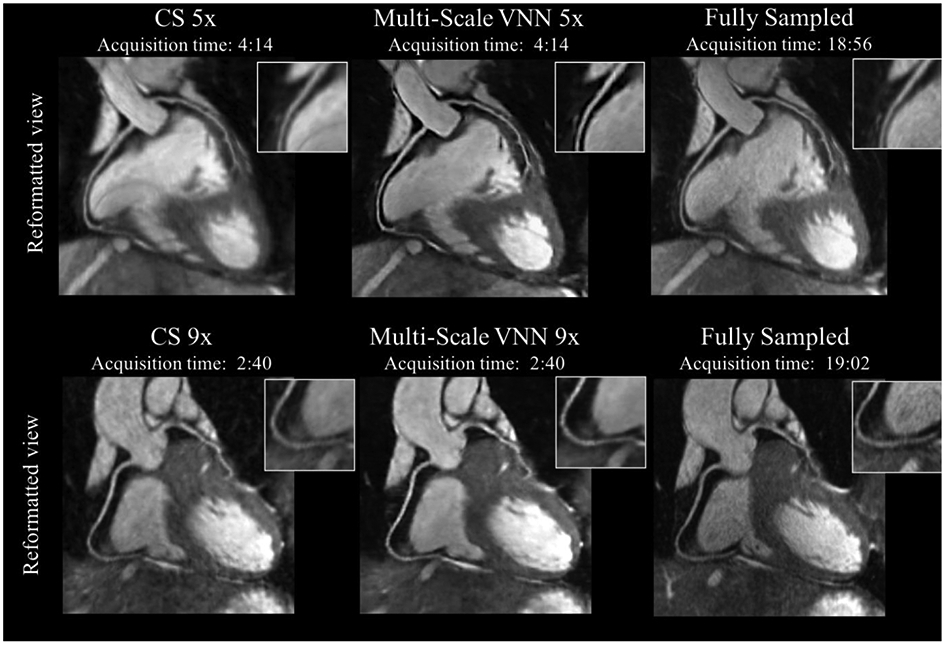
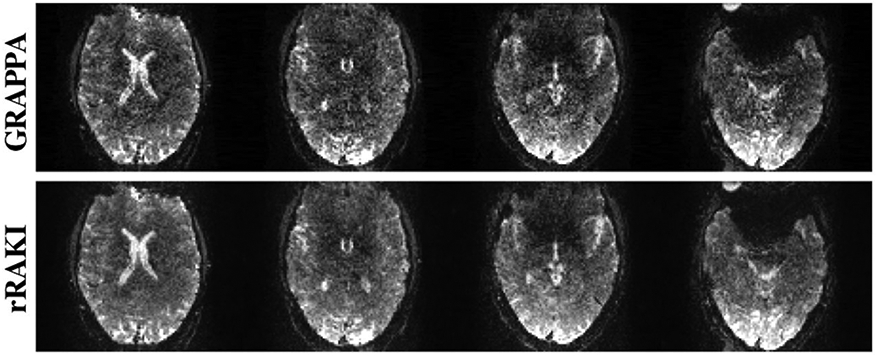
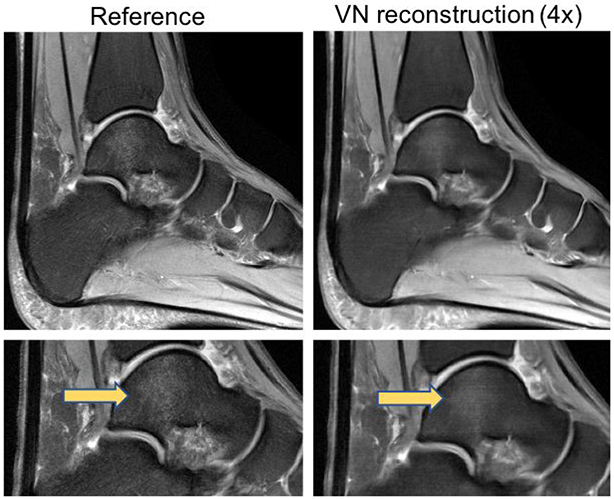
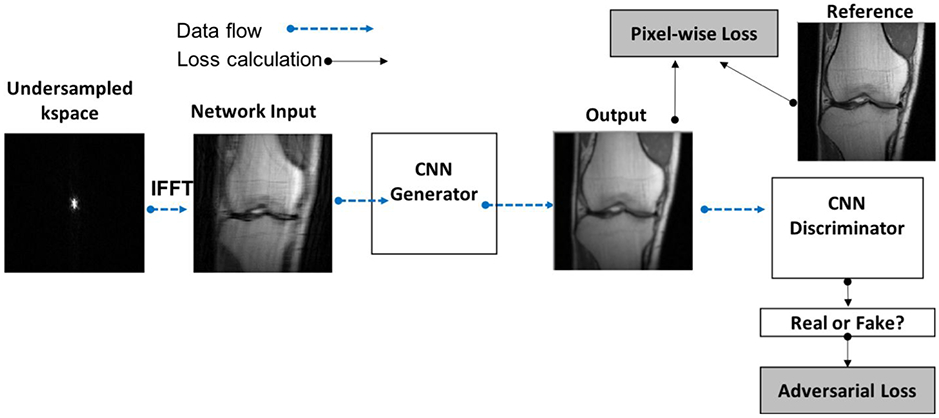
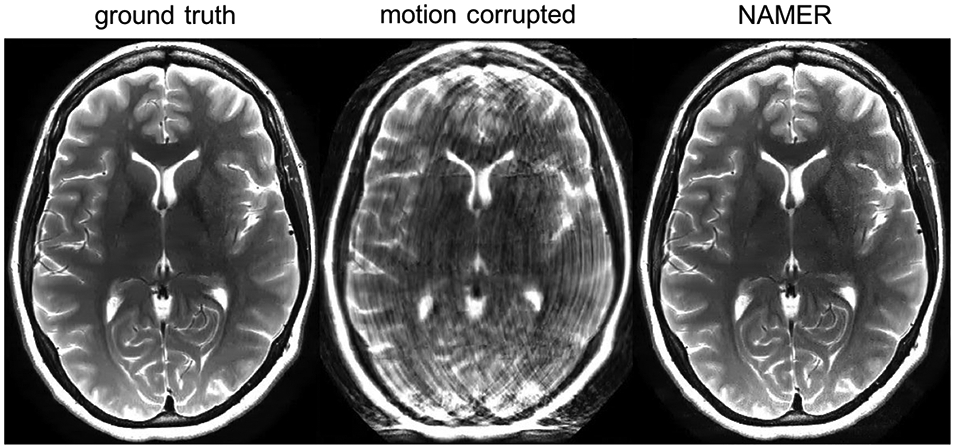
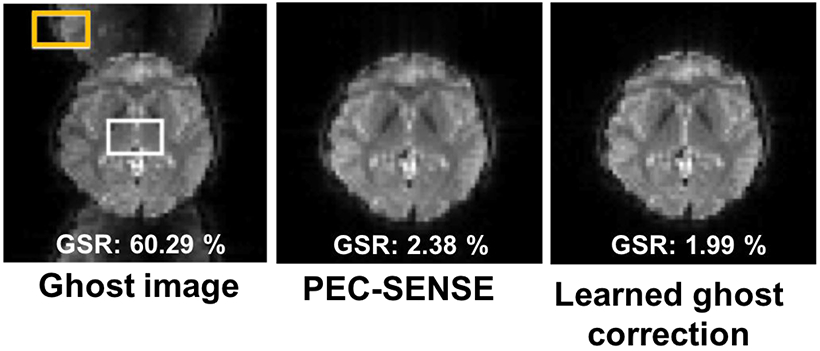
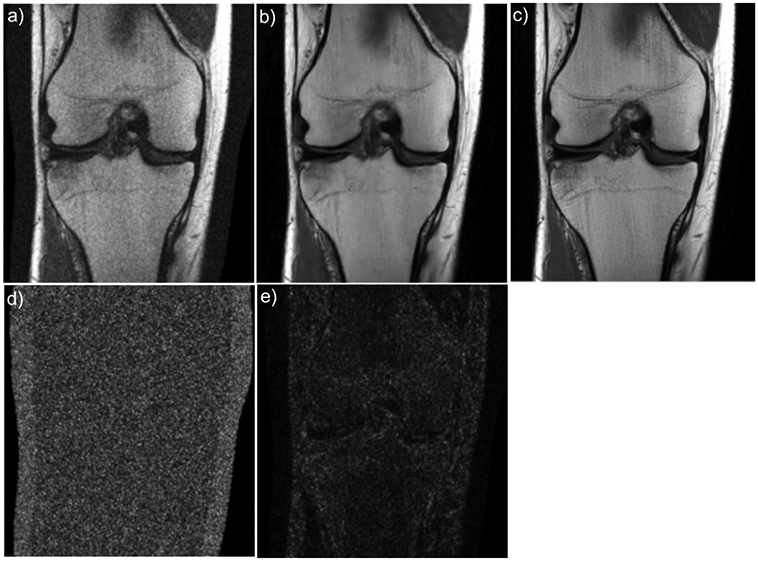
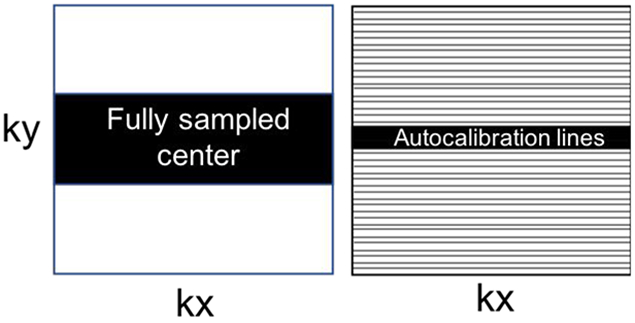
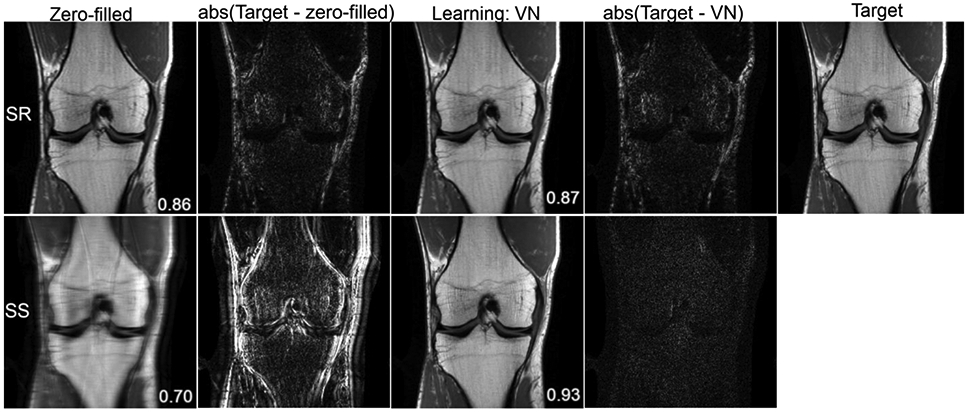
References
-
- Chan HP, Doi K, Galhotra S, Vyborny CJ, MacMahon H, Jokich PM. Image feature analysis and computer-aided diagnosis in digital radiography. I. Automated detection of microcalcifications in mammography. Med Phys 1987;14(4):538–548. - PubMed
-
- MacMahon H, Doi K, Chan HP, Giger ML, Katsuragawa S, Nakamori N. Computer-aided diagnosis in chest radiology. J Thorac Imaging 1990;5(1):67–76. - PubMed
-
- McBee MP, Awan OA, Colucci AT, et al. Deep Learning in Radiology. Acad Radiol 2018;25(11):1472–1480. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
