

Overtone focusing in biphonic tuvan throat singing
- PMID: 32048990
- PMCID: PMC7064340
- DOI: 10.7554/eLife.50476
Overtone focusing in biphonic tuvan throat singing
Abstract
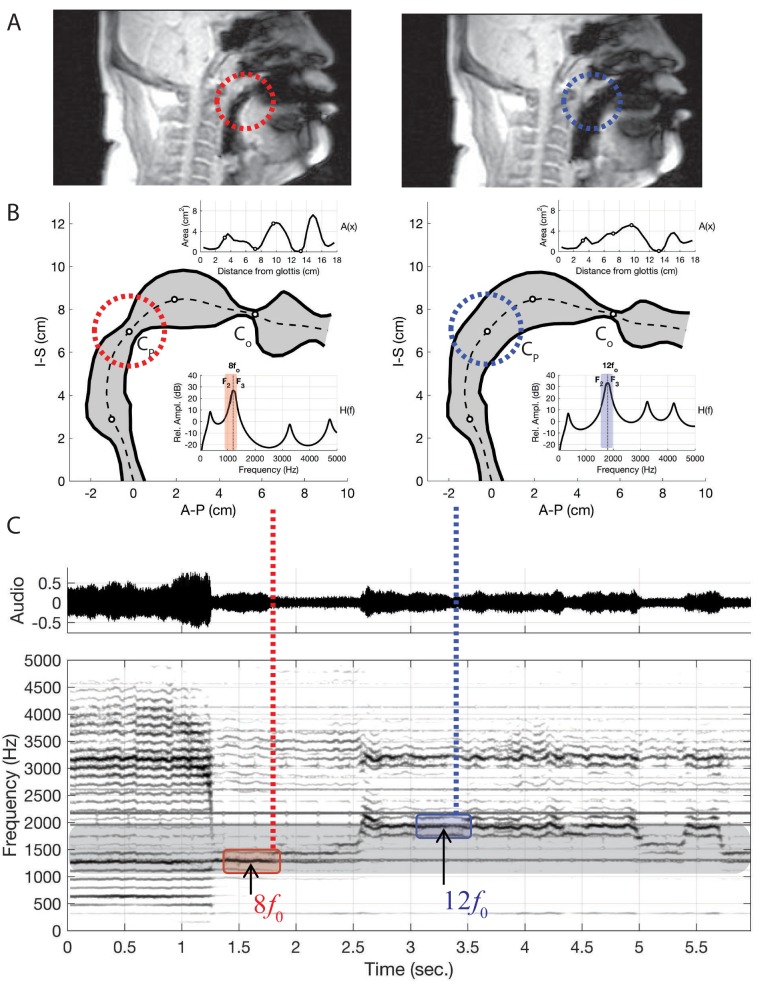
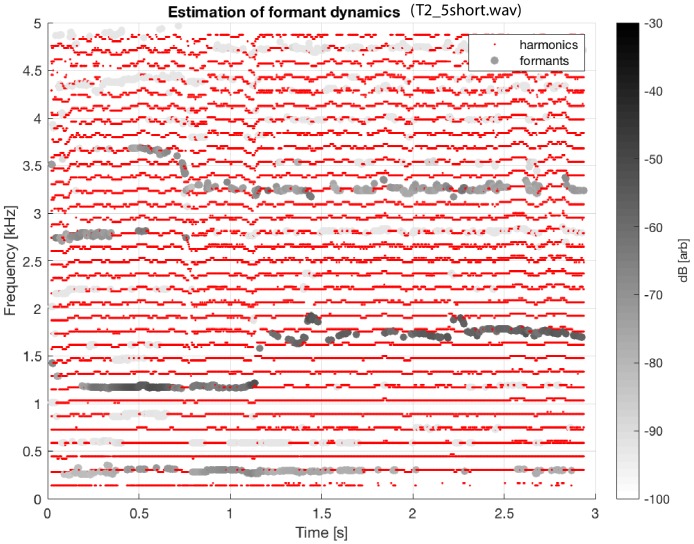
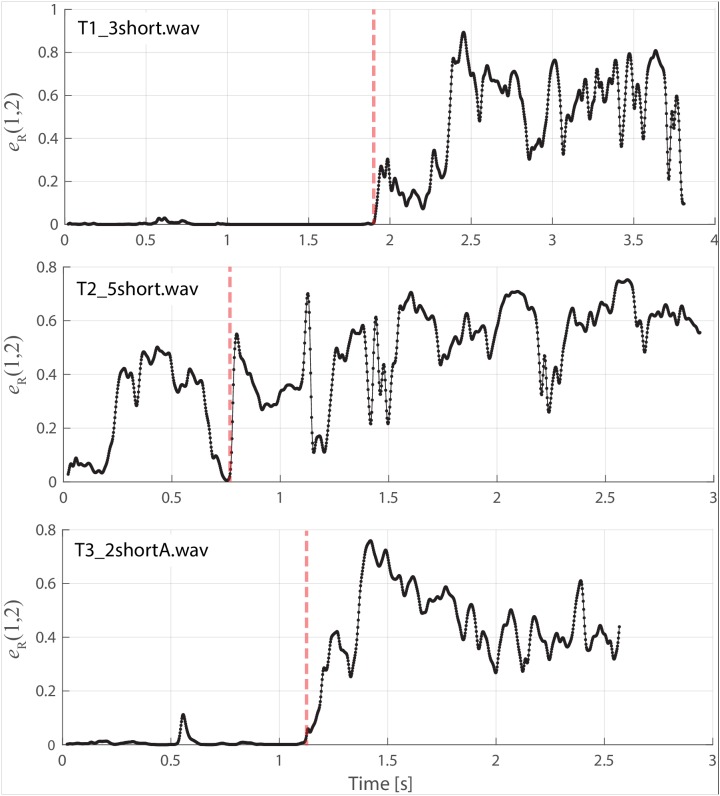
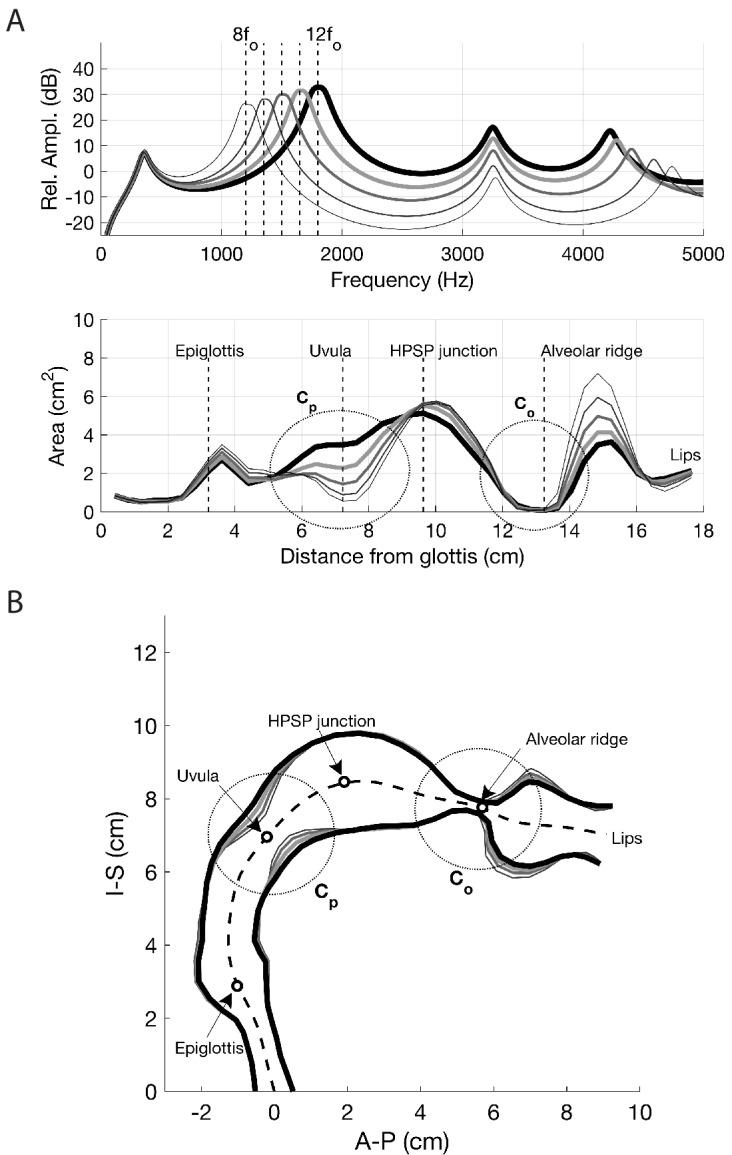
Khoomei is a unique singing style originating from the republic of Tuva in central Asia. Singers produce two pitches simultaneously: a booming low-frequency rumble alongside a hovering high-pitched whistle-like tone. The biomechanics of this biphonation are not well-understood. Here, we use sound analysis, dynamic magnetic resonance imaging, and vocal tract modeling to demonstrate how biphonation is achieved by modulating vocal tract morphology. Tuvan singers show remarkable control in shaping their vocal tract to narrowly focus the harmonics (or overtones) emanating from their vocal cords. The biphonic sound is a combination of the fundamental pitch and a focused filter state, which is at the higher pitch (1-2 kHz) and formed by merging two formants, thereby greatly enhancing sound-production in a very narrow frequency range. Most importantly, we demonstrate that this biphonation is a phenomenon arising from linear filtering rather than from a nonlinear source.
Keywords: Tuvan throat singing; acoustic phonetics; biphonation; human; physics of living systems; speech biomechanics.
Plain language summary
The republic of Tuva, a remote territory in southern Russia located on the border with Mongolia, is perhaps best known for its vast mountainous geography and the unique cultural practice of “throat singing”. These singers simultaneously create two different pitches: a low-pitched drone, along with a hovering whistle above it. This practice has deep cultural roots and has now been shared more broadly via world music performances and the 1999 documentary Genghis Blues. Despite many scientists being fascinated by throat singing, it was unclear precisely how throat singers could create two unique pitches. Singing and speaking in general involves making sounds by vibrating the vocal cords found deep in the throat, and then shaping those sounds with the tongue, teeth and lips as they move up the vocal tract and out of the body. Previous studies using static images taken with magnetic resonance imaging (MRI) suggested how Tuvan singers might produce the two pitches, but a mechanistic understanding of throat singing was far from complete. Now, Bergevin et al. have better pinpointed how throat singers can produce their unique sound. The analysis involved high quality audio recordings of three Tuvan singers and dynamic MRI recordings of the movements of one of those singers. The images showed changes in the singer’s vocal tract as they sang inside an MRI scanner, providing key information needed to create a computer model of the process. This approach revealed that Tuvan singers can create two pitches simultaneously by forming precise constrictions in their vocal tract. One key constriction occurs when tip of the tongue nearly touches a ridge on the roof of the mouth, and a second constriction is formed by the base of the tongue. The computer model helped explain that these two constrictions produce the distinctive sounds of throat singing by selectively amplifying a narrow set of high frequency notes that are made by the vocal cords. Together these discoveries show how very small, targeted movements of the tongue can produce distinctive sounds.
© 2020, Bergevin et al.
Conflict of interest statement
CB, CN, JW, NM, JS, JB, BS No competing interests declared
Figures





















Comment in
-
Shaping new sounds.Elife. 2020 Feb 12;9:e55749. doi: 10.7554/eLife.55749. Elife. 2020. PMID: 32048994 Free PMC article.
References
-
- Aksenov AN. Tuvin folk music. Asian Music. 1973;4:7–18. doi: 10.2307/833827. - DOI
Publication types
MeSH terms
Associated data
LinkOut - more resources
Full Text Sources
Other Literature Sources
