

Inference-Based Decisions in a Hidden State Foraging Task: Differential Contributions of Prefrontal Cortical Areas
- PMID: 32048995
- PMCID: PMC7146546
- DOI: 10.1016/j.neuron.2020.01.017
Inference-Based Decisions in a Hidden State Foraging Task: Differential Contributions of Prefrontal Cortical Areas
Abstract
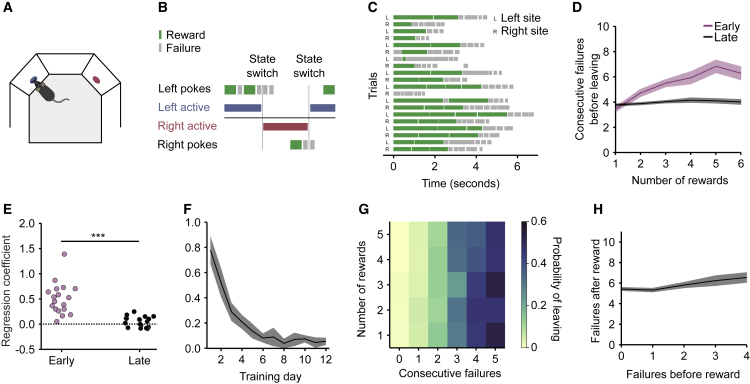
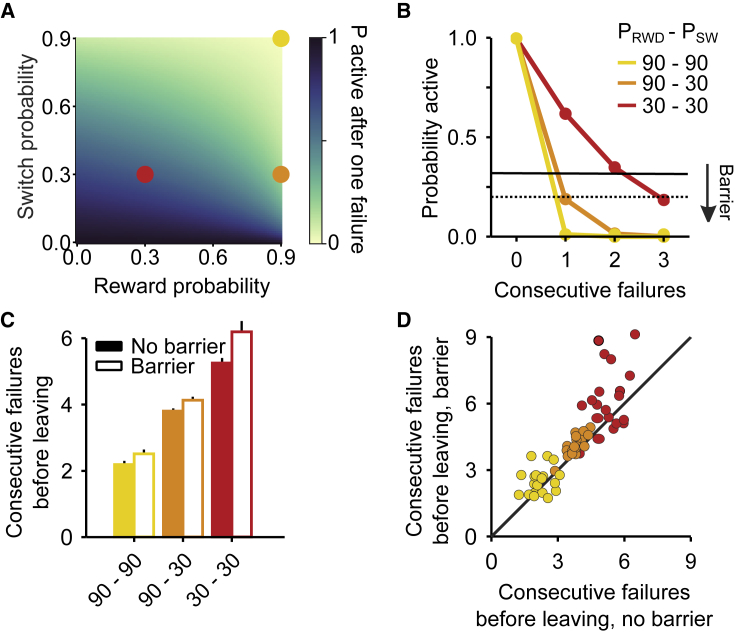
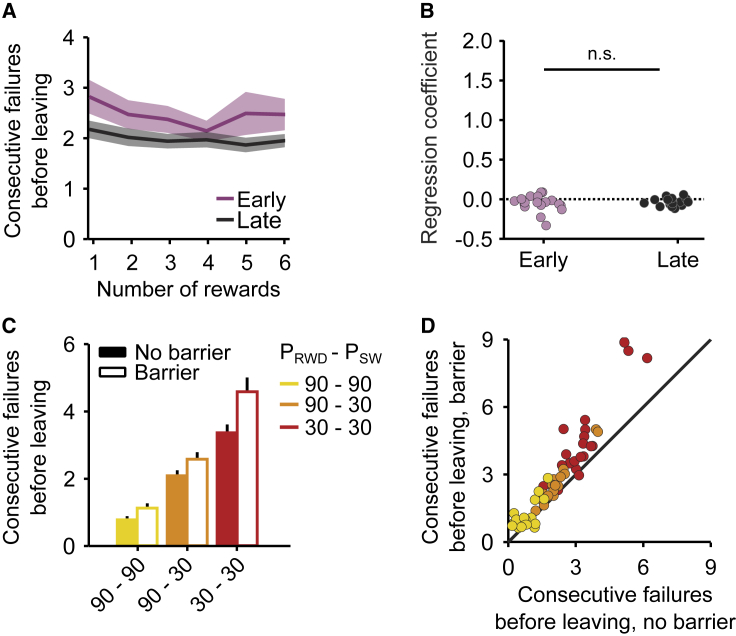
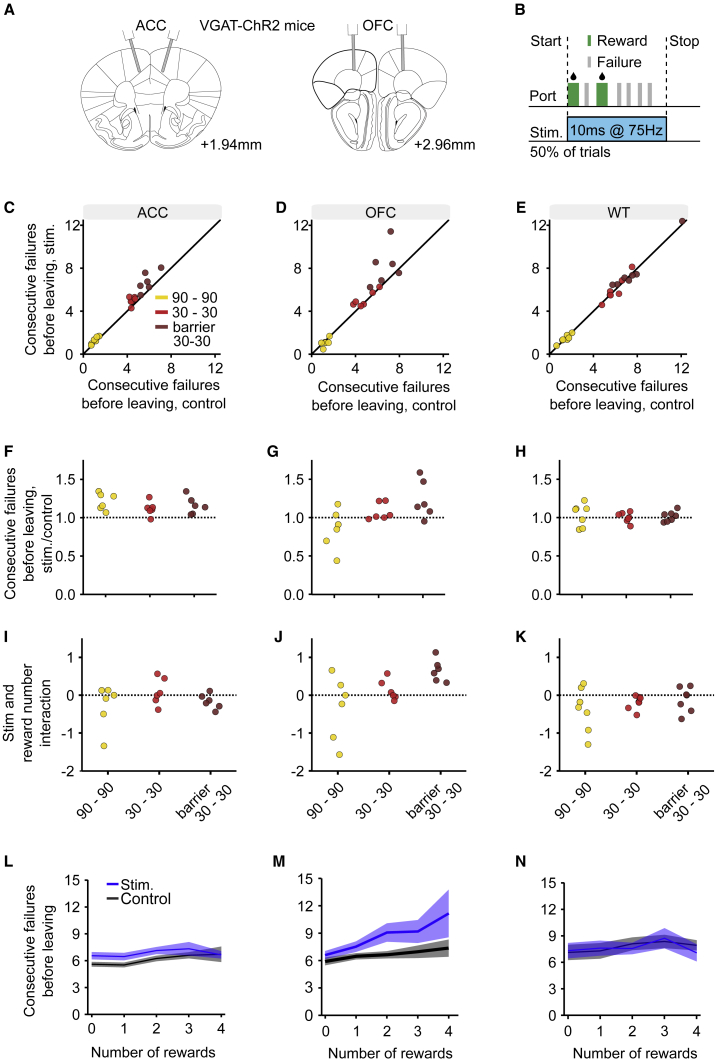
Essential features of the world are often hidden and must be inferred by constructing internal models based on indirect evidence. Here, to study the mechanisms of inference, we establish a foraging task that is naturalistic and easily learned yet can distinguish inference from simpler strategies such as the direct integration of sensory data. We show that both mice and humans learn a strategy consistent with optimal inference of a hidden state. However, humans acquire this strategy more than an order of magnitude faster than mice. Using optogenetics in mice, we show that orbitofrontal and anterior cingulate cortex inactivation impacts task performance, but only orbitofrontal inactivation reverts mice from an inference-based to a stimulus-bound decision strategy. These results establish a cross-species paradigm for studying the problem of inference-based decision making and begins to dissect the network of brain regions crucial for its performance.
Keywords: PFC; cross-species task; foraging; inference; state representation.
Copyright © 2020 The Authors. Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
Declaration of interests The authors declare no competing interests.
Figures

References
-
- Bezanson J., Edelman A., Karpinski S., Shah V. Julia: A Fresh Approach to Numerical Computing. SIAM Rev. 2017;59:65–98.
-
- Boyen X., Friedman N., Koller D. Discovering the Hidden Structure of Complex Dynamic Systems. arXiv. 1999 https://arxiv.org/abs/1301.6683 arXiv:1301.6683.
-
- Brunton B.W., Botvinick M.M., Brody C.D. Rats and humans can optimally accumulate evidence for decision-making. Science. 2013;340:95–98. - PubMed
-
- Charnov E.L. Optimal foraging, the marginal value theorem. Theor. Popul. Biol. 1976;9:129–136. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
Miscellaneous
