

Understanding Computational Costs of Cellular-Level Brain Tissue Simulations Through Analytical Performance Models
- PMID: 32056104
- PMCID: PMC7338826
- DOI: 10.1007/s12021-019-09451-w
Understanding Computational Costs of Cellular-Level Brain Tissue Simulations Through Analytical Performance Models
Abstract
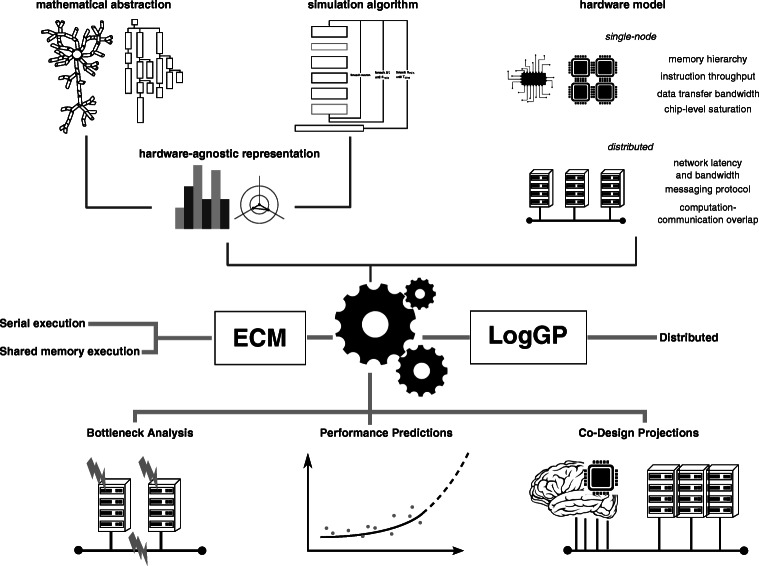
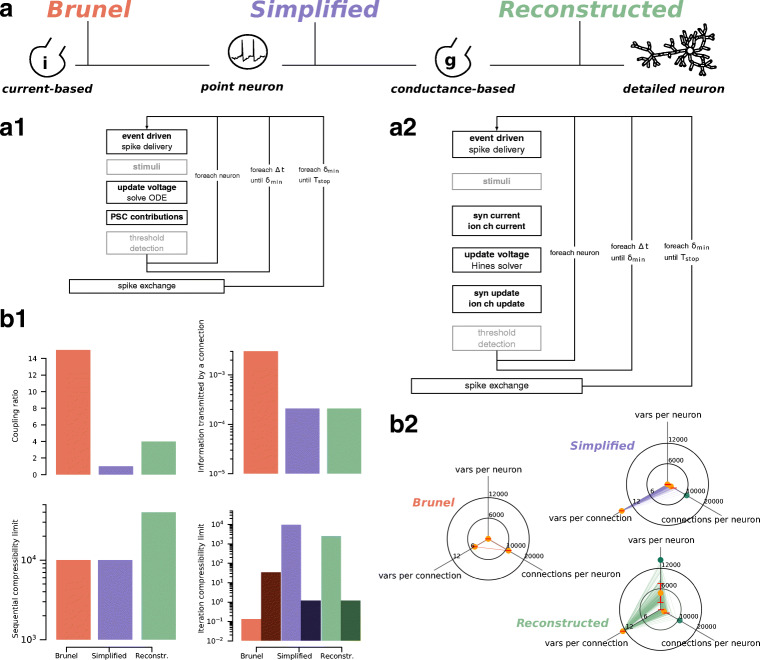
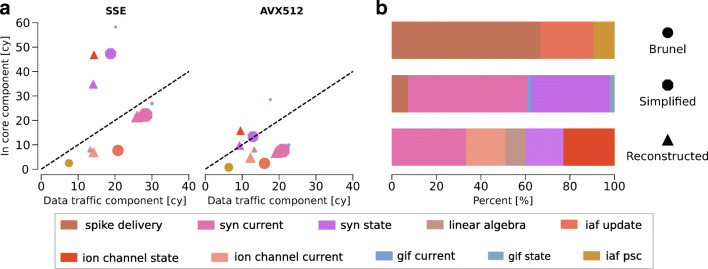
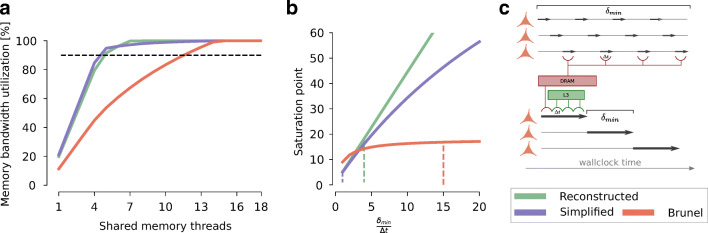
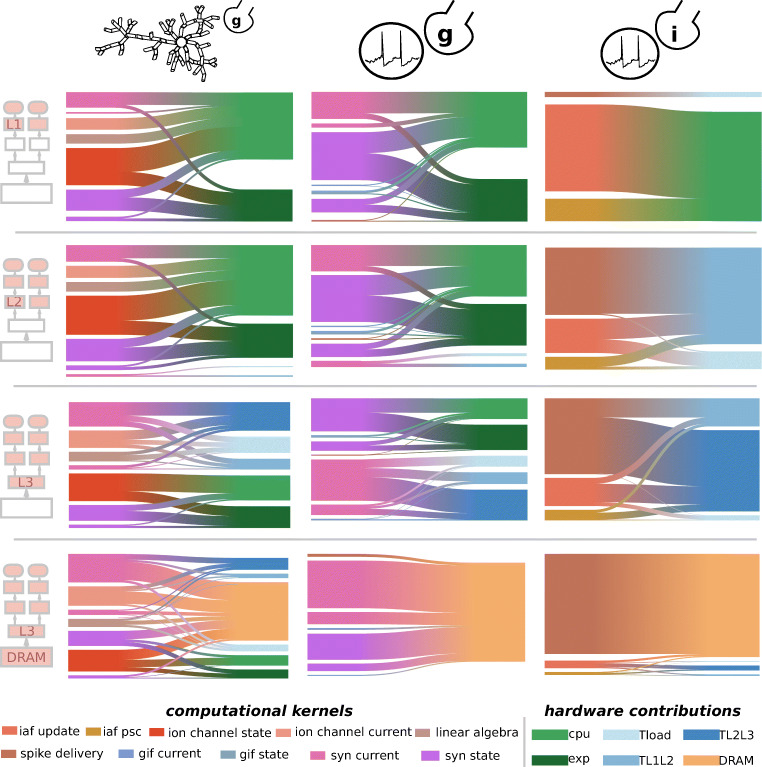
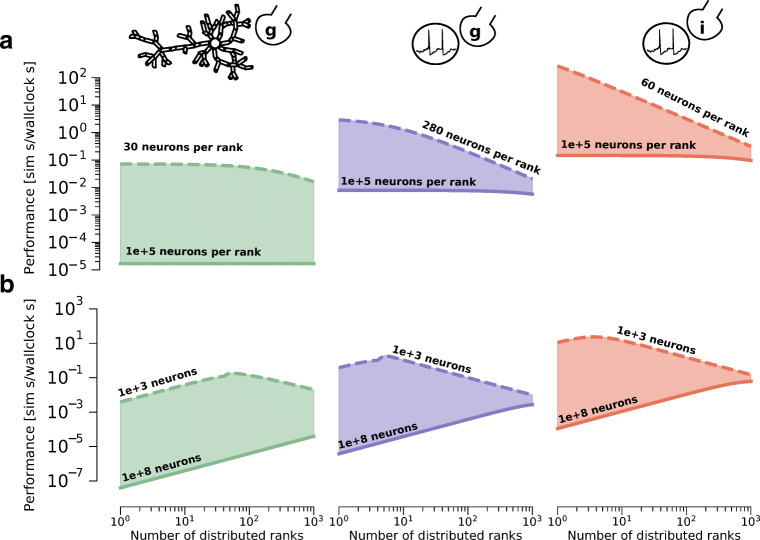
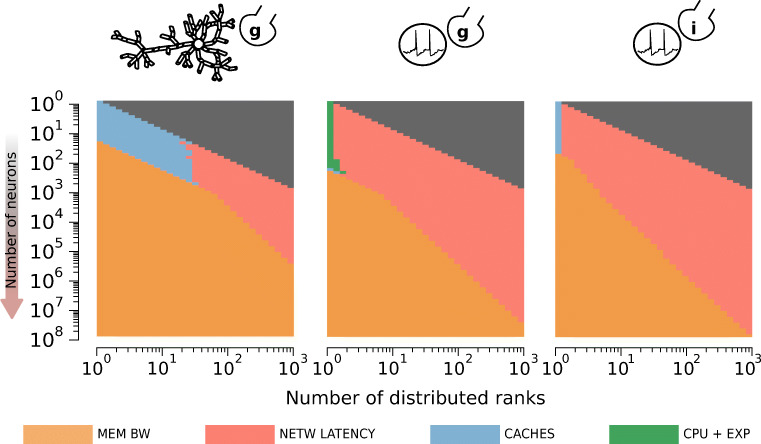
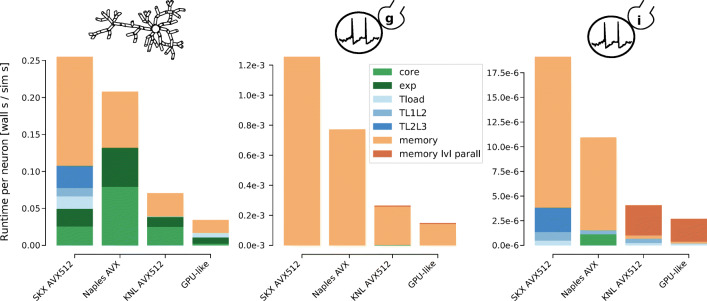
Computational modeling and simulation have become essential tools in the quest to better understand the brain's makeup and to decipher the causal interrelations of its components. The breadth of biochemical and biophysical processes and structures in the brain has led to the development of a large variety of model abstractions and specialized tools, often times requiring high performance computing resources for their timely execution. What has been missing so far was an in-depth analysis of the complexity of the computational kernels, hindering a systematic approach to identifying bottlenecks of algorithms and hardware. If whole brain models are to be achieved on emerging computer generations, models and simulation engines will have to be carefully co-designed for the intrinsic hardware tradeoffs. For the first time, we present a systematic exploration based on analytic performance modeling. We base our analysis on three in silico models, chosen as representative examples of the most widely employed modeling abstractions: current-based point neurons, conductance-based point neurons and conductance-based detailed neurons. We identify that the synaptic modeling formalism, i.e. current or conductance-based representation, and not the level of morphological detail, is the most significant factor in determining the properties of memory bandwidth saturation and shared-memory scaling of in silico models. Even though general purpose computing has, until now, largely been able to deliver high performance, we find that for all types of abstractions, network latency and memory bandwidth will become severe bottlenecks as the number of neurons to be simulated grows. By adapting and extending a performance modeling approach, we deliver a first characterization of the performance landscape of brain tissue simulations, allowing us to pinpoint current bottlenecks for state-of-the-art in silico models, and make projections for future hardware and software requirements.
Keywords: Brain tissue simulations; Computational models of neurons; High performance computing; Performance modeling.
Figures
References
-
- Aamir, S.A., Stradmann, Y., Müller, P., Pehle, C., Hartel, A., Grübl, A., Schemmel, J., Meier, K. (2018). An accelerated lif neuronal network array for a large-scale mixed-signal neuromorphic architecture. IEEE Transactions on Circuits and Systems I: Regular Papers (99), 1–14. 10.1109/tcsi.2018.2840718.
-
- Akar, N.A., Cumming, B., Karakasis, V., Küsters, A., Klijn, W., Peyser, A., Yates, S. (2019). Arbor: a morphologically-detailed neural network simulation library for contemporary high-performance computing architectures. In 2019 27th euromicro international conference on parallel, distributed and network-based processing (PDP) (pp. 274–282): IEEE, 10.1109/empdp.2019.8671560
-
- Alexandrov A, Ionescu MF, Schauser KE, Scheiman C. Loggp: Incorporating long messages into the logp model for parallel computation. Journal of Parallel and Distributed Computing. 1997;44(1):71–79. doi: 10.1006/jpdc.1997.1346. - DOI
-
- Ananthanarayanan, R., & Modha, D.S. (2007). Anatomy of a cortical simulator. In Proceedings of the 2007 ACM/IEEE conference on Supercomputing (p. 3): ACM, 10.1145/1362622.1362627
-
- Ananthanarayanan, R., Esser, S.K., Simon, H.D., Modha, D.S. (2009). The cat is out of the bag: cortical simulations with 10 9 neurons, 10 13 synapses. In Proceedings of the conference on high performance computing networking, storage and analysis (p. 63): ACM.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
