

Expert-augmented machine learning
- PMID: 32071251
- PMCID: PMC7060733
- DOI: 10.1073/pnas.1906831117
Expert-augmented machine learning
Abstract
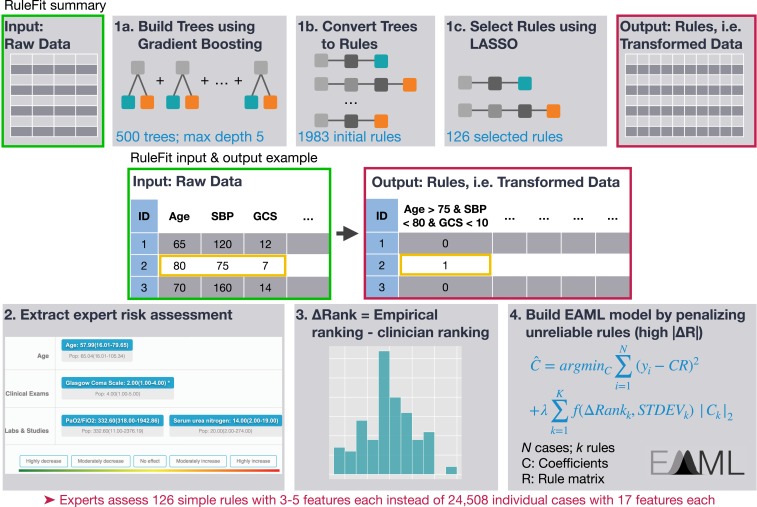
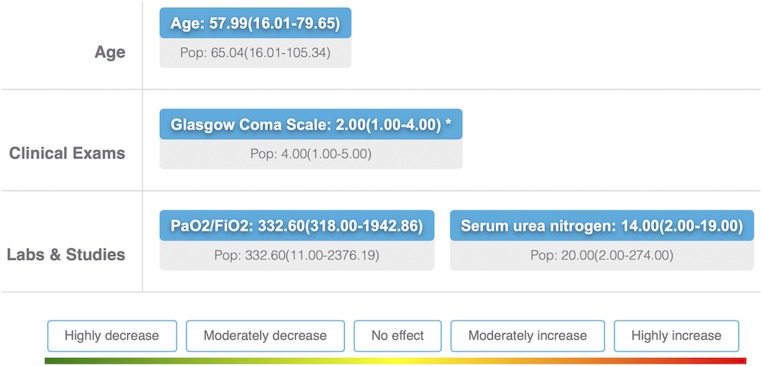
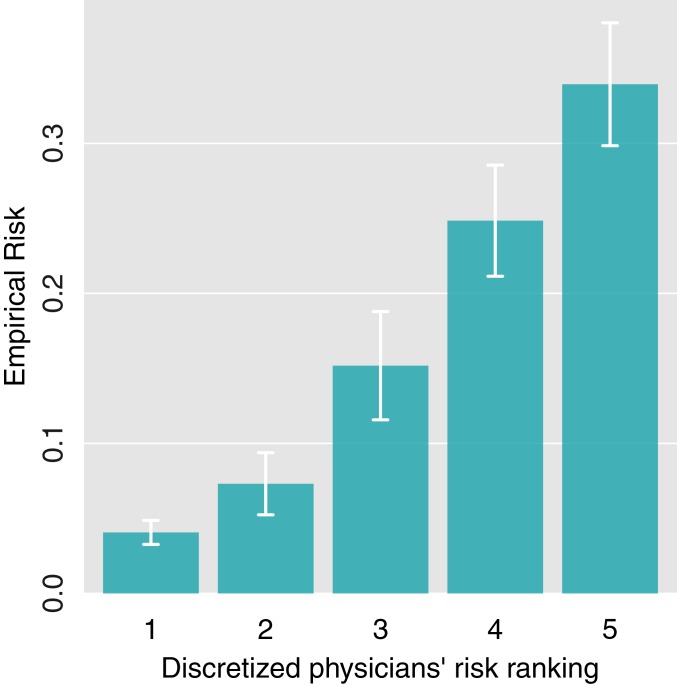
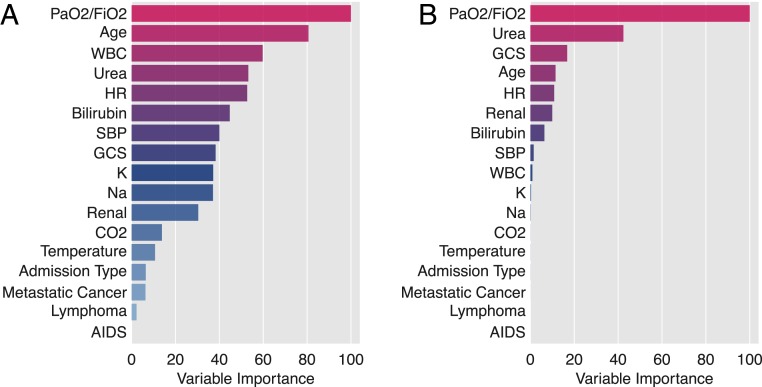
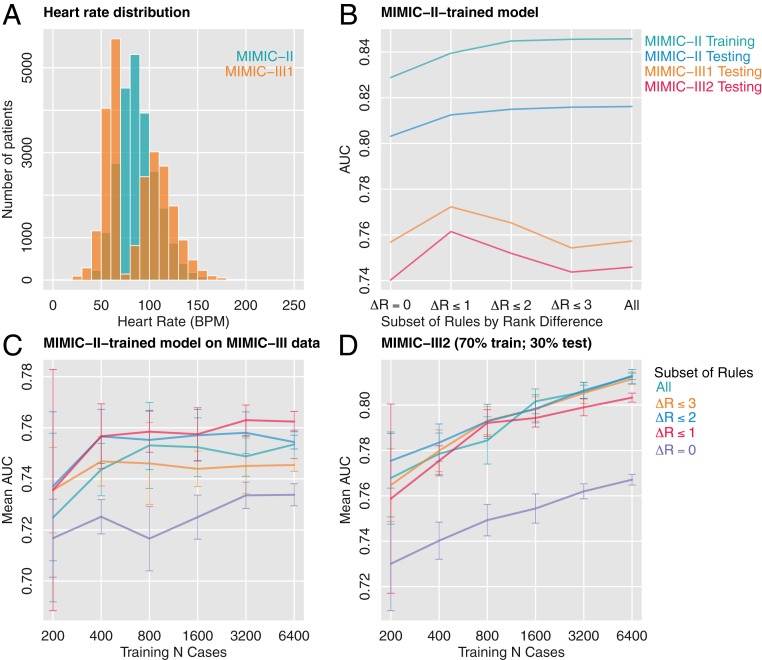
Machine learning is proving invaluable across disciplines. However, its success is often limited by the quality and quantity of available data, while its adoption is limited by the level of trust afforded by given models. Human vs. machine performance is commonly compared empirically to decide whether a certain task should be performed by a computer or an expert. In reality, the optimal learning strategy may involve combining the complementary strengths of humans and machines. Here, we present expert-augmented machine learning (EAML), an automated method that guides the extraction of expert knowledge and its integration into machine-learned models. We used a large dataset of intensive-care patient data to derive 126 decision rules that predict hospital mortality. Using an online platform, we asked 15 clinicians to assess the relative risk of the subpopulation defined by each rule compared to the total sample. We compared the clinician-assessed risk to the empirical risk and found that, while clinicians agreed with the data in most cases, there were notable exceptions where they overestimated or underestimated the true risk. Studying the rules with greatest disagreement, we identified problems with the training data, including one miscoded variable and one hidden confounder. Filtering the rules based on the extent of disagreement between clinician-assessed risk and empirical risk, we improved performance on out-of-sample data and were able to train with less data. EAML provides a platform for automated creation of problem-specific priors, which help build robust and dependable machine-learning models in critical applications.
Keywords: computational medicine; machine learning; medicine.
Copyright © 2020 the Author(s). Published by PNAS.
Conflict of interest statement
Competing interest statement: The editor, P.J.B., and one of the authors, M.J.v.d.L., are at the same institution (University of California, Berkeley).
Figures
References
-
- Lenat D. B., Prakash M., Shepherd M., CYC: Using common sense knowledge to overcome brittleness and knowledge acquisition bottlenecks. AI Magazine 6, 65 (1985).
-
- Cooper G. F., et al. , Predicting dire outcomes of patients with community acquired pneumonia. J. Biomed. Inform. 38, 347–366 (2005). - PubMed
