

Training set coherence and set size effects on concept generalization and recognition
- PMID: 32105147
- PMCID: PMC7363543
- DOI: 10.1037/xlm0000824
Training set coherence and set size effects on concept generalization and recognition
Abstract
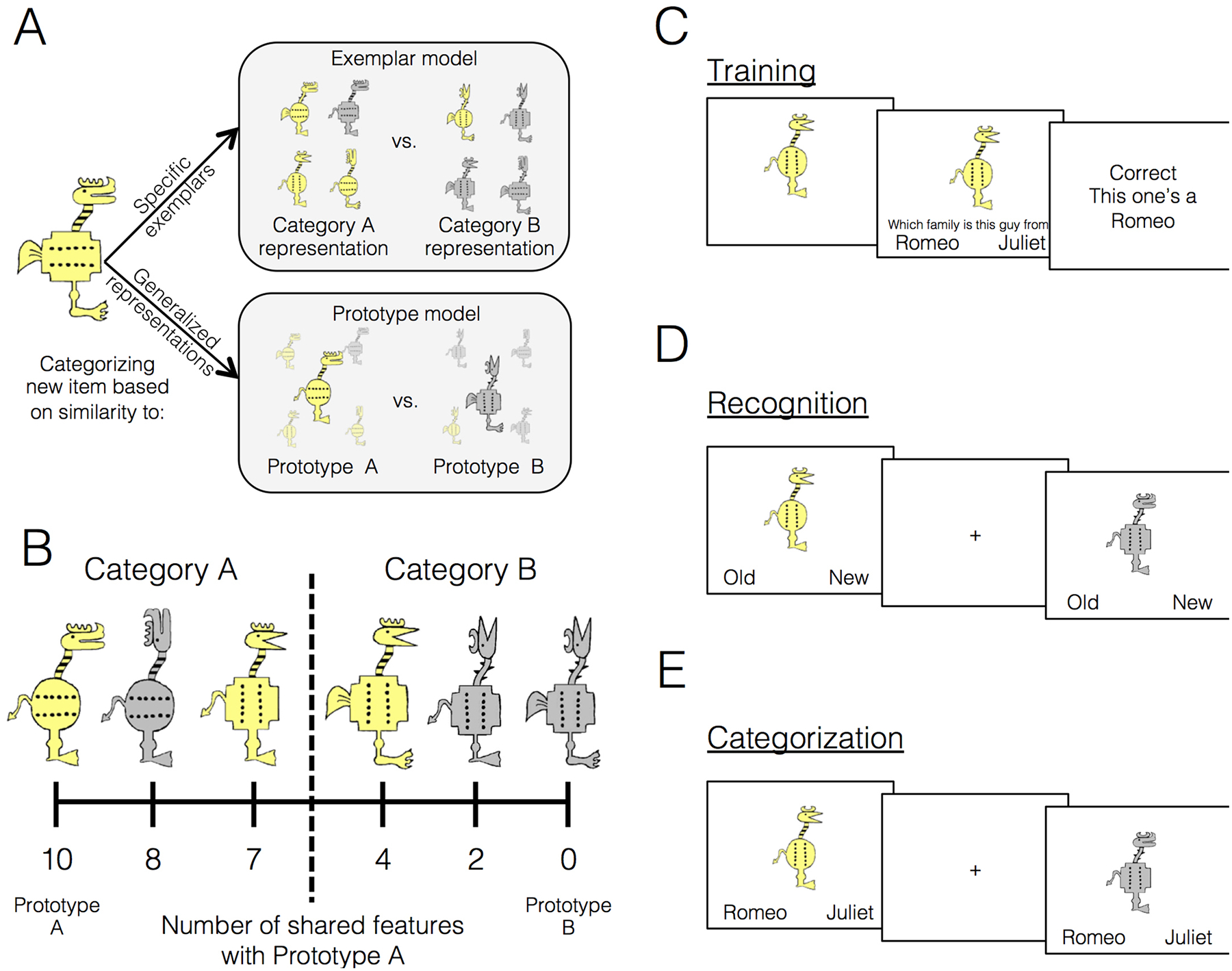
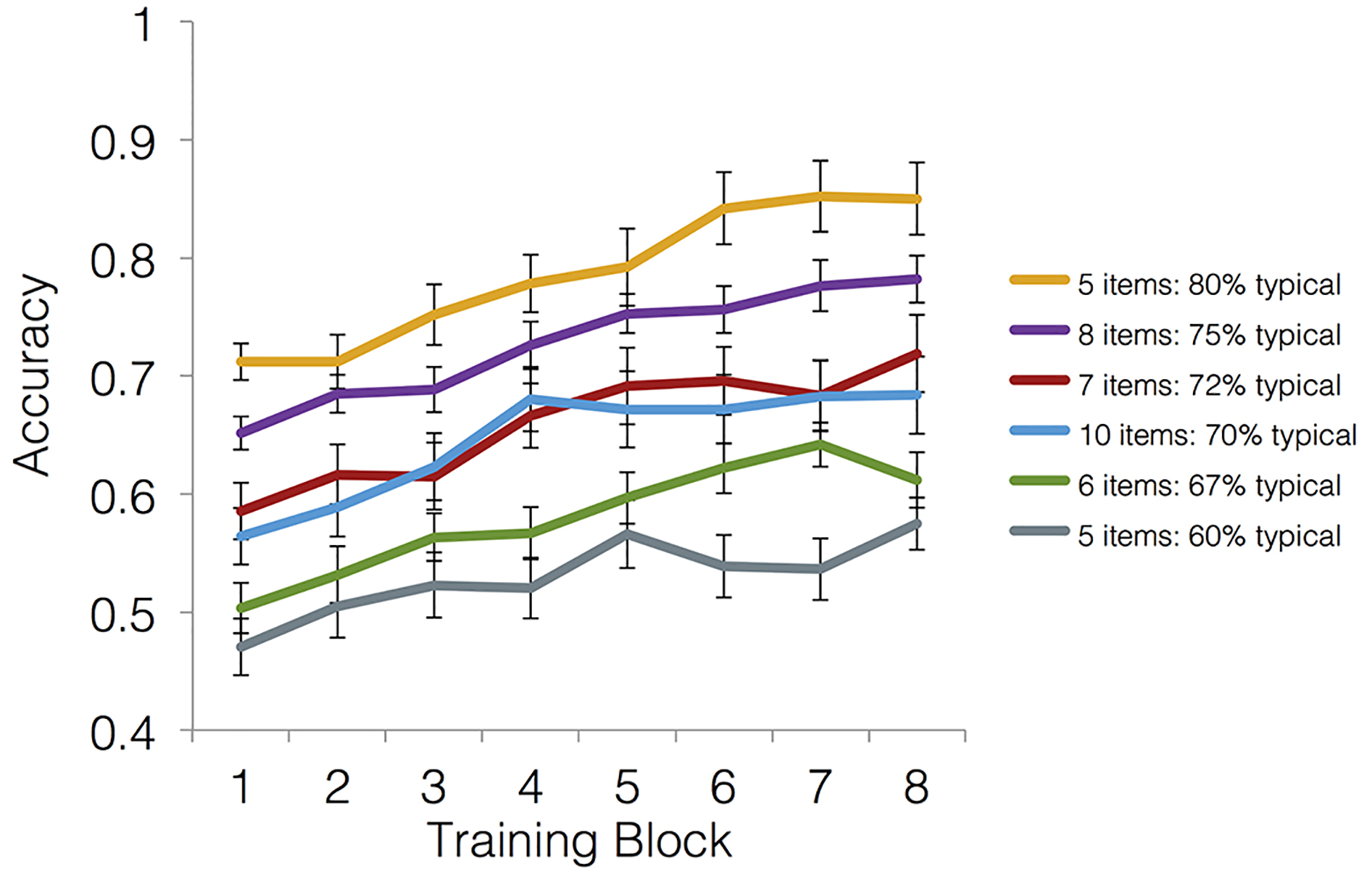
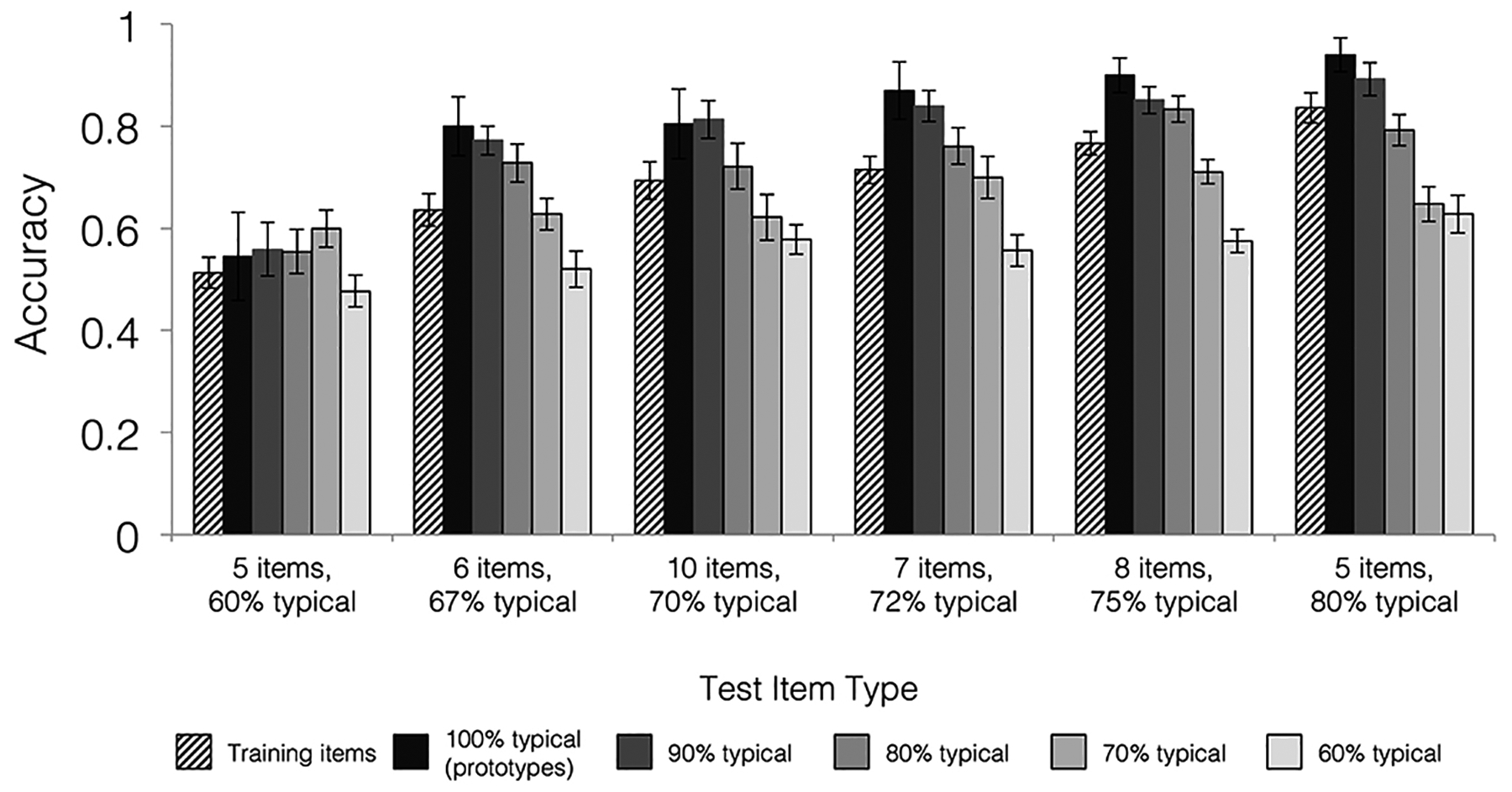
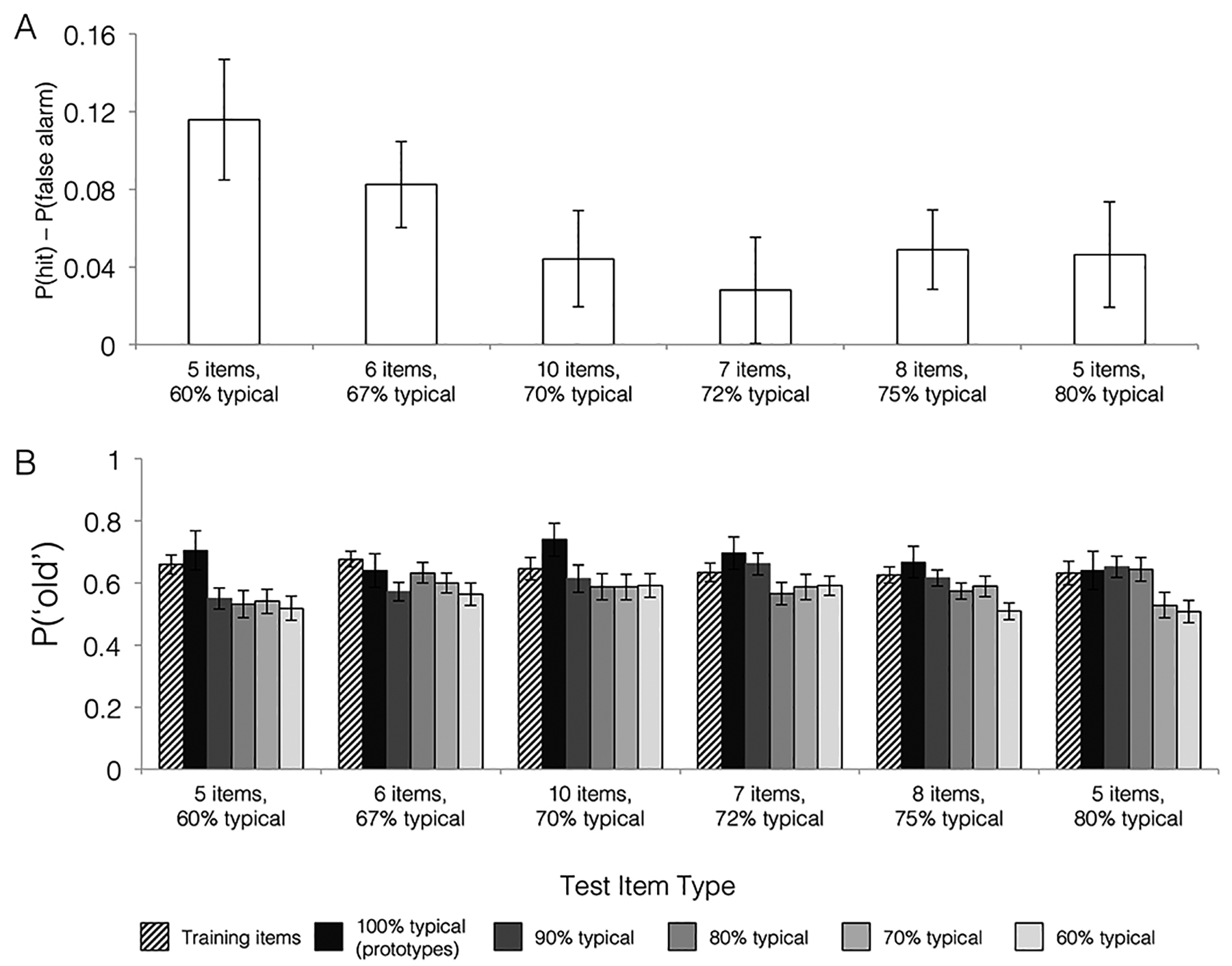
Building conceptual knowledge that generalizes to novel situations is a key function of human memory. Category-learning paradigms have long been used to understand the mechanisms of knowledge generalization. In the present study, we tested the conditions that promote formation of new concepts. Participants underwent 1 of 6 training conditions that differed in the number of examples per category (set size) and their relative similarity to the category average (set coherence). Performance metrics included rates of category learning, ability to generalize categories to new items of varying similarity to prototypes, and recognition memory for individual examples. In categorization, high set coherence led to faster learning and better generalization, while set size had little effect. Recognition did not differ reliably among conditions. We also tested the nature of memory representations used for categorization and recognition decisions using quantitative prototype and exemplar models fit to behavioral responses. Prototype models posit abstract category representations based on the category's central tendency, whereas exemplar models posit that categories are represented by individual category members. Prototype strategy use during categorization increased with increasing set coherence, suggesting that coherent training sets facilitate extraction of commonalities within a category. We conclude that learning from a coherent set of examples is an efficient means of forming abstract knowledge that generalizes broadly. (PsycInfo Database Record (c) 2020 APA, all rights reserved).
Conflict of interest statement
The authors declare no competing financial interests.
Figures
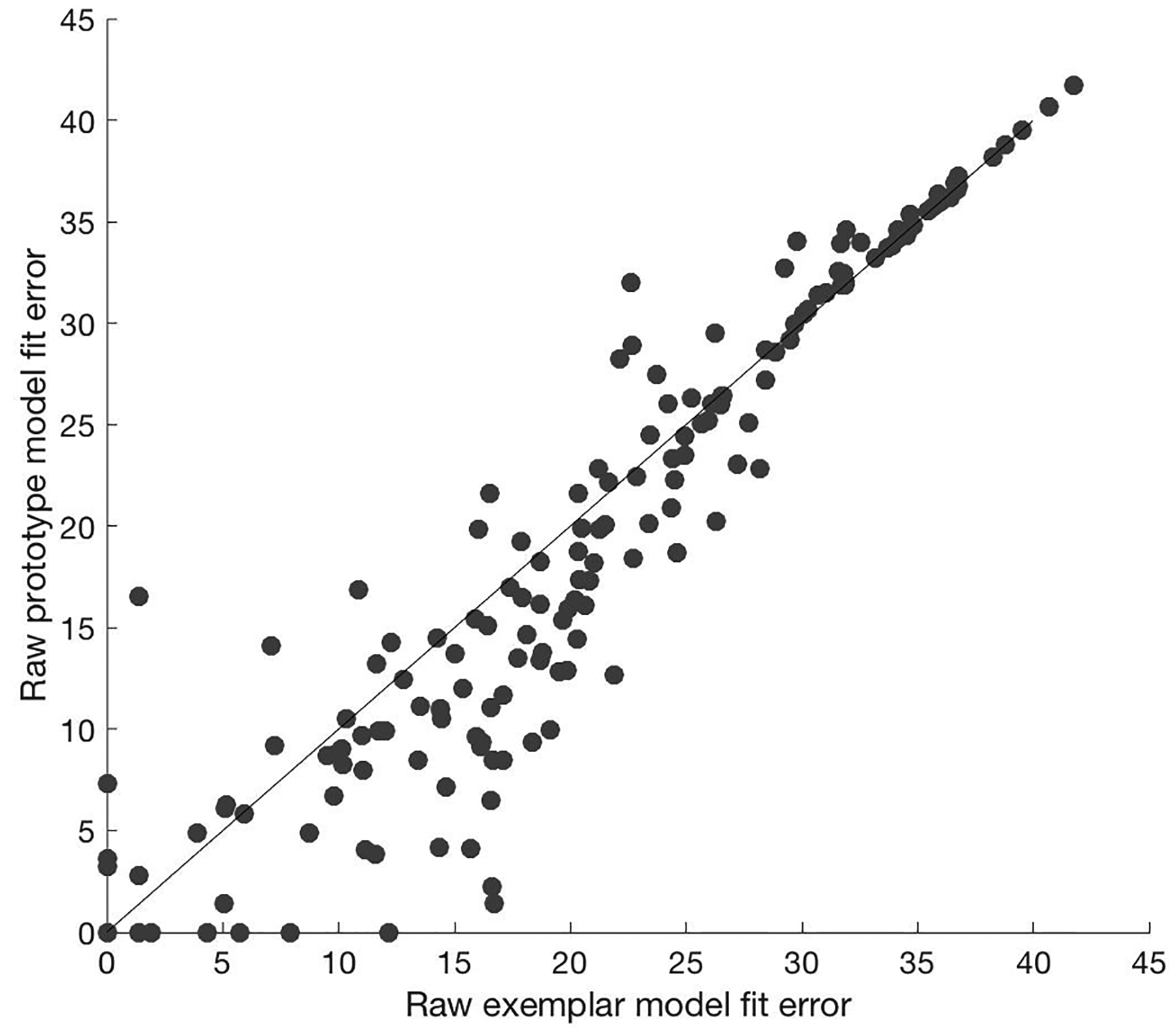
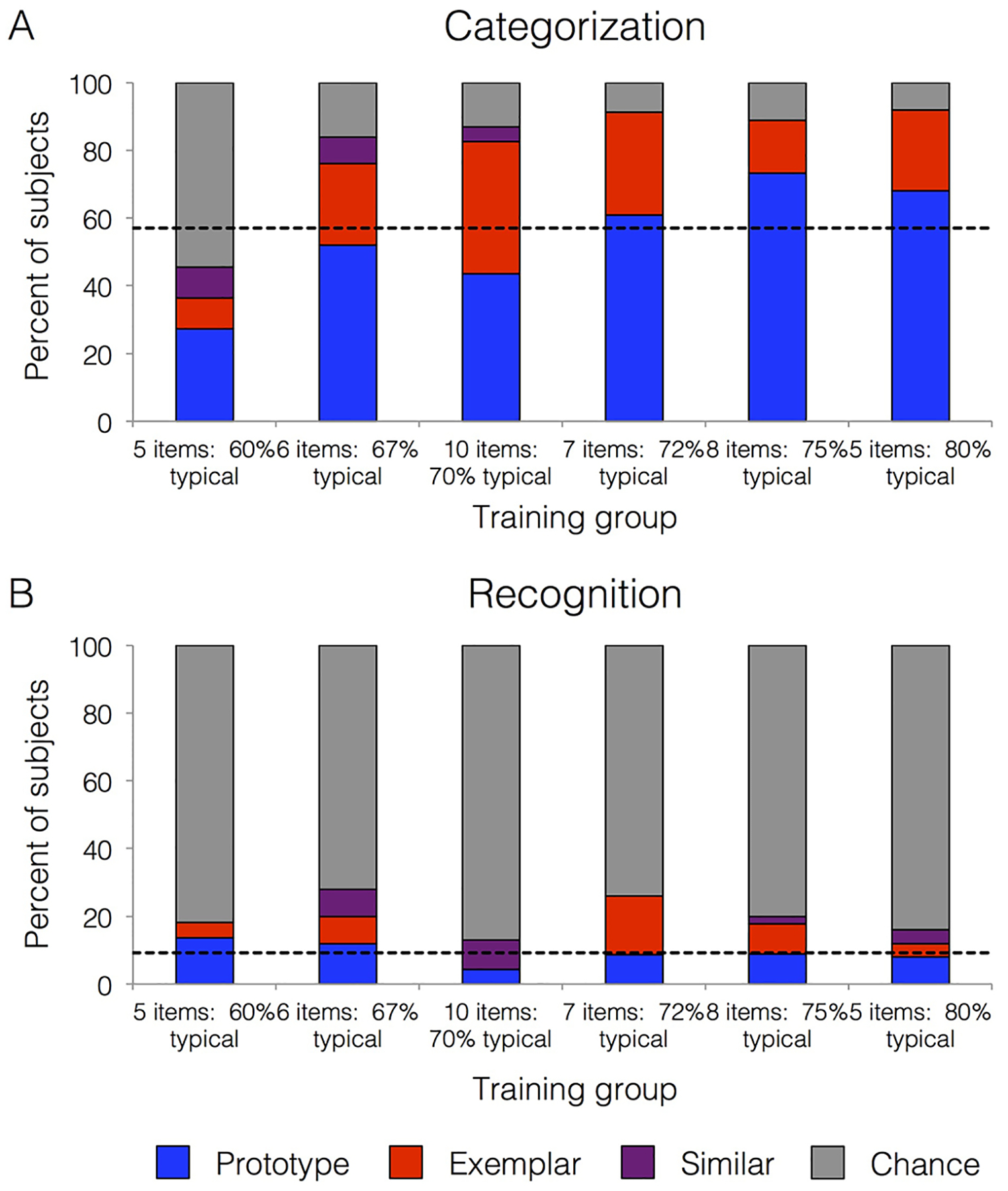
References
-
- Arndt J, & Hirshman E (1998). True and False Recognition in MINERVA2: Explanations from a Global Matching Perspective. Journal of Memory and Language. 10.1006/jmla.1998.2581 - DOI
-
- Bartlett FC (1932). Remembering : A Study in Experimental and Social Psychology. Cambridge, Social Psychology, 1–11. 10.1111/j.2044-8279.1933.tb02913.x - DOI
