

A synthetic dataset primer for the biobehavioural sciences to promote reproducibility and hypothesis generation
- PMID: 32159513
- PMCID: PMC7112950
- DOI: 10.7554/eLife.53275
A synthetic dataset primer for the biobehavioural sciences to promote reproducibility and hypothesis generation
Abstract
Open research data provide considerable scientific, societal, and economic benefits. However, disclosure risks can sometimes limit the sharing of open data, especially in datasets that include sensitive details or information from individuals with rare disorders. This article introduces the concept of synthetic datasets, which is an emerging method originally developed to permit the sharing of confidential census data. Synthetic datasets mimic real datasets by preserving their statistical properties and the relationships between variables. Importantly, this method also reduces disclosure risk to essentially nil as no record in the synthetic dataset represents a real individual. This practical guide with accompanying R script enables biobehavioural researchers to create synthetic datasets and assess their utility via the synthpop R package. By sharing synthetic datasets that mimic original datasets that could not otherwise be made open, researchers can ensure the reproducibility of their results and facilitate data exploration while maintaining participant privacy.
Keywords: data; human biology; medicine; meta-research; none; statistics.
Plain language summary
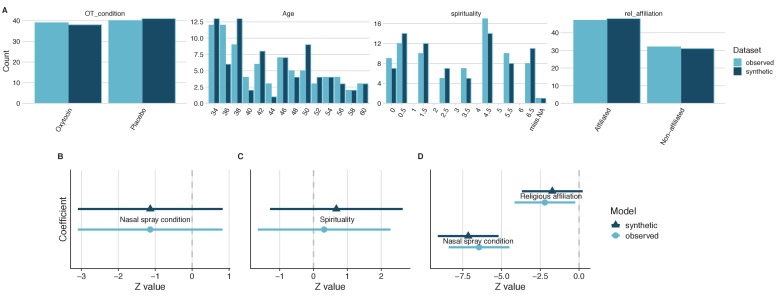
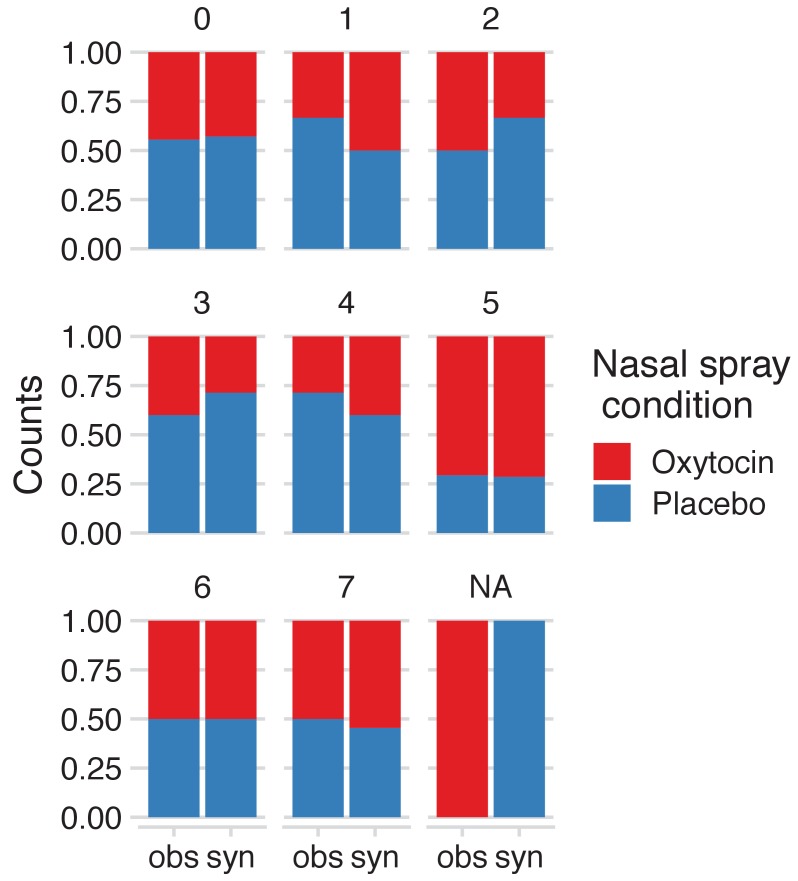
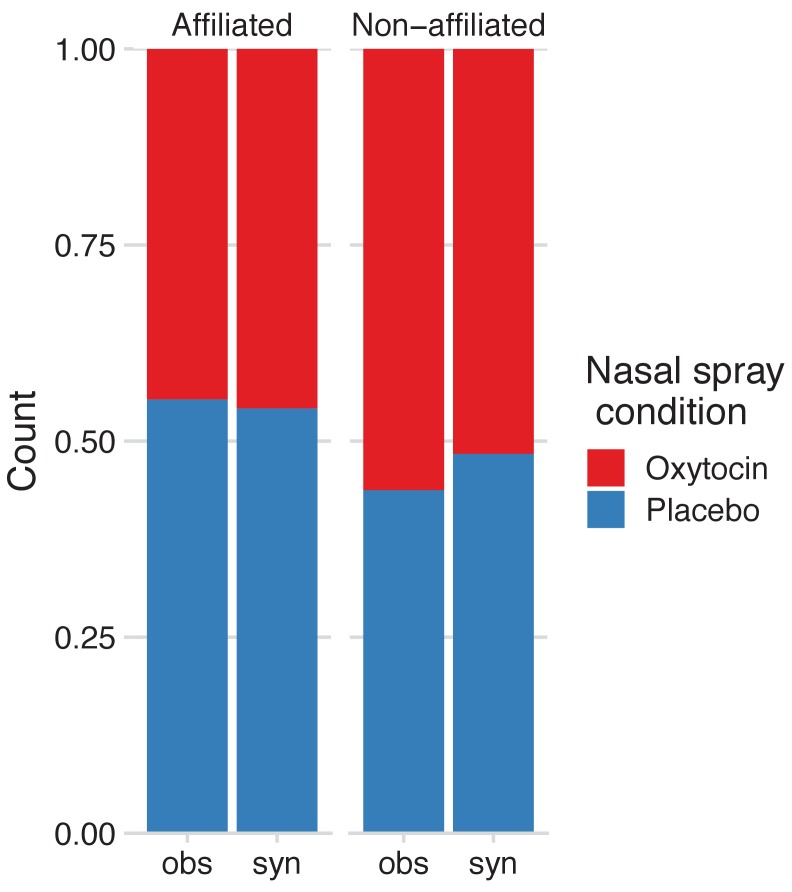
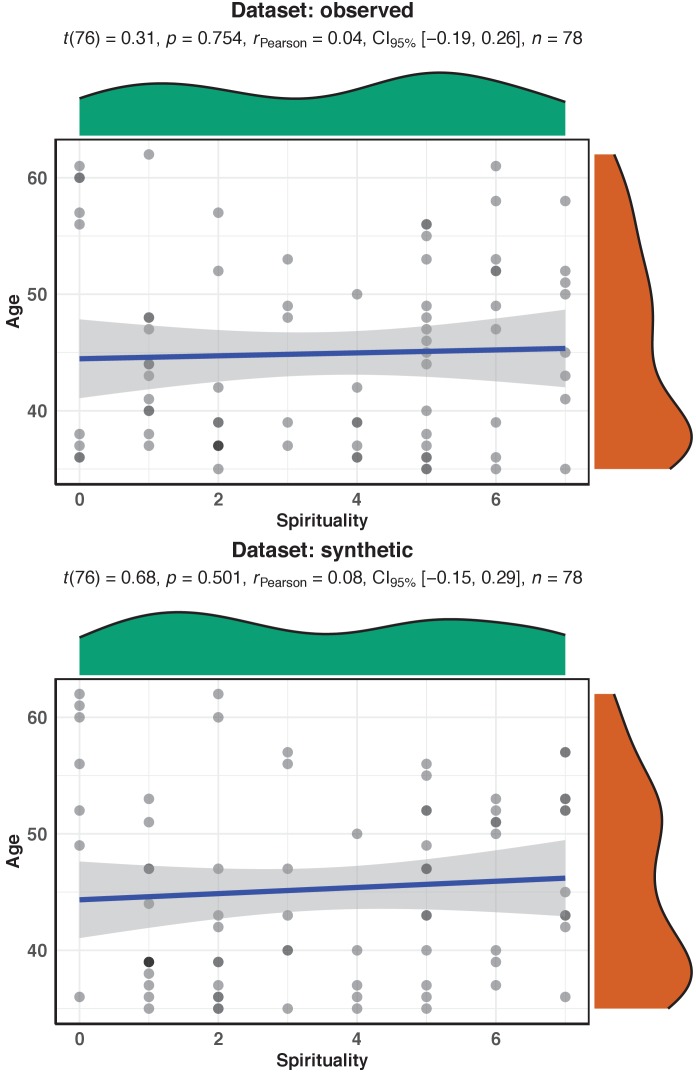
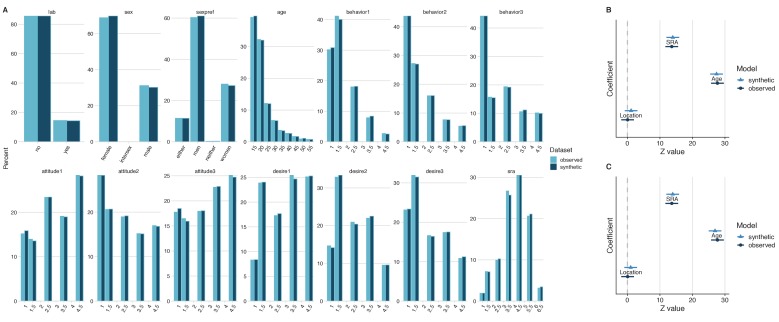
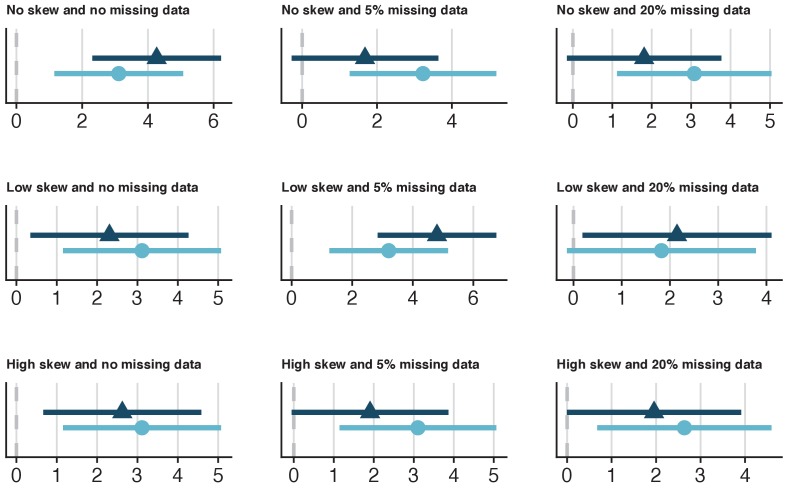
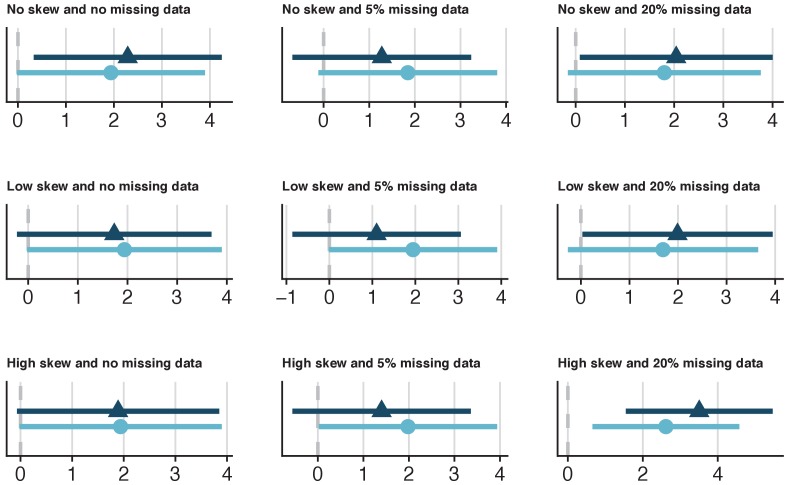
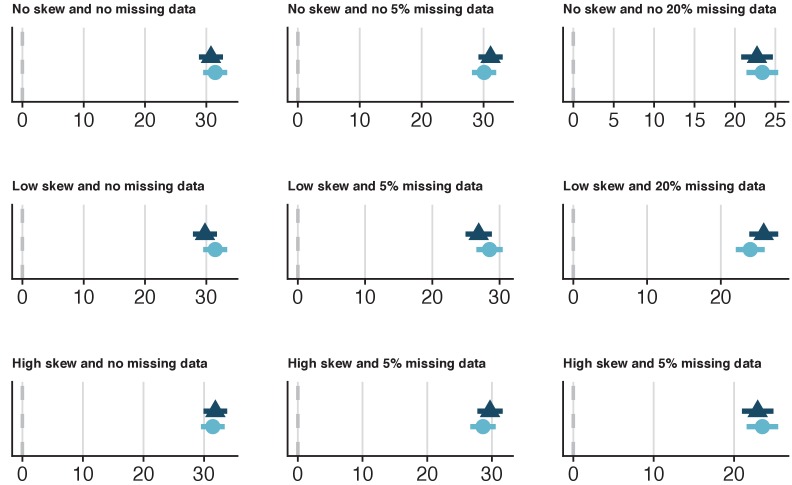
It is becoming increasingly common for scientists to share their data with other researchers. This makes it possible to independently verify reported results, which increases trust in research. Sometimes it is not possible to share certain datasets because they include sensitive information about individuals. In psychology and medicine, scientists have tried to remove identifying information from datasets before sharing them by, for example, adding minor artificial errors. But, even when researchers take these steps, it may still be possible to identify individuals, and the introduction of artificial errors can make it harder to verify the original results. One potential alternative to sharing sensitive data is to create ‘synthetic datasets’. Synthetic datasets mimic original datasets by maintaining the statistical properties of the data but without matching the original recorded values. Synthetic datasets are already being used, for example, to share confidential census data. However, this approach is rarely used in other areas of research. Now, Daniel S. Quintana demonstrates how synthetic datasets can be used in psychology and medicine. Three different datasets were studied to ensure that synthetic datasets performed well regardless of the type or size of the data. Quintana evaluated freely available software that could generate synthetic versions of these different datasets, which essentially removed any identifying information. The results obtained by analysing the synthetic datasets closely mimicked the original results. These tools could allow researchers to verify each other’s results more easily without jeopardizing the privacy of participants. This could encourage more collaboration, stimulate ideas for future research, and increase data sharing between research groups.
© 2020, Quintana.
Conflict of interest statement
DQ No competing interests declared
Figures
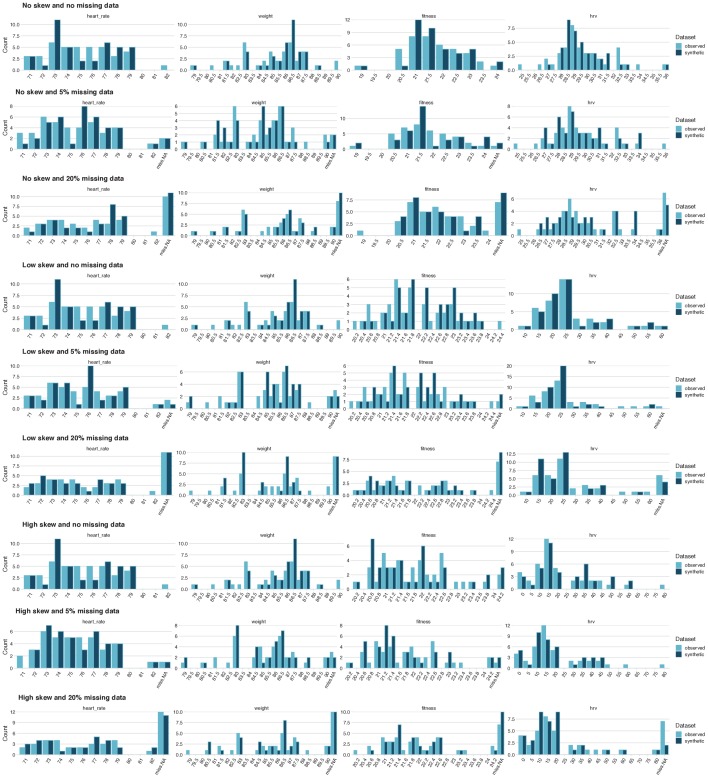
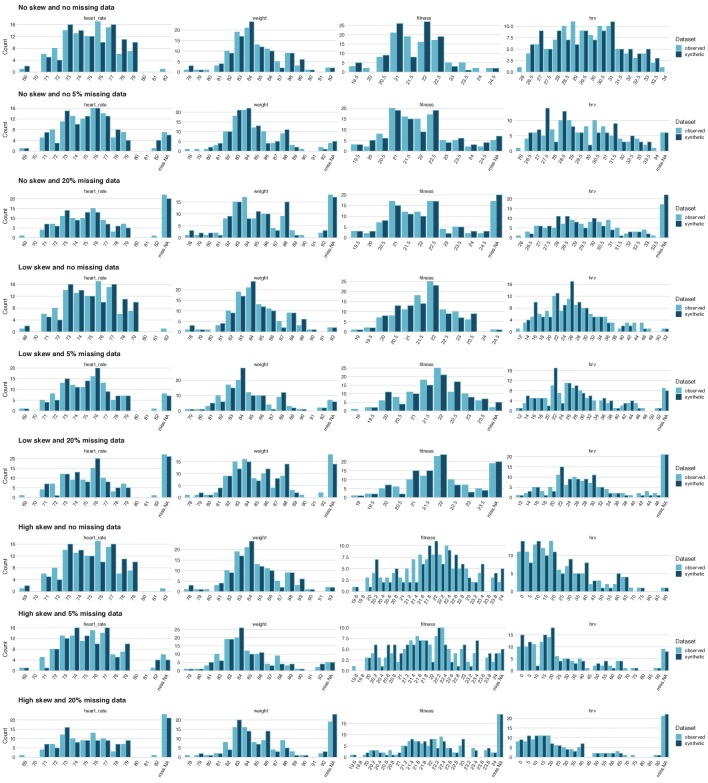
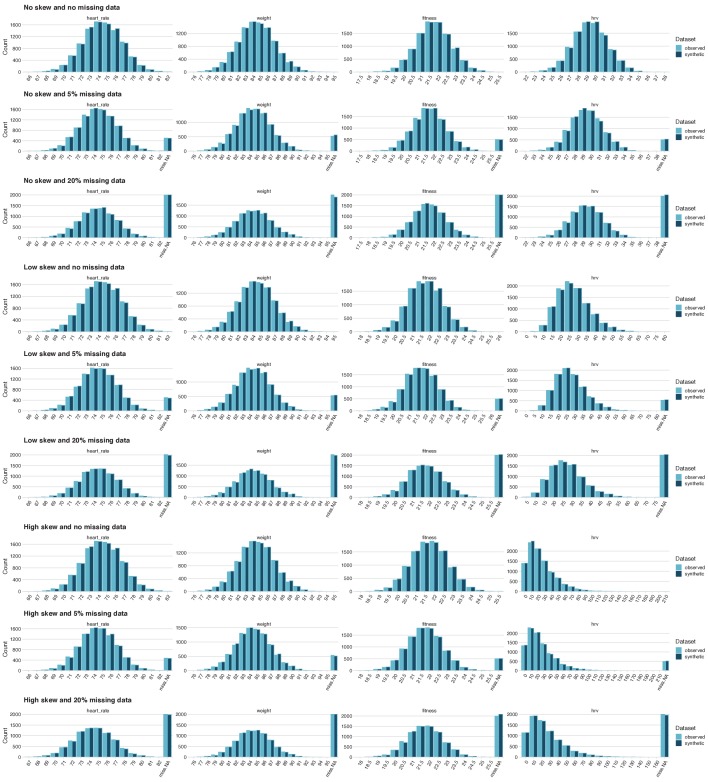
References
-
- Anscombe FJ. Graphs in statistical analysis. The American Statistician. 1973;27:17–21. doi: 10.1080/00031305.1973.10478966. - DOI
-
- Arzberger P, Schroeder P, Beaulieu A, Bowker G, Casey K, Laaksonen L, Moorman D, Uhlir P, Wouters P. Promoting access to public research data for scientific, economic, and social development. Data Science Journal. 2004;3:135–152. doi: 10.2481/dsj.3.135. - DOI
-
- Asendorpf JB, Conner M, De Fruyt F, De Houwer J, Denissen JJA, Fiedler K, Fiedler S, Funder DC, Kliegl R, Nosek BA, Perugini M, Roberts BW, Schmitt M, van Aken MAG, Weber H, Wicherts JM. Recommendations for increasing replicability in psychology. European Journal of Personality. 2013;27:108–119. doi: 10.1002/per.1919. - DOI
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
