

Deep splicing plasticity of the human adenovirus type 5 transcriptome drives virus evolution
- PMID: 32170151
- PMCID: PMC7070027
- DOI: 10.1038/s42003-020-0849-9
Deep splicing plasticity of the human adenovirus type 5 transcriptome drives virus evolution
Abstract
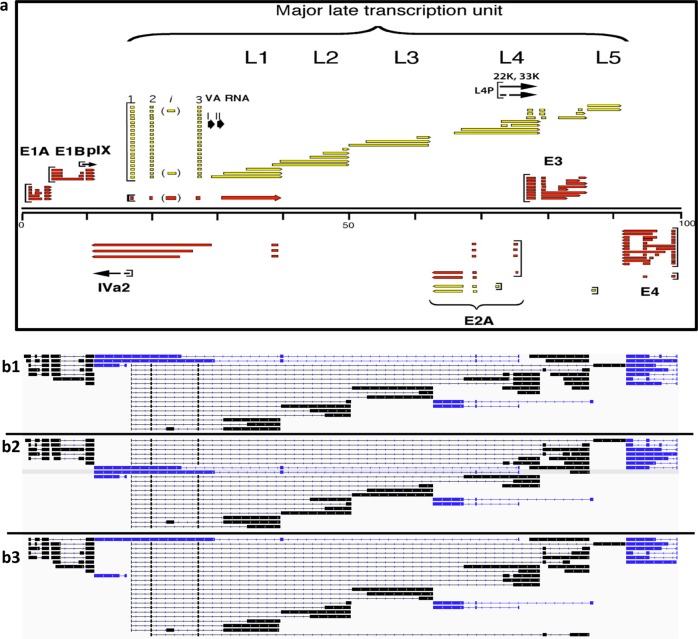
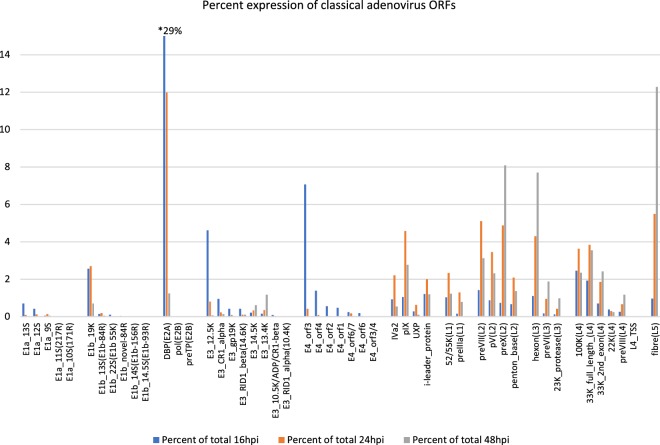
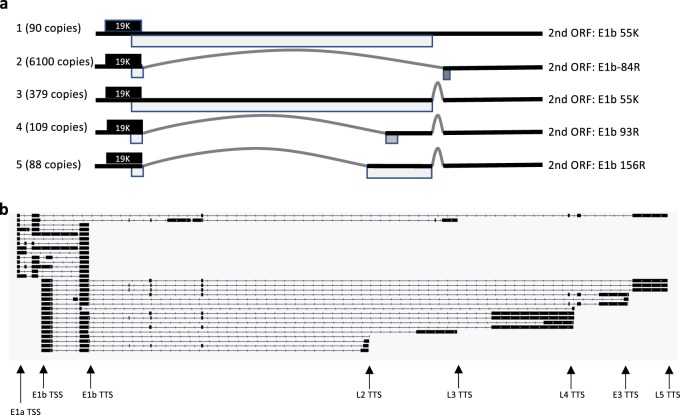
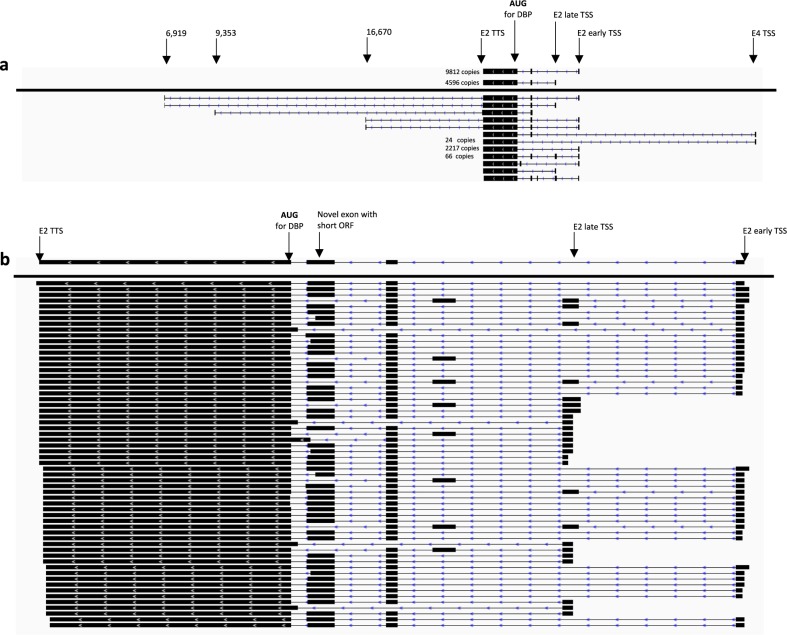
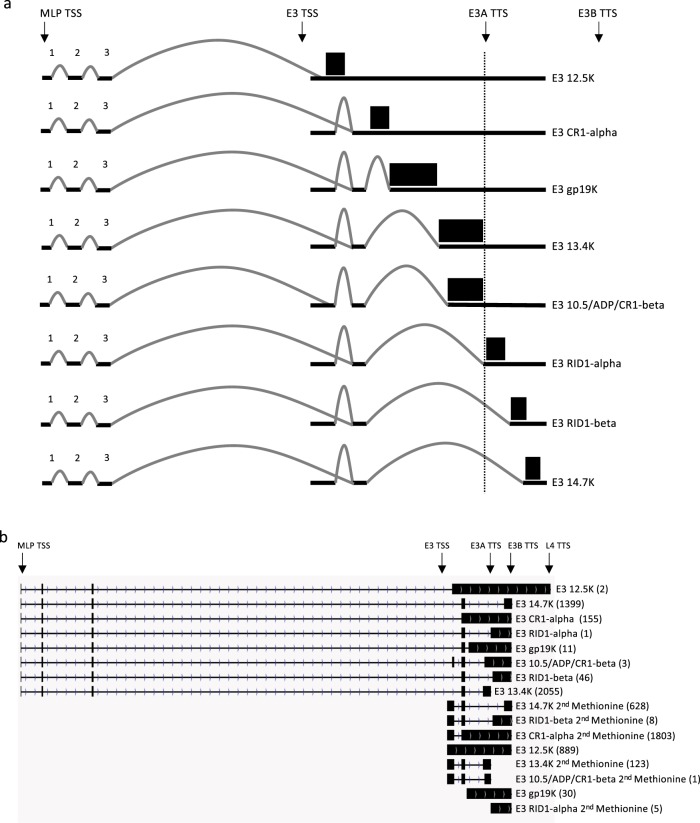
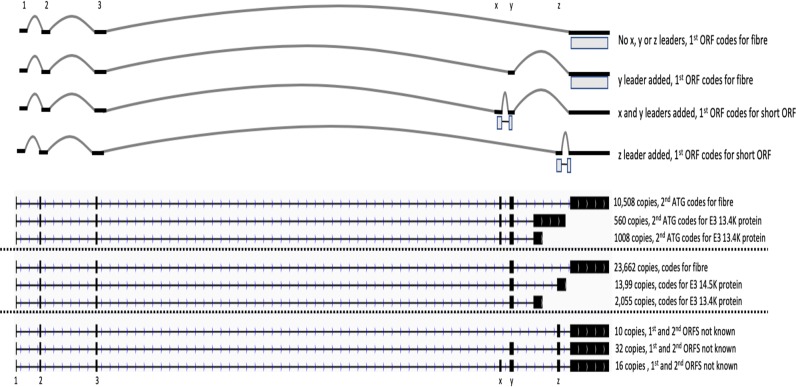
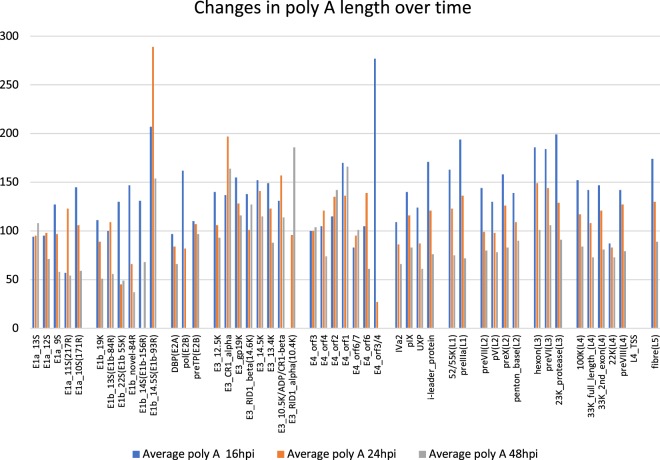
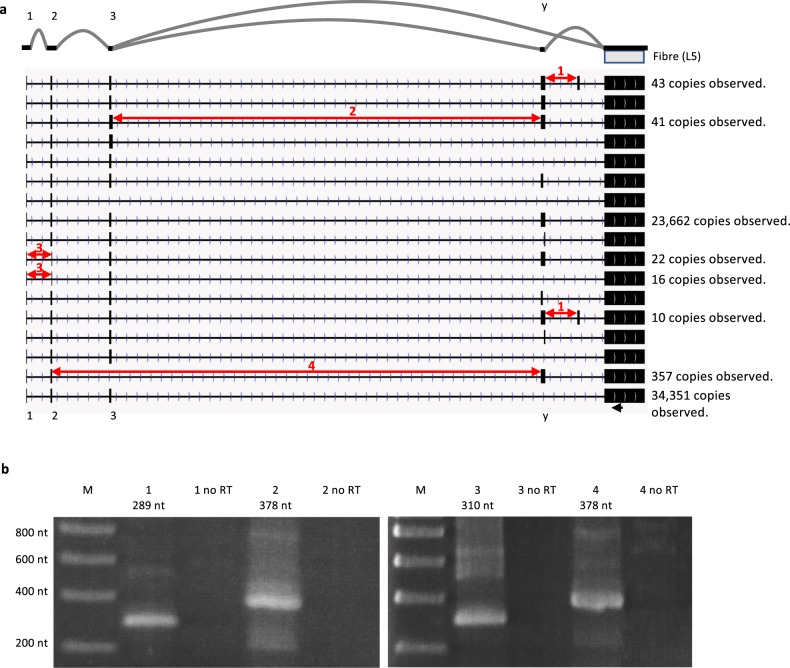
Viral genomes have high gene densities and complex transcription strategies rendering transcriptome analysis through short-read RNA-seq approaches problematic. Adenovirus transcription and splicing is especially complex. We used long-read direct RNA sequencing to study adenovirus transcription and splicing during infection. This revealed a previously unappreciated complexity of alternative splicing and potential for secondary initiating codon usage. Moreover, we find that most viral transcripts tend to shorten polyadenylation lengths as infection progresses. Development of an open reading frame centric bioinformatics analysis pipeline provided a deeper quantitative and qualitative understanding of adenovirus's genetic potential. Across the viral genome adenovirus makes multiple distinctly spliced transcripts that code for the same protein. Over 11,000 different splicing patterns were recorded across the viral genome, most occurring at low levels. This low-level use of alternative splicing patterns potentially enables the virus to maximise its coding potential over evolutionary timescales.
Conflict of interest statement
The authors declare no competing interests.
Figures


References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
