

Benchmarking of computational error-correction methods for next-generation sequencing data
- PMID: 32183840
- PMCID: PMC7079412
- DOI: 10.1186/s13059-020-01988-3
Benchmarking of computational error-correction methods for next-generation sequencing data
Abstract
Background: Recent advancements in next-generation sequencing have rapidly improved our ability to study genomic material at an unprecedented scale. Despite substantial improvements in sequencing technologies, errors present in the data still risk confounding downstream analysis and limiting the applicability of sequencing technologies in clinical tools. Computational error correction promises to eliminate sequencing errors, but the relative accuracy of error correction algorithms remains unknown.
Results: In this paper, we evaluate the ability of error correction algorithms to fix errors across different types of datasets that contain various levels of heterogeneity. We highlight the advantages and limitations of computational error correction techniques across different domains of biology, including immunogenomics and virology. To demonstrate the efficacy of our technique, we apply the UMI-based high-fidelity sequencing protocol to eliminate sequencing errors from both simulated data and the raw reads. We then perform a realistic evaluation of error-correction methods.
Conclusions: In terms of accuracy, we find that method performance varies substantially across different types of datasets with no single method performing best on all types of examined data. Finally, we also identify the techniques that offer a good balance between precision and sensitivity.
Conflict of interest statement
The authors declare that they have no competing interests.
Figures
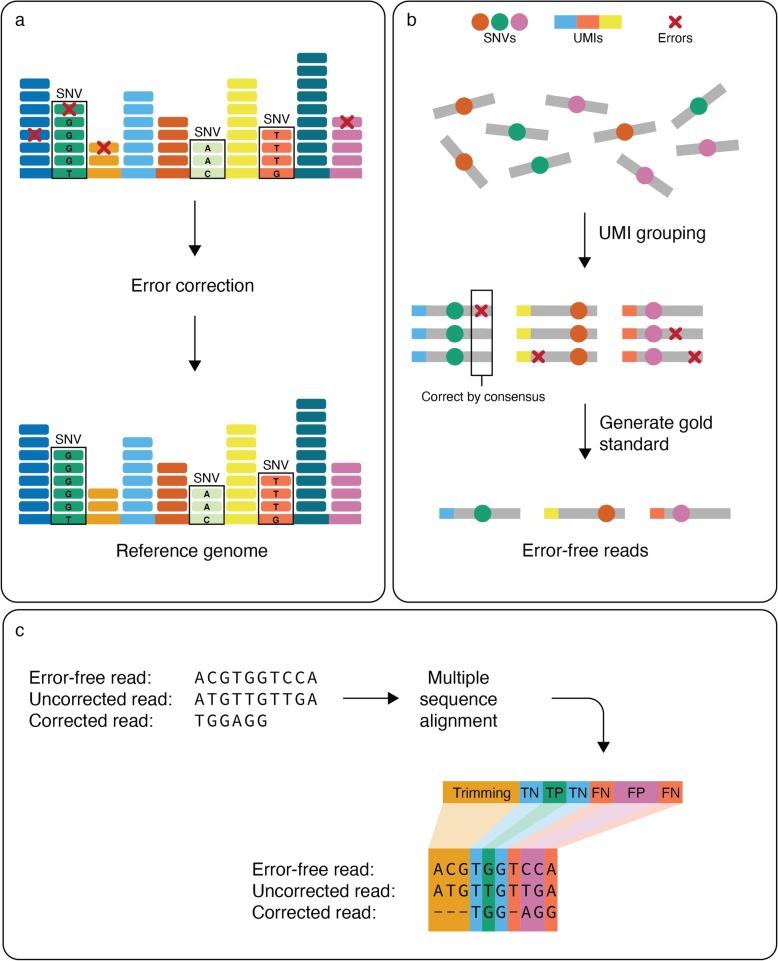
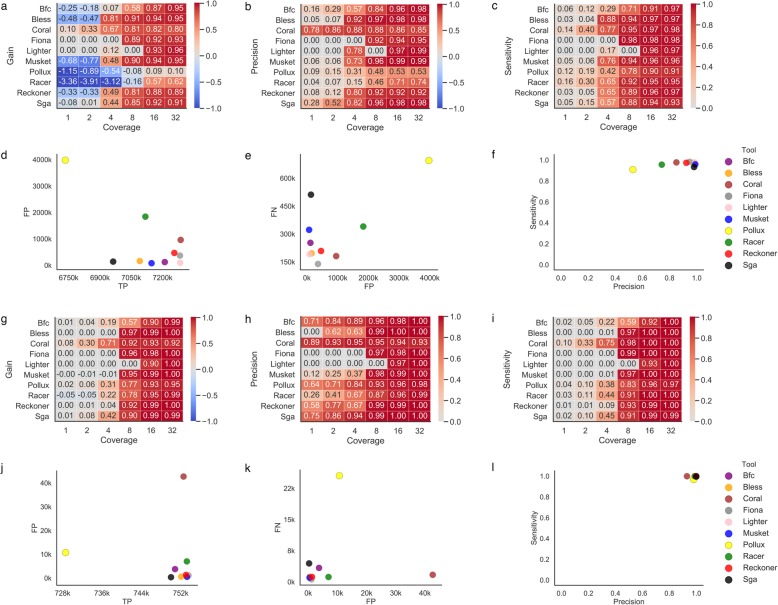
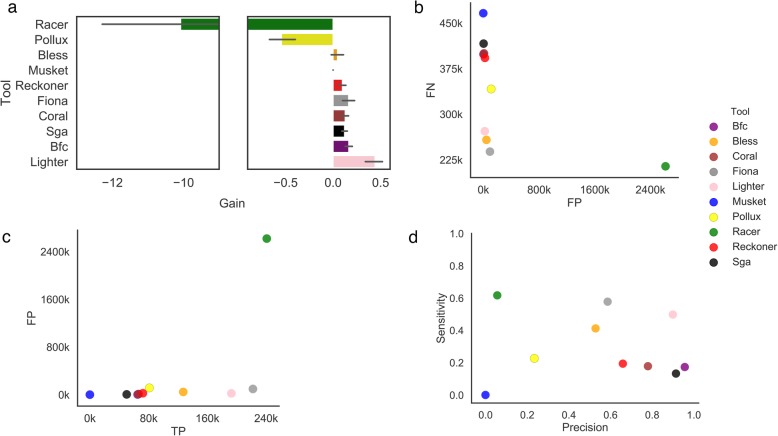
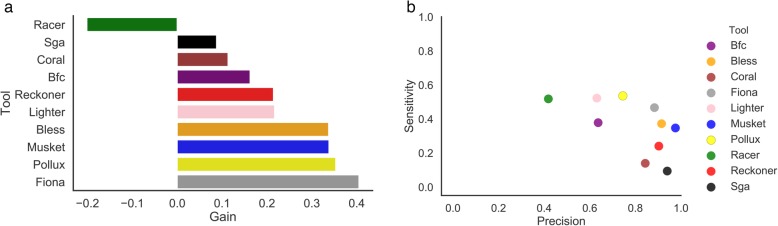
References
Publication types
MeSH terms
Substances
Associated data
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
