

Structural Biology of the Enterovirus Replication-Linked 5'-Cloverleaf RNA and Associated Virus Proteins
- PMID: 32188627
- PMCID: PMC7399744
- DOI: 10.1128/MMBR.00062-19
Structural Biology of the Enterovirus Replication-Linked 5'-Cloverleaf RNA and Associated Virus Proteins
Abstract
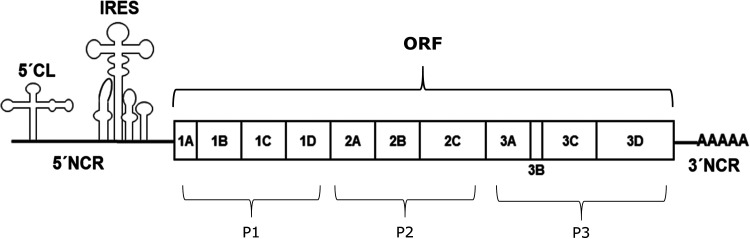
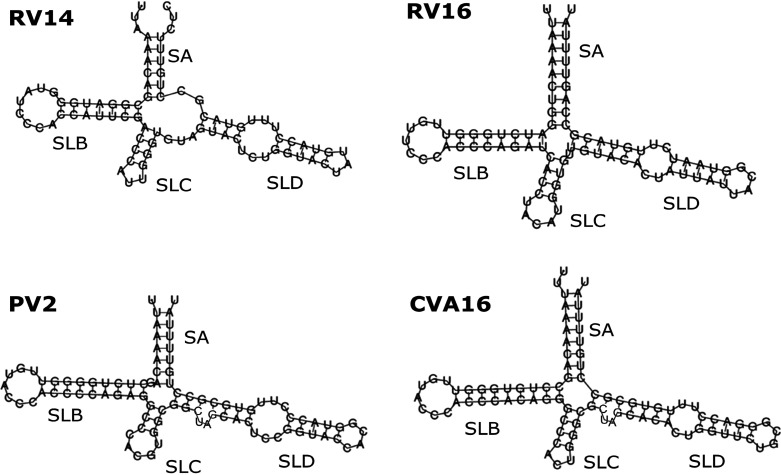
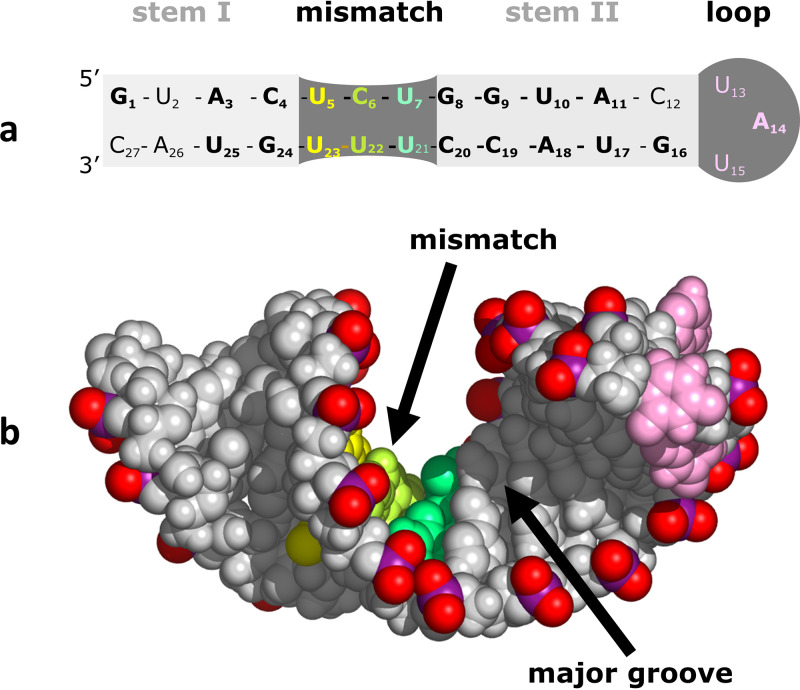
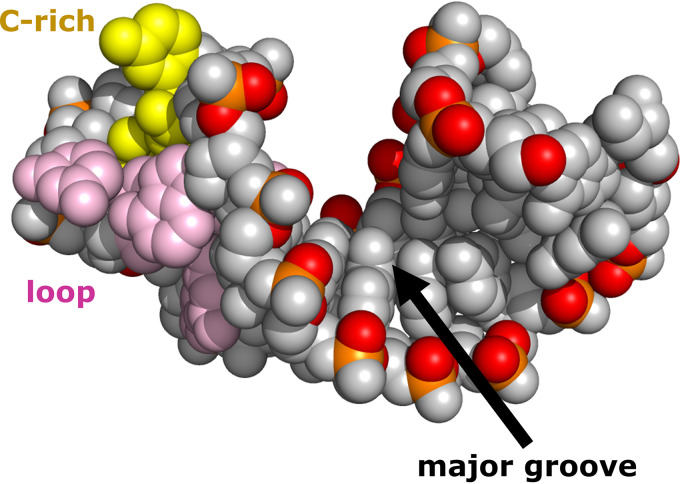
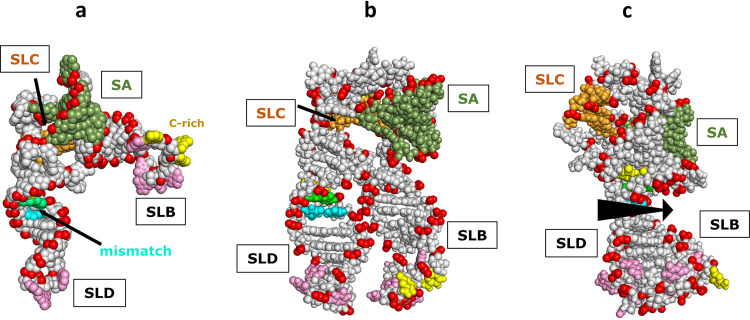
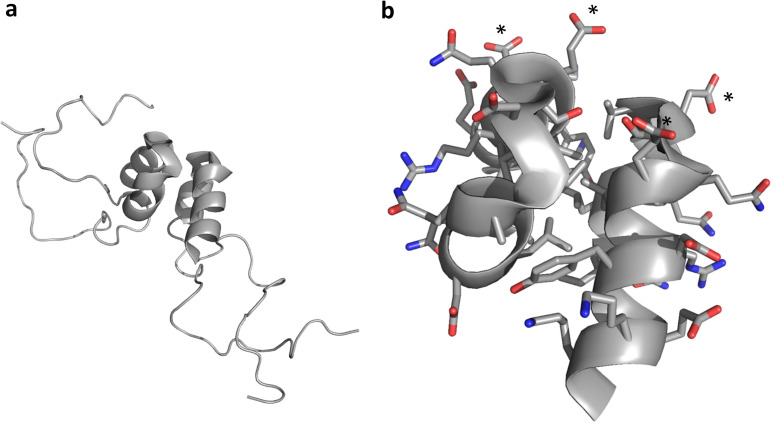
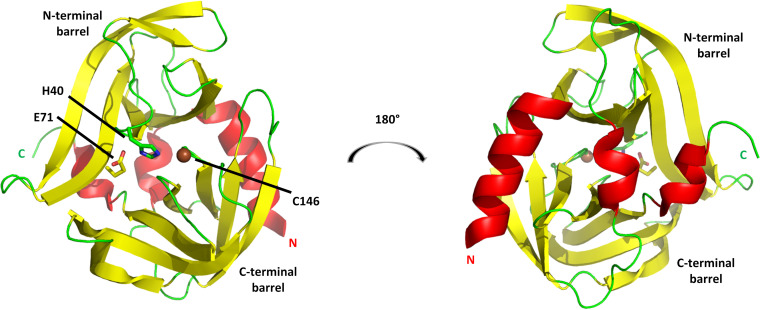
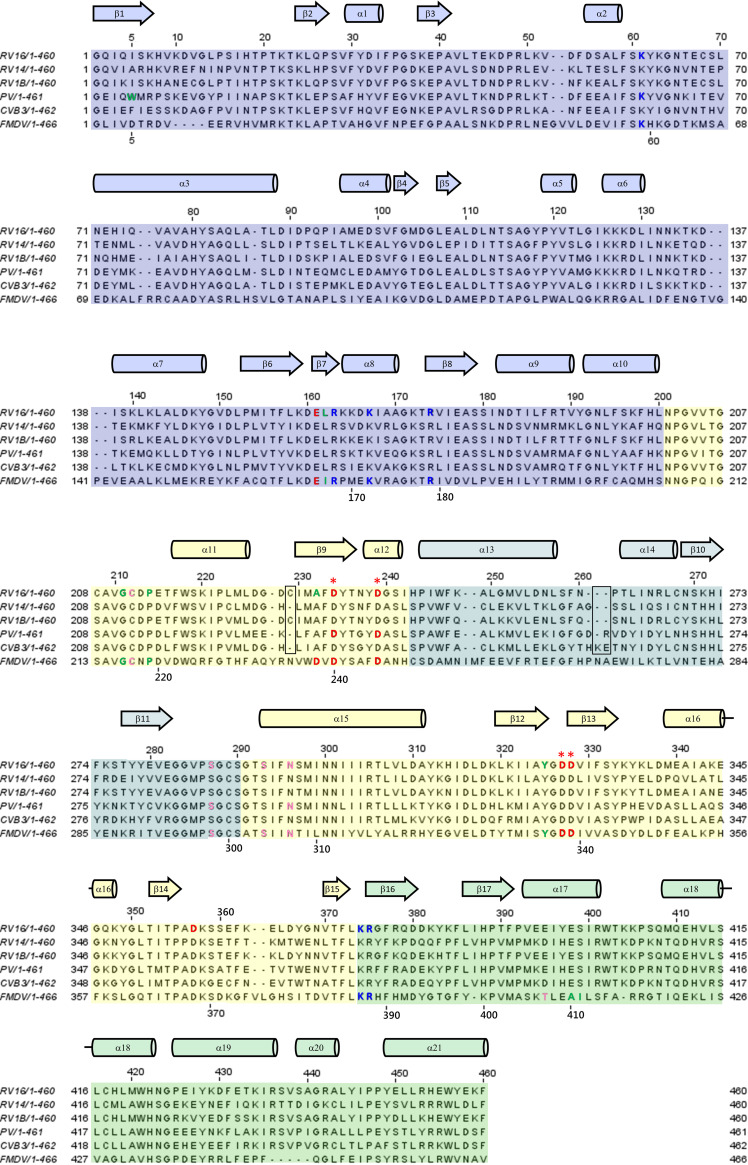
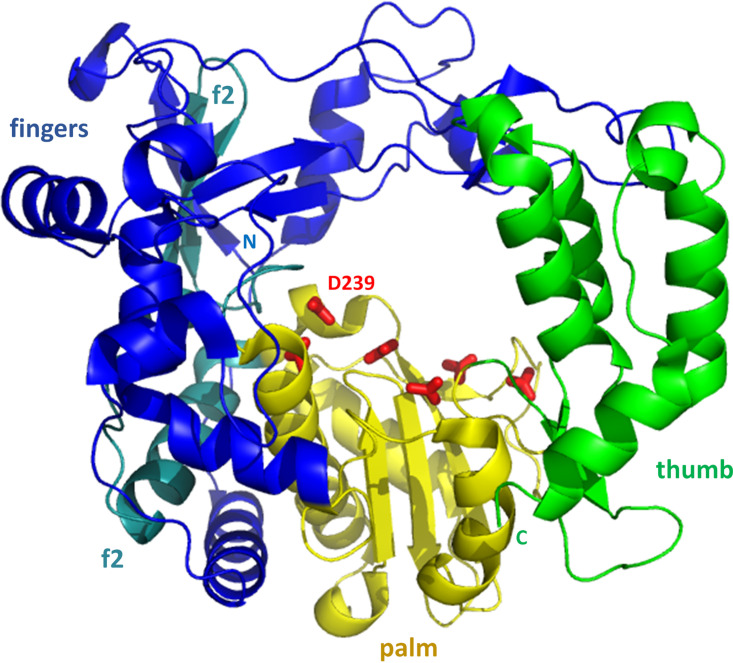
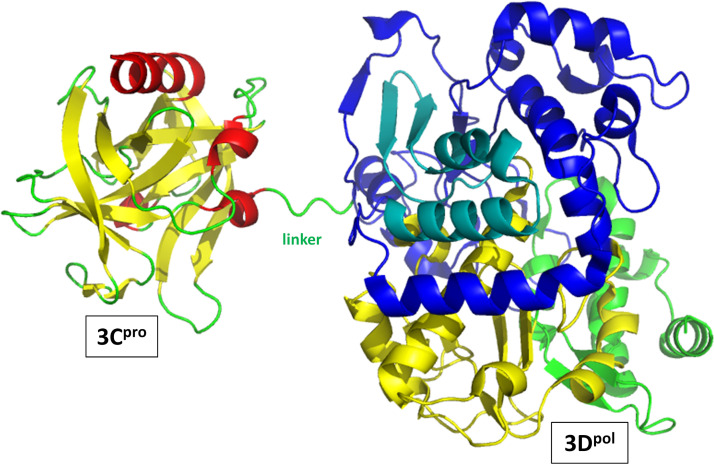
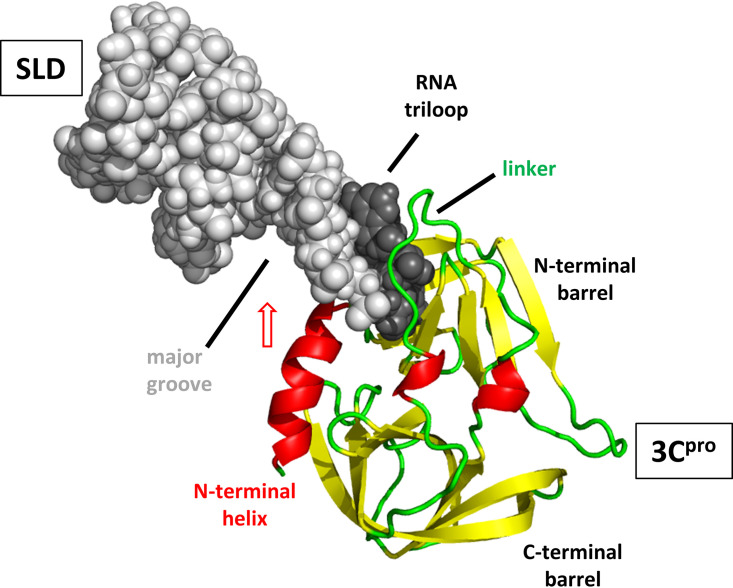
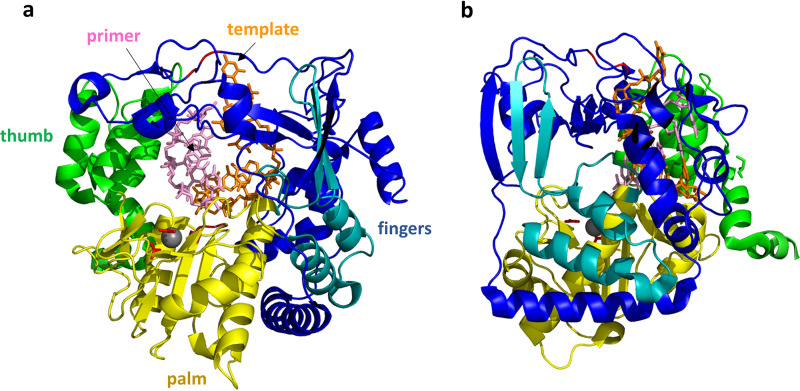
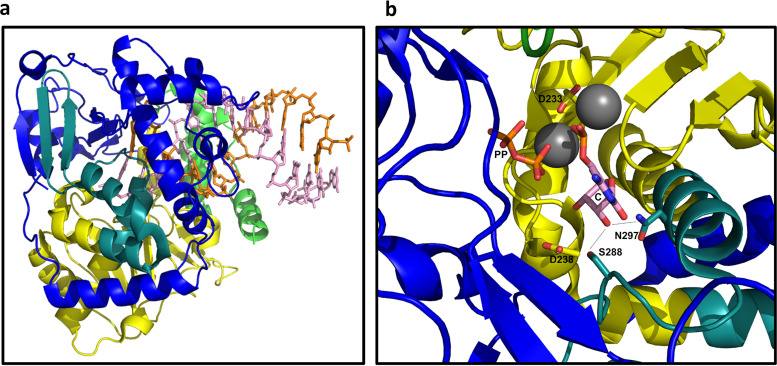
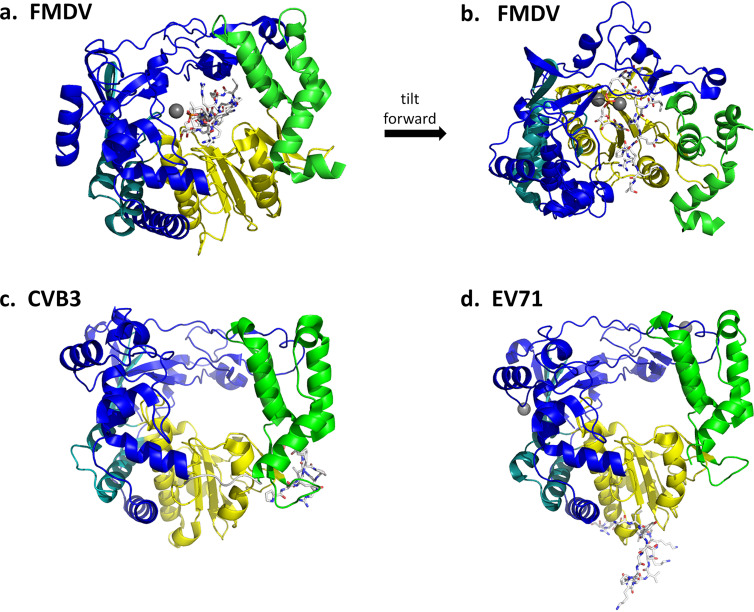
Although enteroviruses are associated with a wide variety of diseases and conditions, their mode of replication is well conserved. Their genome is carried as a single, positive-sense RNA strand. At the 5' end of the strand is an approximately 90-nucleotide self-complementary region called the 5' cloverleaf, or the oriL. This noncoding region serves as a platform upon which host and virus proteins, including the 3B, 3C, and 3D virus proteins, assemble in order to initiate replication of a negative-sense RNA strand. The negative strand in turn serves as a template for synthesis of multiple positive-sense RNA strands. Building on structural studies of individual RNA stem-loops, the structure of the intact 5' cloverleaf from rhinovirus has recently been determined via nuclear magnetic resonance/small-angle X-ray scattering (NMR/SAXS)-based methods, while structures have also been determined for enterovirus 3A, 3B, 3C, and 3D proteins. Analysis of these structures, together with structural and modeling studies of interactions between host and virus proteins and RNA, has begun to provide insight into the enterovirus replication mechanism and the potential to inhibit replication by blocking these interactions.
Keywords: SAXS; X-ray crystallography; enterovirus; nuclear magnetic resonance; picornavirus; structure; viral replication.
Copyright © 2020 American Society for Microbiology.
Figures
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
