

Generalization error analysis for deep convolutional neural network with transfer learning in breast cancer diagnosis
- PMID: 32208369
- PMCID: PMC7981191
- DOI: 10.1088/1361-6560/ab82e8
Generalization error analysis for deep convolutional neural network with transfer learning in breast cancer diagnosis
Abstract
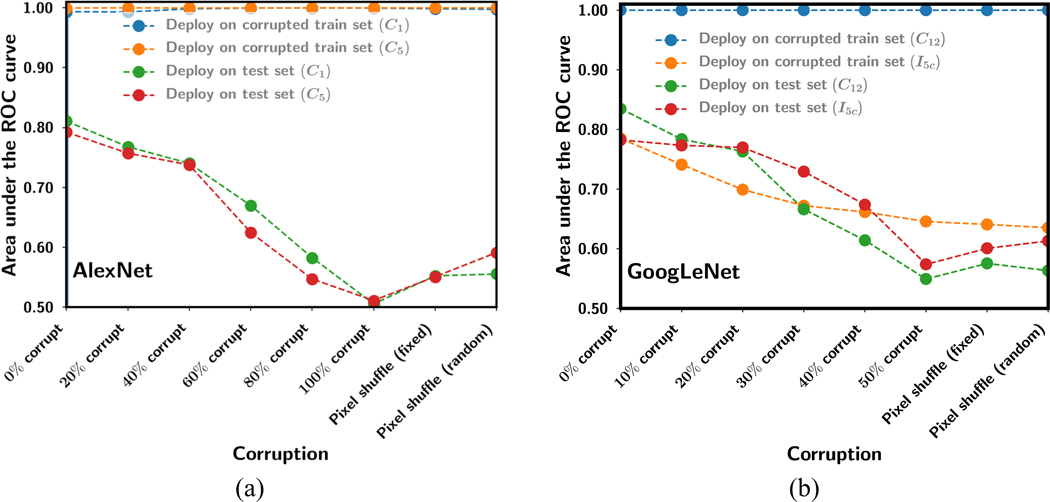
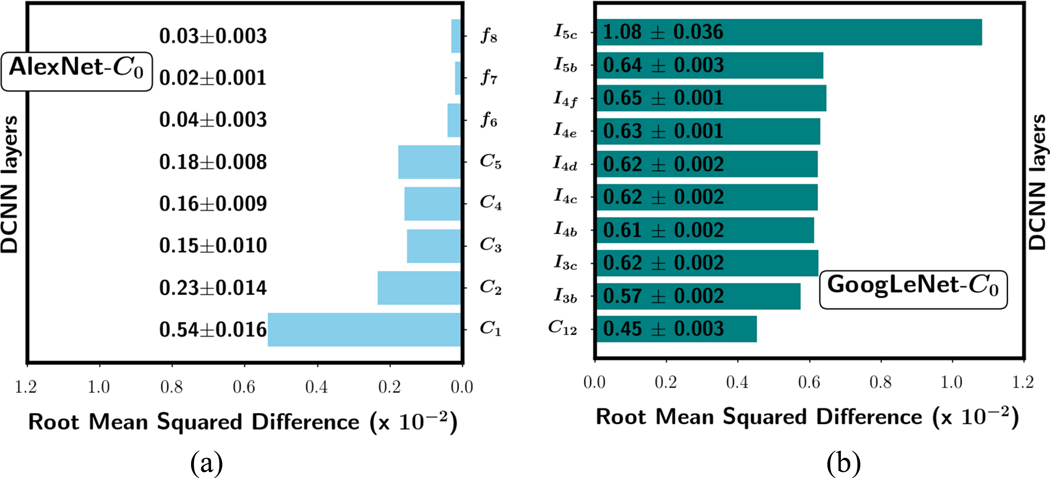
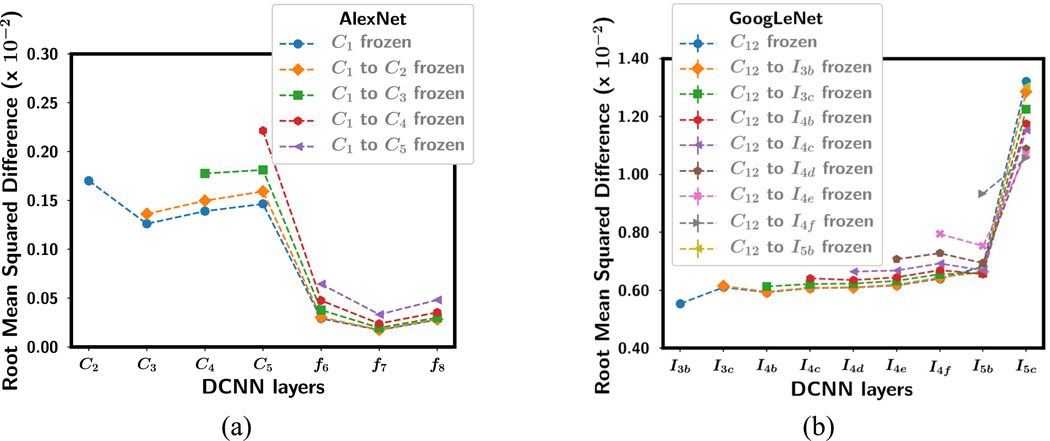
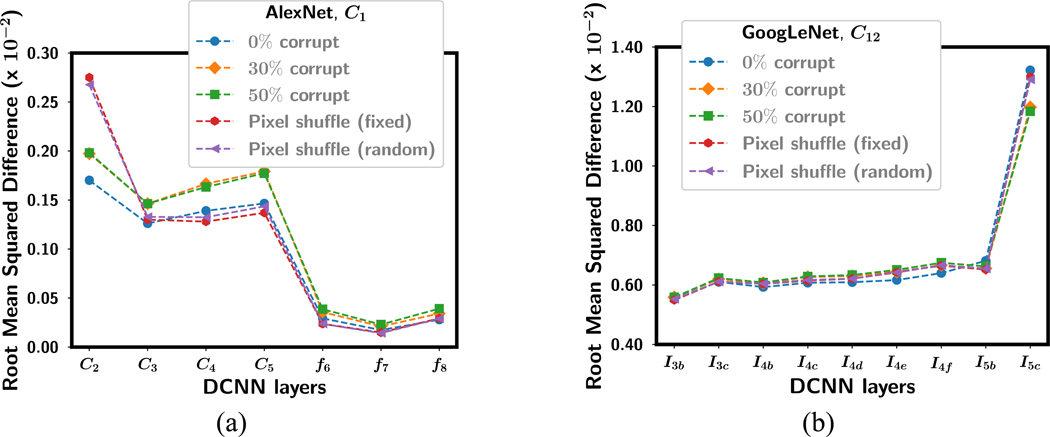
Deep convolutional neural network (DCNN), now popularly called artificial intelligence (AI), has shown the potential to improve over previous computer-assisted tools in medical imaging developed in the past decades. A DCNN has millions of free parameters that need to be trained, but the training sample set is limited in size for most medical imaging tasks so that transfer learning is typically used. Automatic data mining may be an efficient way to enlarge the collected data set but the data can be noisy such as incorrect labels or even a wrong type of image. In this work we studied the generalization error of DCNN with transfer learning in medical imaging for the task of classifying malignant and benign masses on mammograms. With a finite available data set, we simulated a training set containing corrupted data or noisy labels. The balance between learning and memorization of the DCNN was manipulated by varying the proportion of corrupted data in the training set. The generalization error of DCNN was analyzed by the area under the receiver operating characteristic curve for the training and test sets and the weight changes after transfer learning. The study demonstrates that the transfer learning strategy of DCNN for such tasks needs to be designed properly, taking into consideration the constraints of the available training set having limited size and quality for the classification task at hand, to minimize memorization and improve generalizability.
Figures






References
-
- Byra M, Styczynski G, Szmigielski C, Kalinowski P, Michałowski Ł, Paluszkiewicz R, Ziarkiewicz-Wróblewska B, Zieniewicz K, Sobieraj P and Nowicki A 2018. Transfer learning with deep convolutional neural network for liver steatosis assessment in ultrasound images Int J Comput Ass Rad 13 1895–903 - PMC - PubMed
-
- Chan H-P, Lo S C, Helvie M, Goodsitt M M, Cheng S N C and Adler D D 1993. Recognition of mammographic microcalcifications with artificial neural network Radiology 189(P) 318
-
- Chan H-P, Lo S C B, Sahiner B, Lam K L and Helvie M A 1995a. Computer-aided detection of mammographic microcalcifications: Pattern recognition with an artificial neural network Medical Physics 22 1555–67 - PubMed
-
- Chan H-P, Sahiner B, Lo S C, Helvie M, Petrick N, Adler D D and Goodsitt M M 1994. Computer-aided diagnosis in mammography: detection of masses by artificial neural network Medical Physics 21 875–6
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous