

Unconstrained genome targeting with near-PAMless engineered CRISPR-Cas9 variants
- PMID: 32217751
- PMCID: PMC7297043
- DOI: 10.1126/science.aba8853
Unconstrained genome targeting with near-PAMless engineered CRISPR-Cas9 variants
Abstract
Manipulation of DNA by CRISPR-Cas enzymes requires the recognition of a protospacer-adjacent motif (PAM), limiting target site recognition to a subset of sequences. To remove this constraint, we engineered variants of Streptococcus pyogenes Cas9 (SpCas9) to eliminate the NGG PAM requirement. We developed a variant named SpG that is capable of targeting an expanded set of NGN PAMs, and we further optimized this enzyme to develop a near-PAMless SpCas9 variant named SpRY (NRN and to a lesser extent NYN PAMs). SpRY nuclease and base-editor variants can target almost all PAMs, exhibiting robust activities on a wide range of sites with NRN PAMs in human cells and lower but substantial activity on those with NYN PAMs. Using SpG and SpRY, we generated previously inaccessible disease-relevant genetic variants, supporting the utility of high-resolution targeting across genome editing applications.
Copyright © 2020 The Authors, some rights reserved; exclusive licensee American Association for the Advancement of Science. No claim to original U.S. Government Works.
Figures
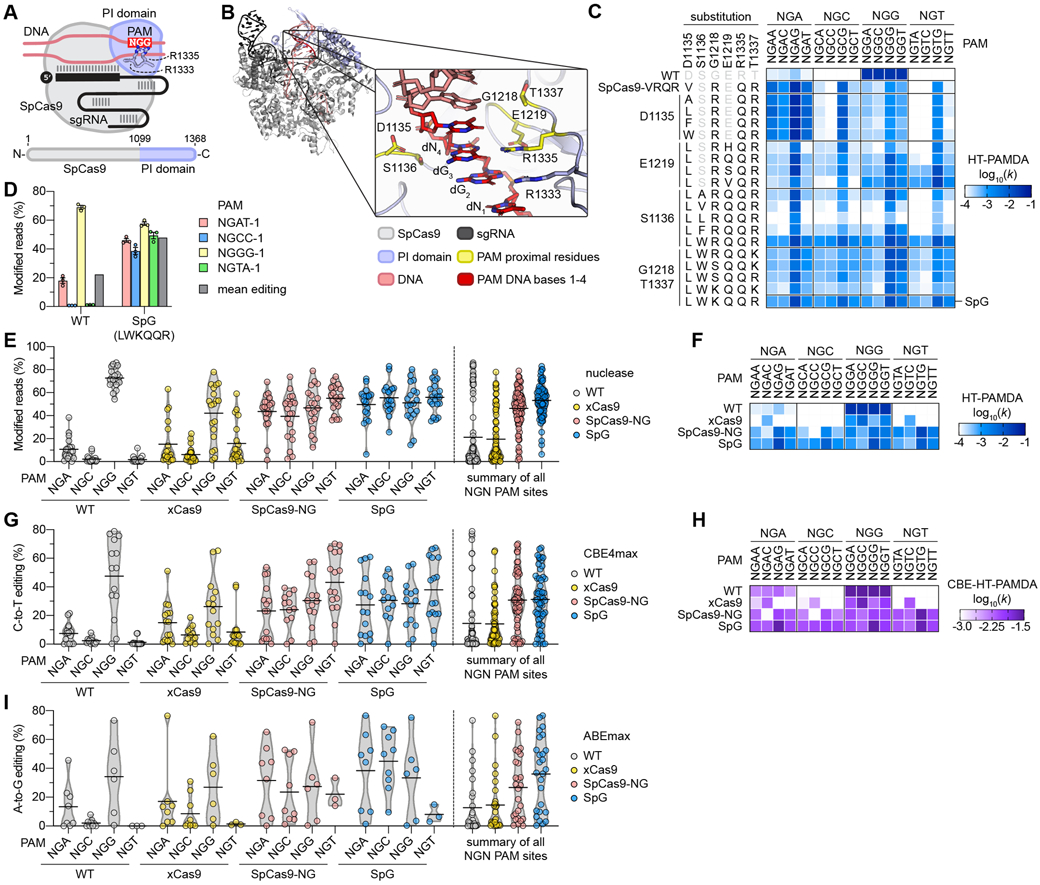
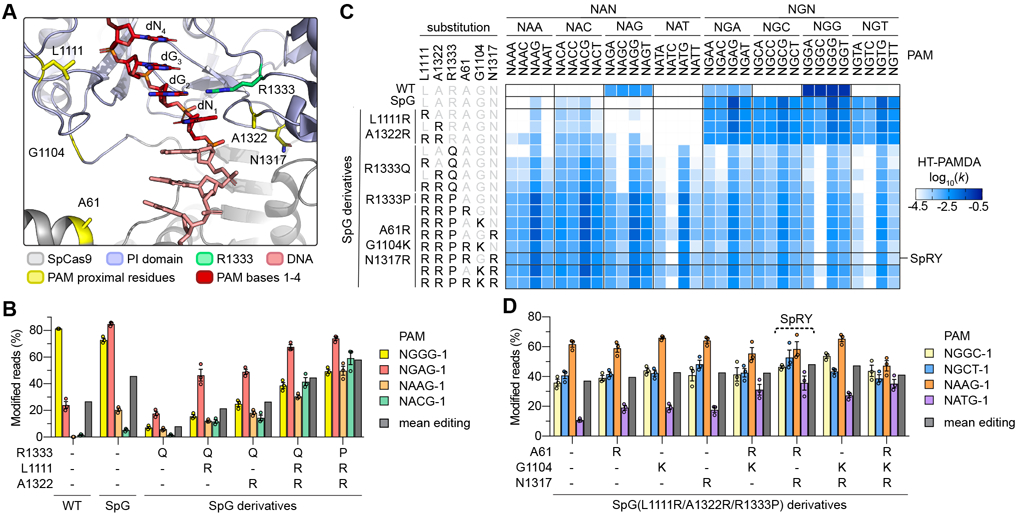
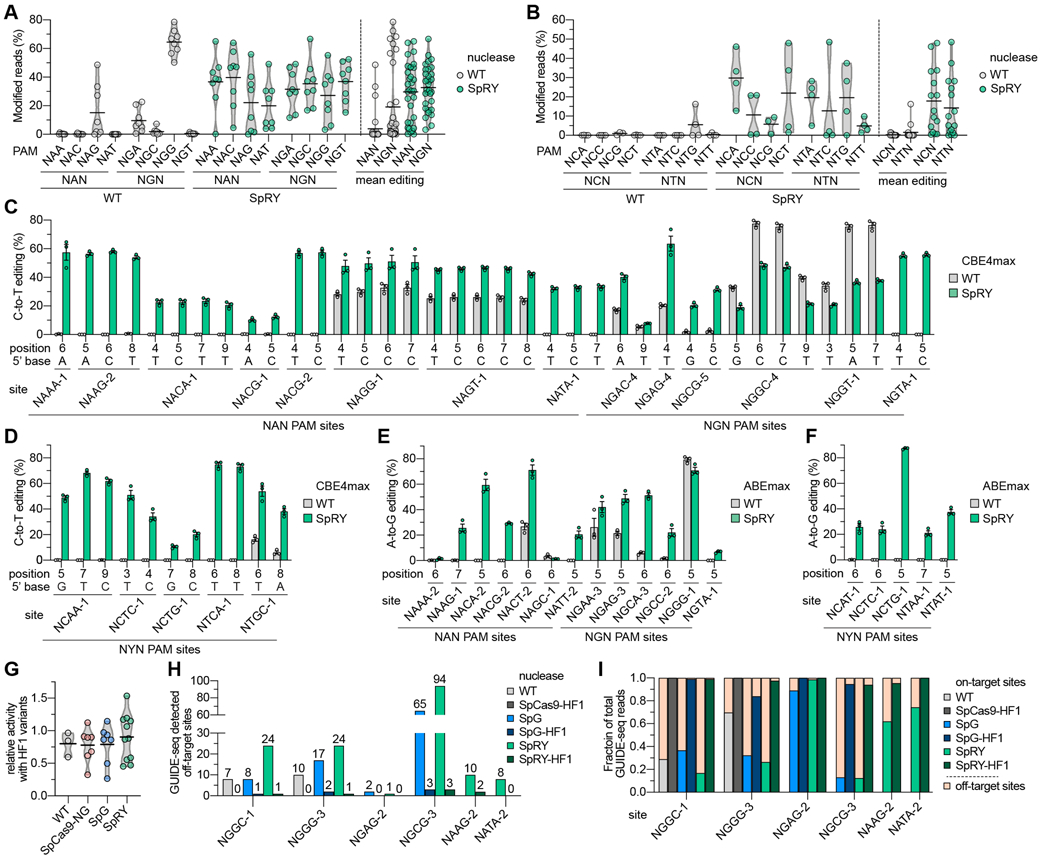
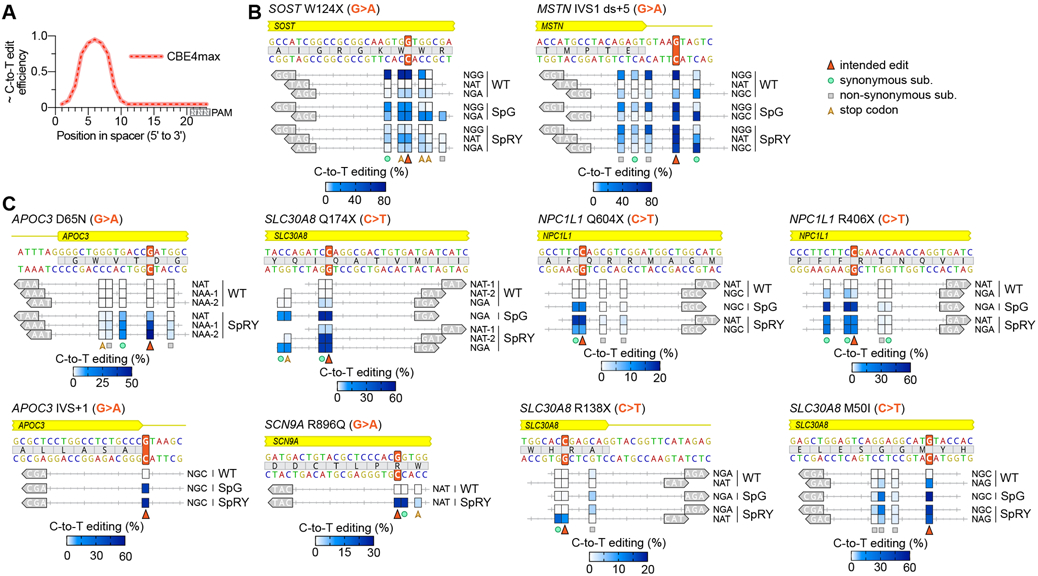
Comment in
-
Rewired Cas9s with Minimal Sequence Constraints.Trends Pharmacol Sci. 2020 Jul;41(7):429-431. doi: 10.1016/j.tips.2020.04.009. Epub 2020 May 13. Trends Pharmacol Sci. 2020. PMID: 32416935
-
SpRY: Engineered CRISPR/Cas9 Harnesses New Genome-Editing Power.Trends Genet. 2020 Aug;36(8):546-548. doi: 10.1016/j.tig.2020.05.001. Epub 2020 May 23. Trends Genet. 2020. PMID: 32456805
-
PAM-less is more.Nat Methods. 2020 Jun;17(6):559. doi: 10.1038/s41592-020-0861-5. Nat Methods. 2020. PMID: 32499620 No abstract available.
References
-
- Mojica FJM, Díez-Villaseñor C, García-Martínez J, Almendros C, Short motif sequences determine the targets of the prokaryotic CRISPR defence system. Microbiol Read Engl. 155, 733–40 (2009). - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
Miscellaneous
