

Scene Graph Prediction with Limited Labels
- PMID: 32218709
- PMCID: PMC7098690
- DOI: 10.1109/iccv.2019.00267
Scene Graph Prediction with Limited Labels
Abstract
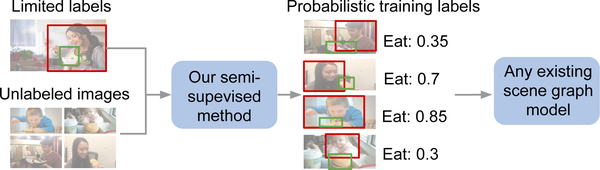
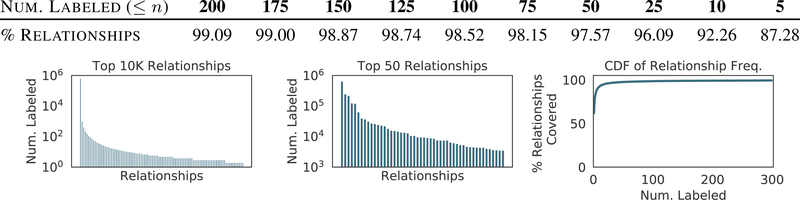
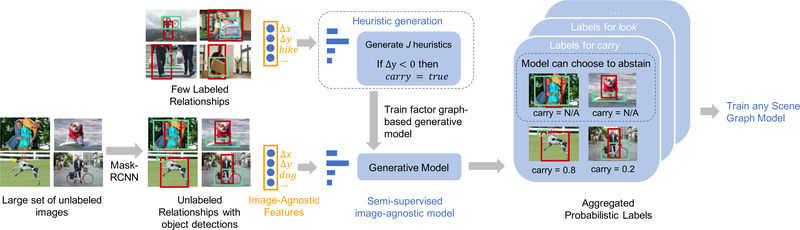
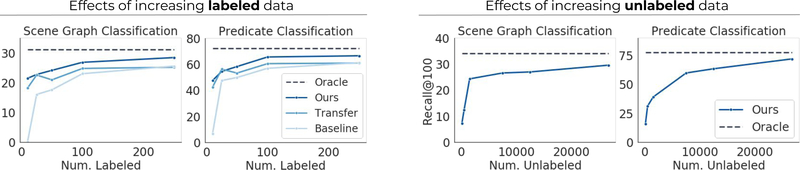
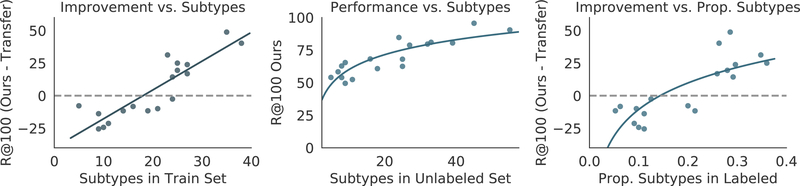
Visual knowledge bases such as Visual Genome power numerous applications in computer vision, including visual question answering and captioning, but suffer from sparse, incomplete relationships. All scene graph models to date are limited to training on a small set of visual relationships that have thousands of training labels each. Hiring human annotators is expensive, and using textual knowledge base completion methods are incompatible with visual data. In this paper, we introduce a semi-supervised method that assigns probabilistic relationship labels to a large number of unlabeled images using few' labeled examples. We analyze visual relationships to suggest two types of image-agnostic features that are used to generate noisy heuristics, whose outputs are aggregated using a factor graph-based generative model. With as few as 10 labeled examples per relationship, the generative model creates enough training data to train any existing state-of-the-art scene graph model. We demonstrate that our method outperforms all baseline approaches on scene graph prediction by 5.16 recall@ 100 for PREDCLS. In our limited label setting, we define a complexity metric for relationships that serves as an indicator (R2 = 0.778) for conditions under which our method succeeds over transfer learning, the de-facto approach for training with limited labels.
Figures




References
-
- Alfonseca Enrique, Filippova Katja, Delort Jean-Yves, and Garrido Guillermo. Pattern learning for relation extraction with a hierarchical topic model. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short Papers-Volume 2, pages 54–59. Association for Computational Linguistics, 2012. 5
-
- Anderson Carolyn J, Wasserman Stanley, and Faust Katherine. Building stochastic blockmodels. Social networks, 14(1– 2):137–161, 1992. 2
-
- Anderson Peter, Fernando Basura, Johnson Mark, and Gould Stephen. Spice: Semantic propositional image caption evaluation. In European Conference on Computer Vision, pages 382–398. Springer, 2016. 1
-
- Auer Sören, Bizer Christian, Kobilarov Georgi, Lehmann Jens, Cyganiak Richard, and Ives Zachary. Dbpedia: A nucleus for a web of open data In The semantic web, pages 722–735. Springer, 2007. 2
-
- Bollacker Kurt, Evans Colin, Paritosh Praveen, Sturge Tim, and Taylor Jamie. Freebase: a collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data, pages 1247–1250. AcM, 2008. 2
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources