

Toward Community-Driven Big Open Brain Science: Open Big Data and Tools for Structure, Function, and Genetics
- PMID: 32283996
- PMCID: PMC9119703
- DOI: 10.1146/annurev-neuro-100119-110036
Toward Community-Driven Big Open Brain Science: Open Big Data and Tools for Structure, Function, and Genetics
Abstract
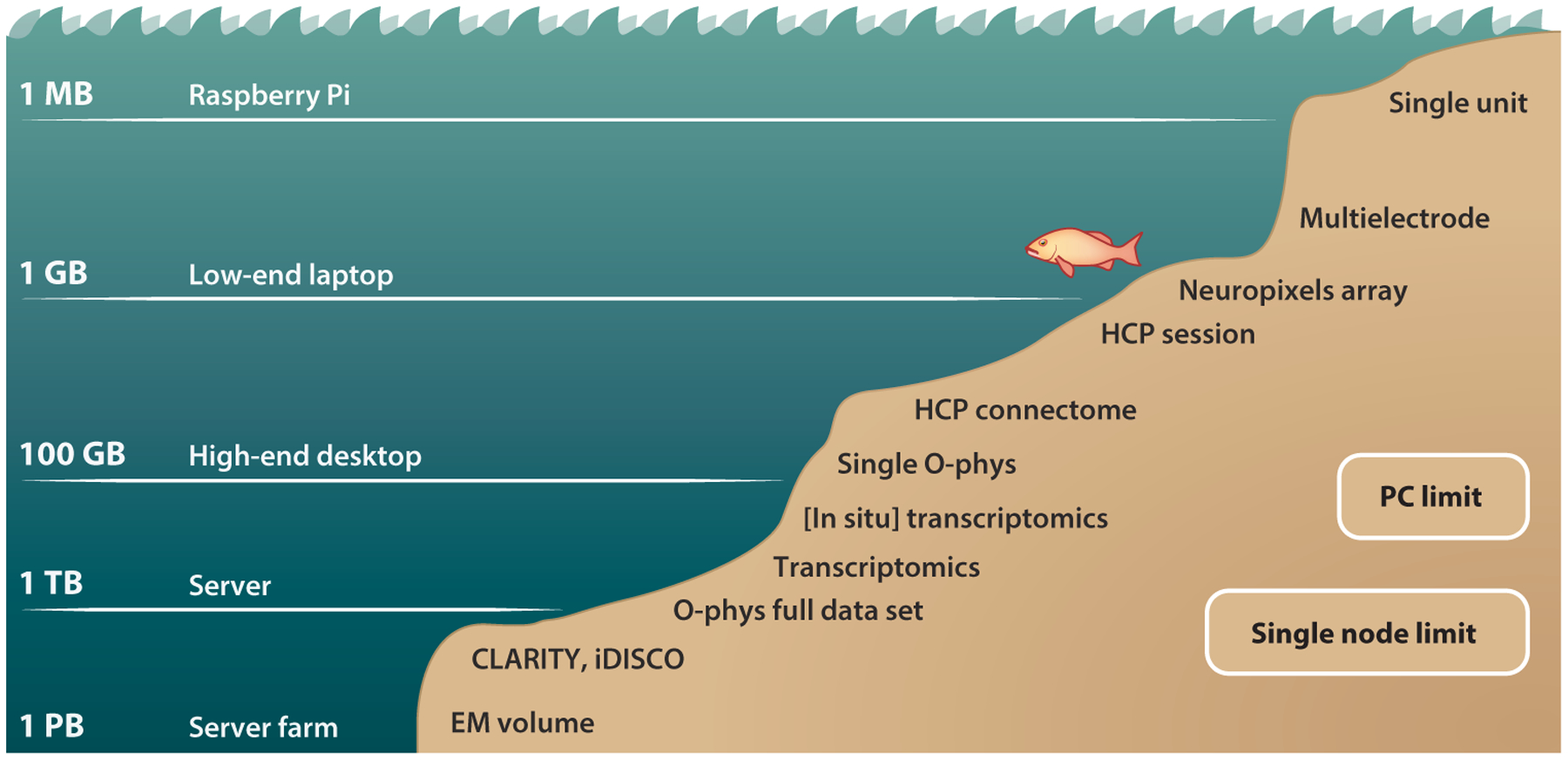
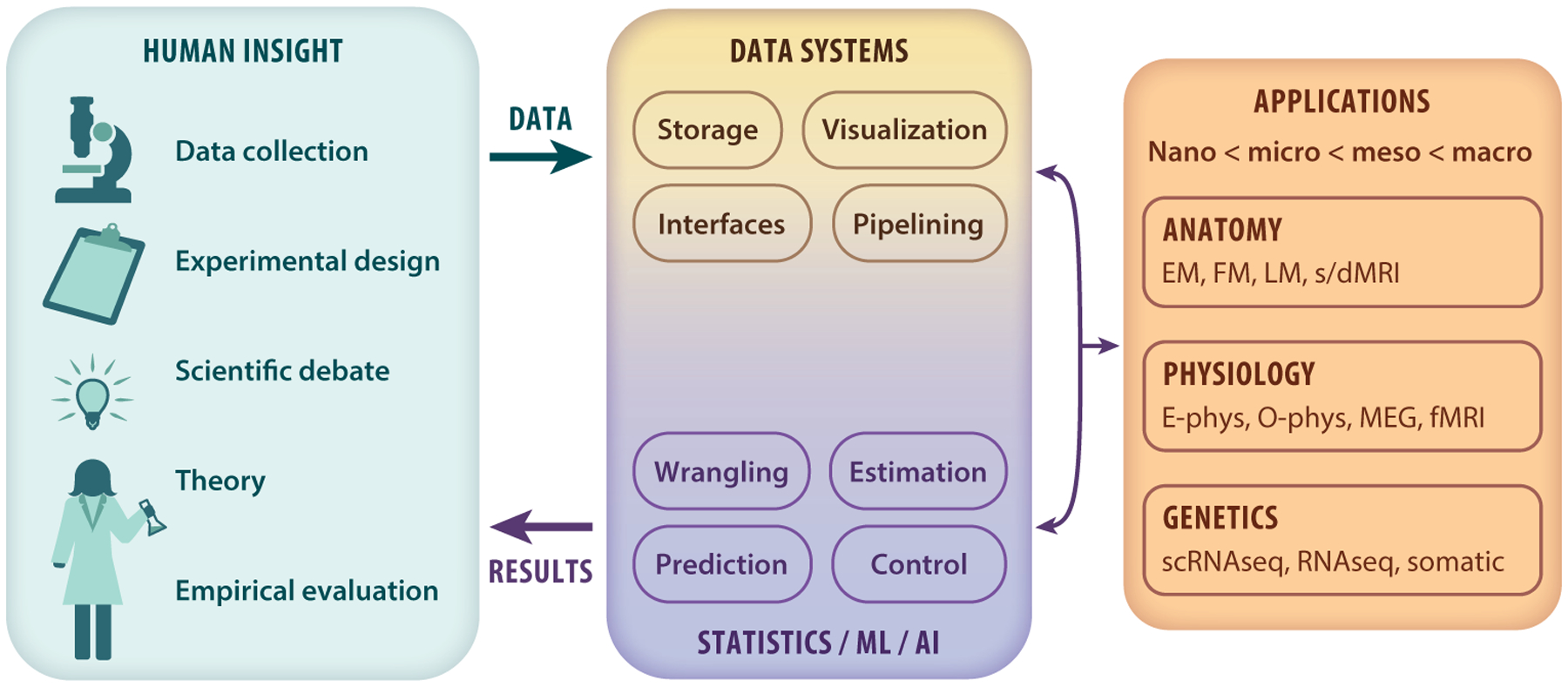
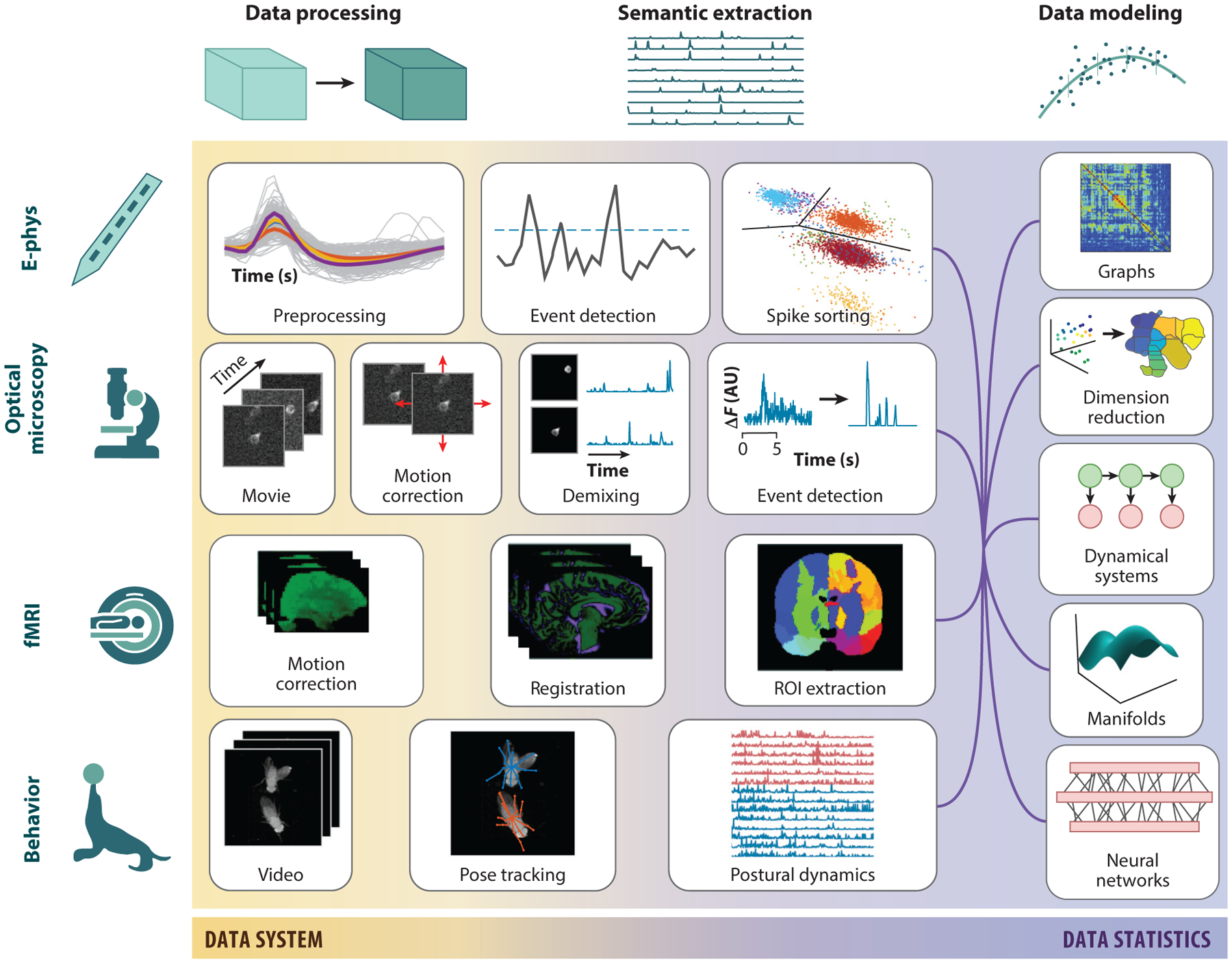
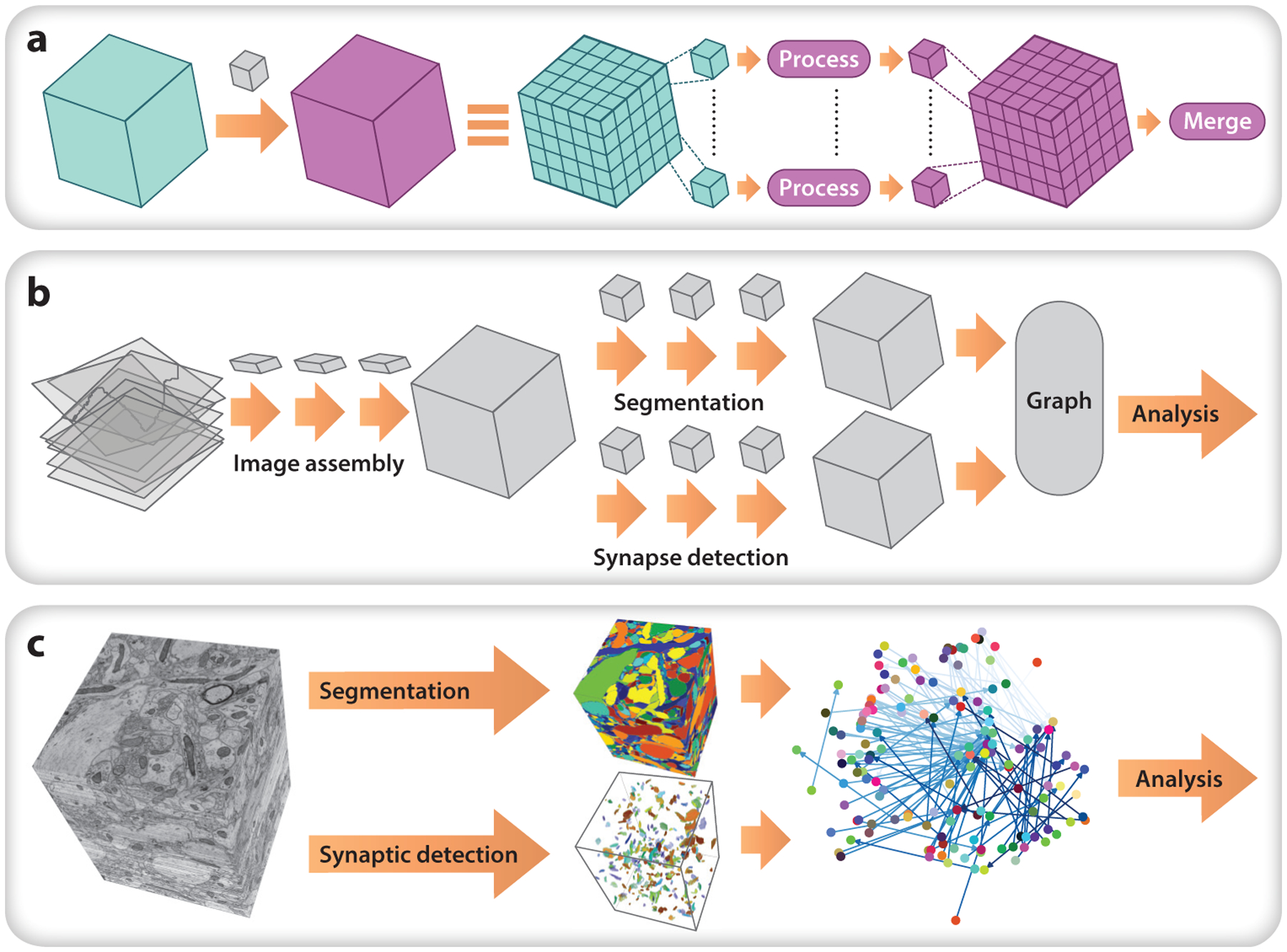
As acquiring bigger data becomes easier in experimental brain science, computational and statistical brain science must achieve similar advances to fully capitalize on these data. Tackling these problems will benefit from a more explicit and concerted effort to work together. Specifically, brain science can be further democratized by harnessing the power of community-driven tools, which both are built by and benefit from many different people with different backgrounds and expertise. This perspective can be applied across modalities and scales and enables collaborations across previously siloed communities.
Keywords: computational; infrastructure; reference data; statistics.
Figures
References
-
- Athreya A, Fishkind DE, Tang M, Priebe CE, Park Y, et al. 2017. Statistical inference on random dot product graphs: a survey. J. Mach. Learn. Res 18(226):1–92
-
- Au OK-C, Tai C-L, Chu H-K, Cohen-Or D, Lee T-Y. 2008. Skeleton extraction by mesh contraction. ACM Trans. Graph 27(3):1–10
-
- Ba J, Caruana R. 2014. Do deep nets really need to be deep? In Advances in Neural Information Processing Systems 27, ed. Ghahramani Z, Welling M, Cortes C, Lawrence ND, Weinberger KQ, pp. 2654–62. San Diego, CA: NeurIPS
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
