

Dimensionality, information and learning in prefrontal cortex
- PMID: 32330126
- PMCID: PMC7202668
- DOI: 10.1371/journal.pcbi.1007514
Dimensionality, information and learning in prefrontal cortex
Abstract
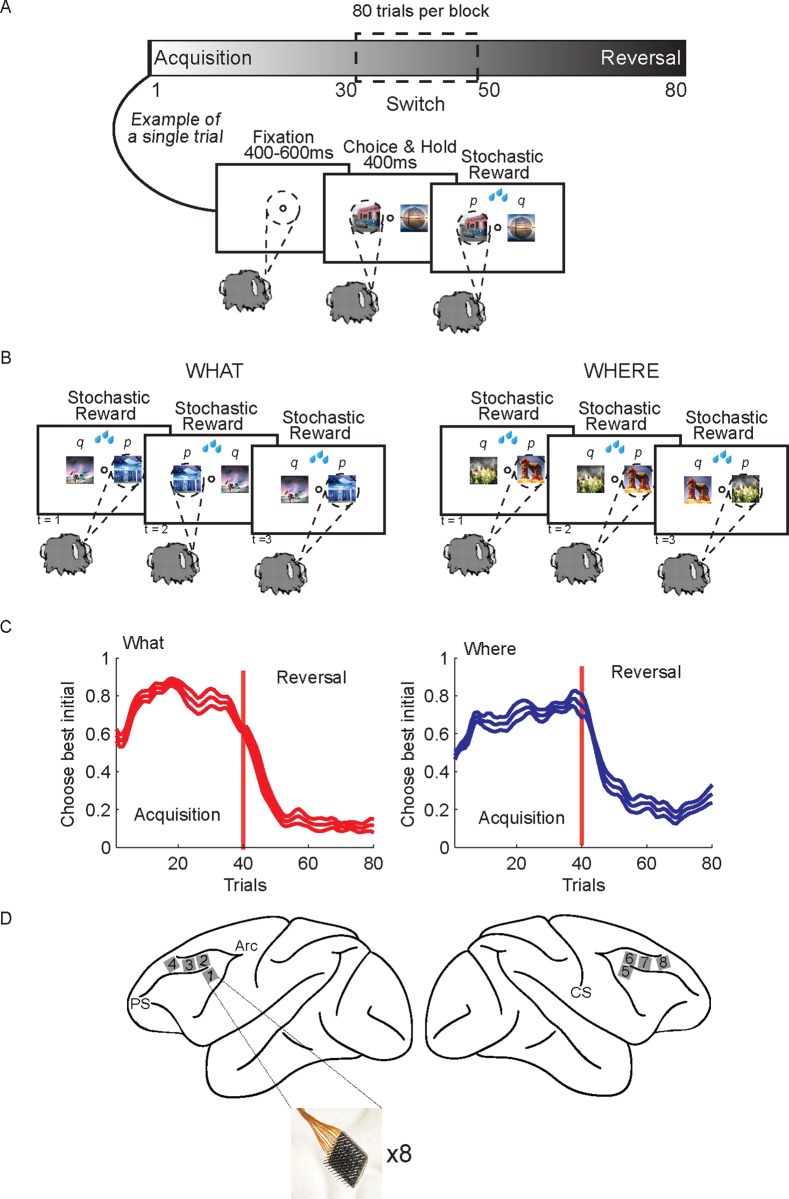
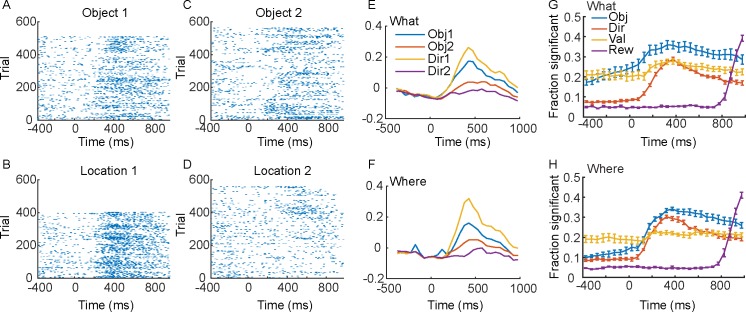
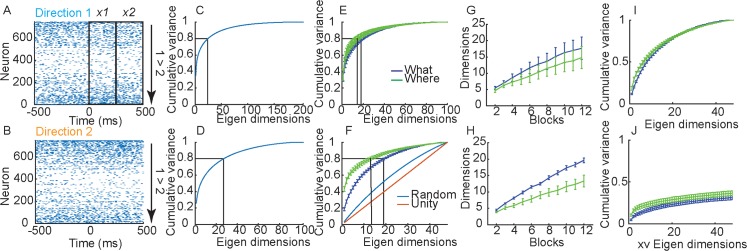
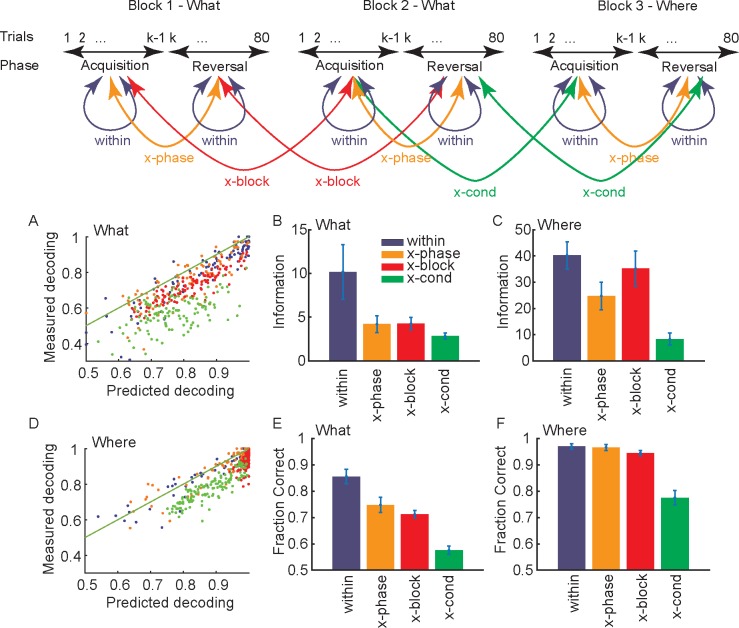
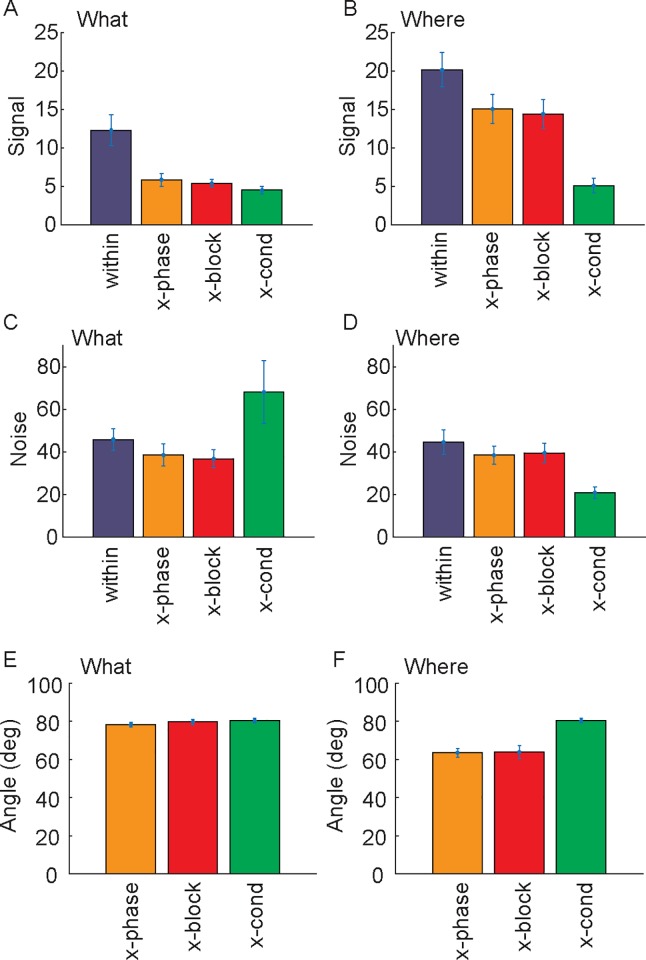
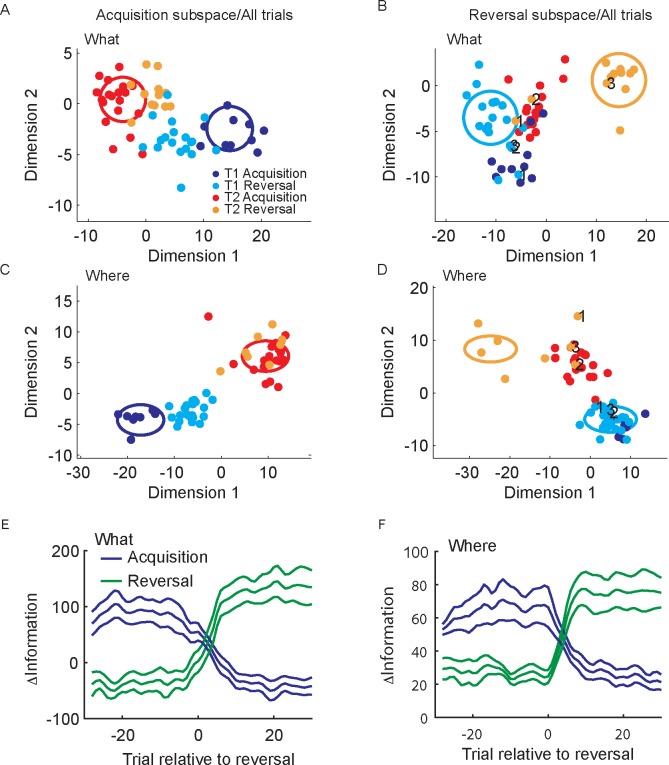
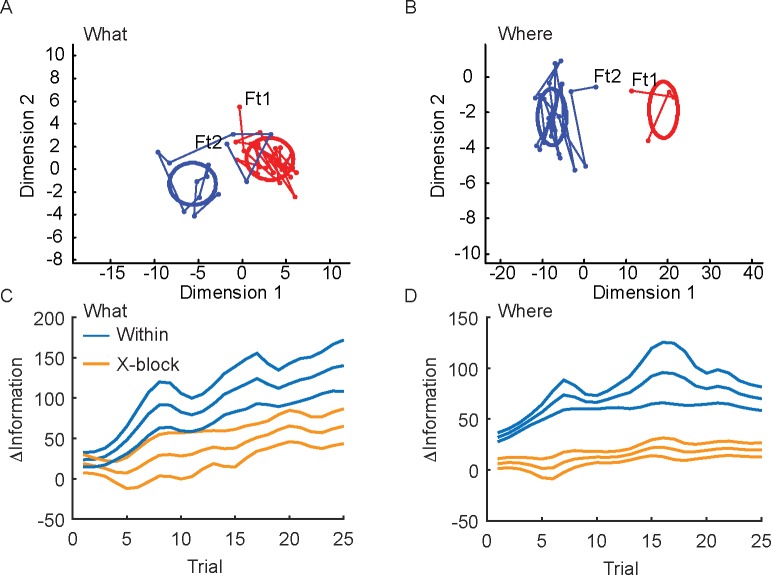
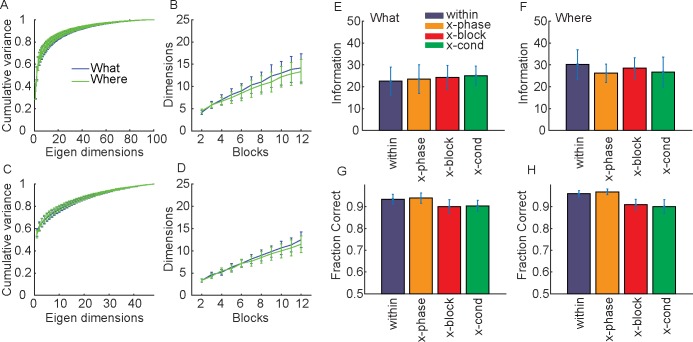
Learning leads to changes in population patterns of neural activity. In this study we wanted to examine how these changes in patterns of activity affect the dimensionality of neural responses and information about choices. We addressed these questions by carrying out high channel count recordings in dorsal-lateral prefrontal cortex (dlPFC; 768 electrodes) while monkeys performed a two-armed bandit reinforcement learning task. The high channel count recordings allowed us to study population coding while monkeys learned choices between actions or objects. We found that the dimensionality of neural population activity was higher across blocks in which animals learned the values of novel pairs of objects, than across blocks in which they learned the values of actions. The increase in dimensionality with learning in object blocks was related to less shared information across blocks, and therefore patterns of neural activity that were less similar, when compared to learning in action blocks. Furthermore, these differences emerged with learning, and were not a simple function of the choice of a visual image or action. Therefore, learning the values of novel objects increases the dimensionality of neural representations in dlPFC.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
-
- Sejnowski TJ. Neural populations revealed. Nature. 1988;332(24):308. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
