

Data-driven classification of the certainty of scholarly assertions
- PMID: 32341891
- PMCID: PMC7182025
- DOI: 10.7717/peerj.8871
Data-driven classification of the certainty of scholarly assertions
Abstract
The grammatical structures scholars use to express their assertions are intended to convey various degrees of certainty or speculation. Prior studies have suggested a variety of categorization systems for scholarly certainty; however, these have not been objectively tested for their validity, particularly with respect to representing the interpretation by the reader, rather than the intention of the author. In this study, we use a series of questionnaires to determine how researchers classify various scholarly assertions, using three distinct certainty classification systems. We find that there are three distinct categories of certainty along a spectrum from high to low. We show that these categories can be detected in an automated manner, using a machine learning model, with a cross-validation accuracy of 89.2% relative to an author-annotated corpus, and 82.2% accuracy against a publicly-annotated corpus. This finding provides an opportunity for contextual metadata related to certainty to be captured as a part of text-mining pipelines, which currently miss these subtle linguistic cues. We provide an exemplar machine-accessible representation-a Nanopublication-where certainty category is embedded as metadata in a formal, ontology-based manner within text-mined scholarly assertions.
Keywords: Certainty; FAIR Data; Machine learning; Scholarly communication; Text mining.
©2020 Prieto et al.
Conflict of interest statement
Helena Deus is employed by Elsevier Inc. Anita de Waard is Vice President, Research Data Collaborations at Elsevier. Erik Schultes is employed by the GO FAIR International Support and Coordination Office.
Figures



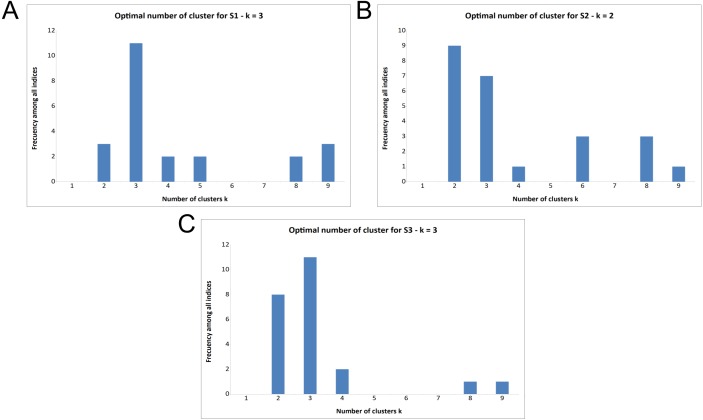



References
-
- Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z, Citro C, Corrado GS, Davis A, Dean J, Devin M, Ghemawat S, Goodfellow IJ, Harp A, Irving G, Isard M, Jia Y, Józefowicz R, Kaiser L, Kudlur M, Levenberg J, Mané D, Monga R, Moore S, Murray DG, Olah C, Schuster M, Shlens J, Steiner B, Sutskever I, Talwar K, Tucker PA, Vanhoucke V, Vasudevan V, Viégas FB, Vinyals O, Warden P, Wattenberg M, Wicke M, Yu Y, Zheng X. TensorFlow: large-scale machine learning on heterogeneous distributed systems. CoRR. 2016 abs/1603.04467.
-
- Baxter MJ. Standardization and transformation in principal component analysis, with applications to archaeometry. Applied Statistics; 1995.
-
- Baziotis C, Pelekis N, Doulkeridis C. Datastories at semeval-2017 task 4: deep lstm with attention for message-level and topic-based sentiment analysis. Proceedings of the 11th international workshop on semantic evaluation (SemEval-2017); 2017. pp. 747–754.
LinkOut - more resources
Full Text Sources
