

BEHRT: Transformer for Electronic Health Records
- PMID: 32346050
- PMCID: PMC7189231
- DOI: 10.1038/s41598-020-62922-y
BEHRT: Transformer for Electronic Health Records
Abstract
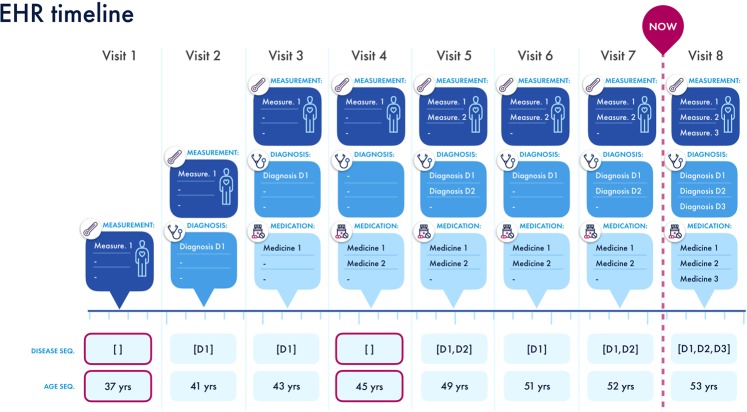
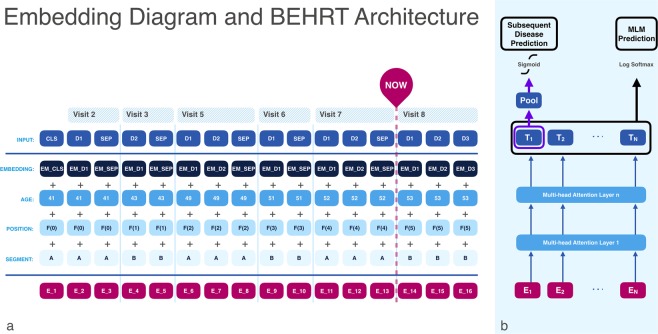
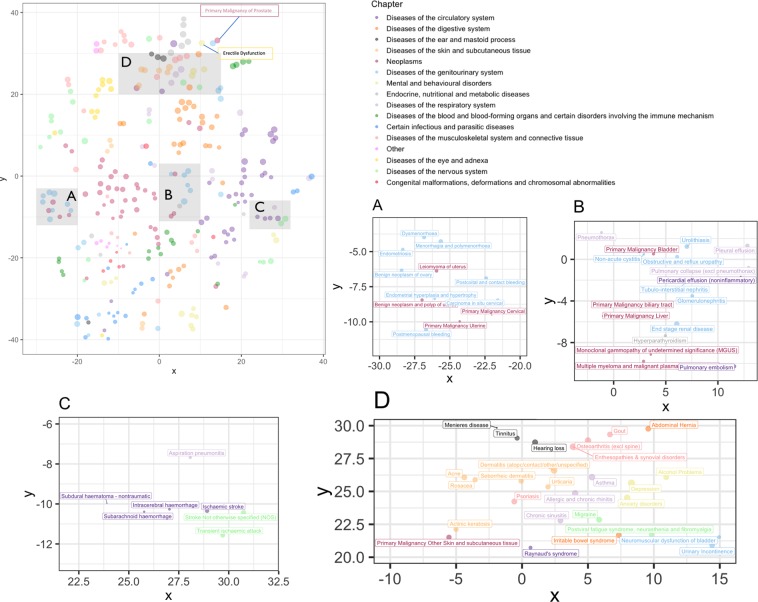
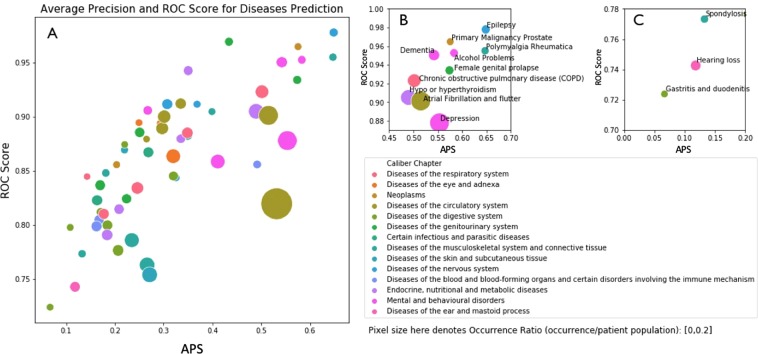
Today, despite decades of developments in medicine and the growing interest in precision healthcare, vast majority of diagnoses happen once patients begin to show noticeable signs of illness. Early indication and detection of diseases, however, can provide patients and carers with the chance of early intervention, better disease management, and efficient allocation of healthcare resources. The latest developments in machine learning (including deep learning) provides a great opportunity to address this unmet need. In this study, we introduce BEHRT: A deep neural sequence transduction model for electronic health records (EHR), capable of simultaneously predicting the likelihood of 301 conditions in one's future visits. When trained and evaluated on the data from nearly 1.6 million individuals, BEHRT shows a striking improvement of 8.0-13.2% (in terms of average precision scores for different tasks), over the existing state-of-the-art deep EHR models. In addition to its scalability and superior accuracy, BEHRT enables personalised interpretation of its predictions; its flexible architecture enables it to incorporate multiple heterogeneous concepts (e.g., diagnosis, medication, measurements, and more) to further improve the accuracy of its predictions; its (pre-)training results in disease and patient representations can be useful for future studies (i.e., transfer learning).
Conflict of interest statement
The authors declare no competing interests.
Figures


References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
