

FetNet: a recurrent convolutional network for occlusion identification in fetoscopic videos
- PMID: 32350787
- PMCID: PMC7261278
- DOI: 10.1007/s11548-020-02169-0
FetNet: a recurrent convolutional network for occlusion identification in fetoscopic videos
Abstract
Purpose: Fetoscopic laser photocoagulation is a minimally invasive surgery for the treatment of twin-to-twin transfusion syndrome (TTTS). By using a lens/fibre-optic scope, inserted into the amniotic cavity, the abnormal placental vascular anastomoses are identified and ablated to regulate blood flow to both fetuses. Limited field-of-view, occlusions due to fetus presence and low visibility make it difficult to identify all vascular anastomoses. Automatic computer-assisted techniques may provide better understanding of the anatomical structure during surgery for risk-free laser photocoagulation and may facilitate in improving mosaics from fetoscopic videos.
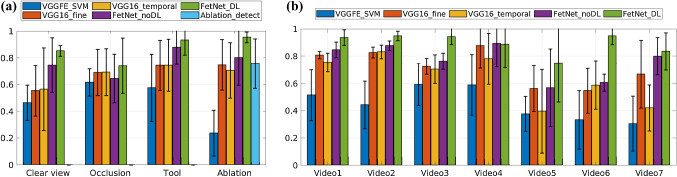
Methods: We propose FetNet, a combined convolutional neural network (CNN) and long short-term memory (LSTM) recurrent neural network architecture for the spatio-temporal identification of fetoscopic events. We adapt an existing CNN architecture for spatial feature extraction and integrated it with the LSTM network for end-to-end spatio-temporal inference. We introduce differential learning rates during the model training to effectively utilising the pre-trained CNN weights. This may support computer-assisted interventions (CAI) during fetoscopic laser photocoagulation.
Results: We perform quantitative evaluation of our method using 7 in vivo fetoscopic videos captured from different human TTTS cases. The total duration of these videos was 5551 s (138,780 frames). To test the robustness of the proposed approach, we perform 7-fold cross-validation where each video is treated as a hold-out or test set and training is performed using the remaining videos.
Conclusion: FetNet achieved superior performance compared to the existing CNN-based methods and provided improved inference because of the spatio-temporal information modelling. Online testing of FetNet, using a Tesla V100-DGXS-32GB GPU, achieved a frame rate of 114 fps. These results show that our method could potentially provide a real-time solution for CAI and automating occlusion and photocoagulation identification during fetoscopic procedures.
Keywords: Computer assisted interventions (CAI); Deep learning; Fetoscopy; Surgical vision; Twin-to-twin transfusion syndrome (TTTS); Video segmentation.
Conflict of interest statement
The authors declare that they have no conflict of interest.
Figures




References
-
- Bahdanau D, Cho K, Bengio Y (2015) A theoretical analysis of feature pooling in visual recognition. In: Proceedings of the international conference on learning representations
-
- Bano Sophia, Vasconcelos Francisco, Tella Amo Marcel, Dwyer George, Gruijthuijsen Caspar, Deprest Jan, Ourselin Sebastien, Vander Poorten Emmanuel, Vercauteren Tom, Stoyanov Danail. Lecture Notes in Computer Science. Cham: Springer International Publishing; 2019. Deep Sequential Mosaicking of Fetoscopic Videos; pp. 311–319.
-
- Baschat A, Chmait RH, Deprest J, Gratacós E, Hecher K, Kontopoulos E, Quintero R, Skupski DW, Valsky DV, Ville Y. Twin-to-twin transfusion syndrome (TTTS) J Perinat Med. 2011;39(2):107–112. - PubMed
-
- Cadene R, Robert T, Thome N, Cord M (2016) M2cai workflow challenge: convolutional neural networks with time smoothing and hidden Markov model for video frames classification. arXiv preprint arXiv:1610.05541
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
