

Reinforcement learning as an intermediate phenotype in psychosis? Deficits sensitive to illness stage but not associated with polygenic risk of schizophrenia in the general population
- PMID: 32389614
- PMCID: PMC7594641
- DOI: 10.1016/j.schres.2020.04.022
Reinforcement learning as an intermediate phenotype in psychosis? Deficits sensitive to illness stage but not associated with polygenic risk of schizophrenia in the general population
Abstract
Background: Schizophrenia is a complex disorder in which the causal relations between risk genes and observed clinical symptoms are not well understood and the explanatory gap is too wide to be clarified without considering an intermediary level. Thus, we aimed to test the hypothesis of a pathway from molecular polygenic influence to clinical presentation occurring via deficits in reinforcement learning.
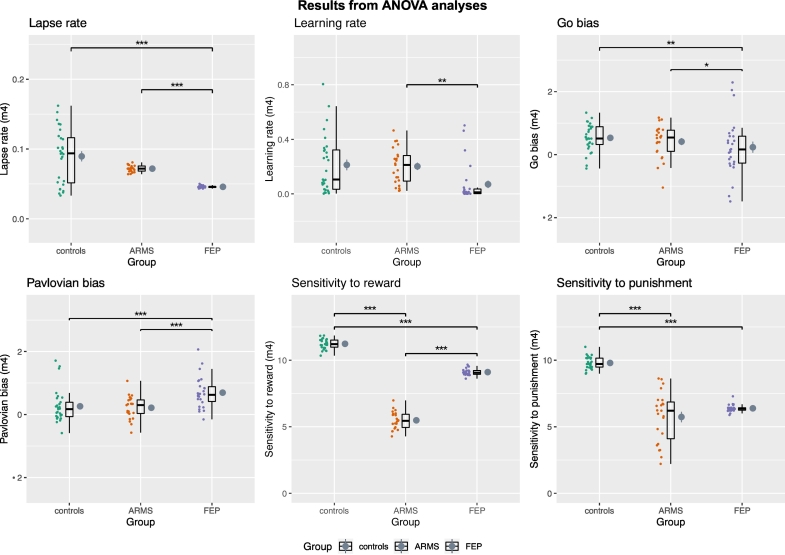
Methods: We administered a reinforcement learning task (Go/NoGo) that measures reinforcement learning and the effect of Pavlovian bias on decision making. We modelled the behavioural data with a hierarchical Bayesian approach (hBayesDM) to decompose task performance into its underlying learning mechanisms. Study 1 included controls (n = 29, F|M = 0.81), At Risk Mental State for psychosis (ARMS, n = 23, F|M = 0.35) and FEP (First-episode psychosis, n = 26, F|M = 0.18). Study 2 included healthy adolescents (n = 735, F|M = 1.06), 390 of whom had their polygenic risk scores for schizophrenia (PRSs) calculated.
Results: Patients with FEP showed significant impairments in overriding Pavlovian conflict, a lower learning rate and a lower sensitivity to both reward and punishment. Less widespread deficits were observed in ARMS. PRSs did not significantly predict performance on the task in the general population, which only partially correlated with measures of psychopathology.
Conclusions: Reinforcement learning deficits are observed in first episode psychosis and, to some extent, in those at clinical risk for psychosis, and were not predicted by molecular genetic risk for schizophrenia in healthy individuals. The study does not support the role of reinforcement learning as an intermediate phenotype in psychosis.
Keywords: Bayesian; Computational psychiatry; Go/NoGo task; PRS; Psychosis; Reinforcement learning; Schizophrenia.
Copyright © 2020 The Authors. Published by Elsevier B.V. All rights reserved.
Figures


References
-
- Ahn W., Haines N., Zhang L. hBayesDM Reference Manual. 2018. https://cran.r-project.org/web/packages/hBayesDM/hBayesDM.pdf [online] Cran.r-project.org.
-
- Benjamini Y., Hochberg Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B Methodol. 1995;57(1):289–300.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous
