

Extending the small-molecule similarity principle to all levels of biology with the Chemical Checker
- PMID: 32440005
- PMCID: PMC7616951
- DOI: 10.1038/s41587-020-0502-7
Extending the small-molecule similarity principle to all levels of biology with the Chemical Checker
Erratum in
-
Publisher Correction: Extending the small-molecule similarity principle to all levels of biology with the Chemical Checker.Nat Biotechnol. 2020 Sep;38(9):1098. doi: 10.1038/s41587-020-0564-6. Nat Biotechnol. 2020. PMID: 32440008
Abstract
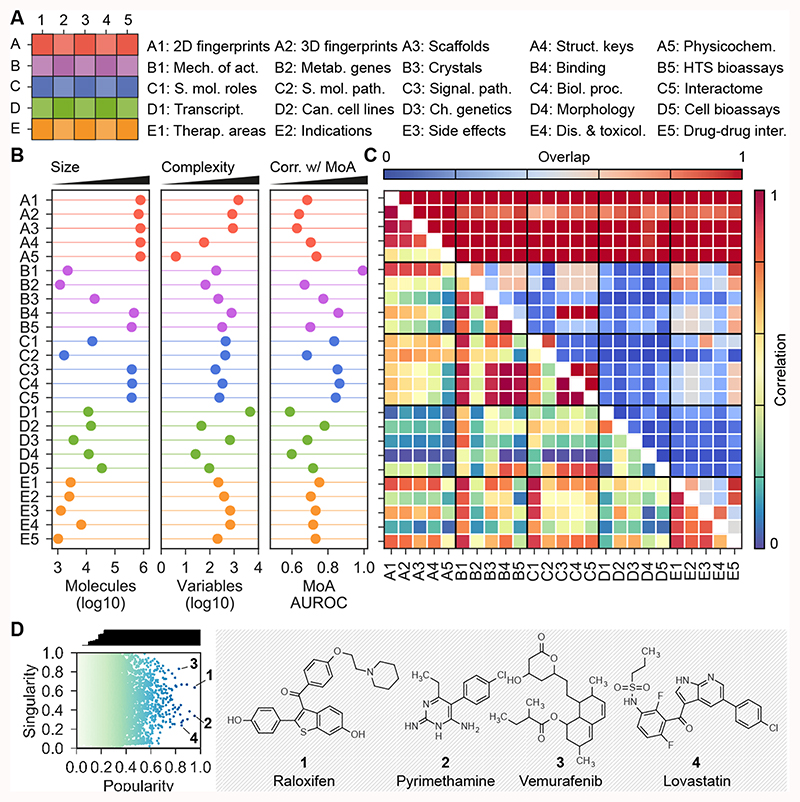
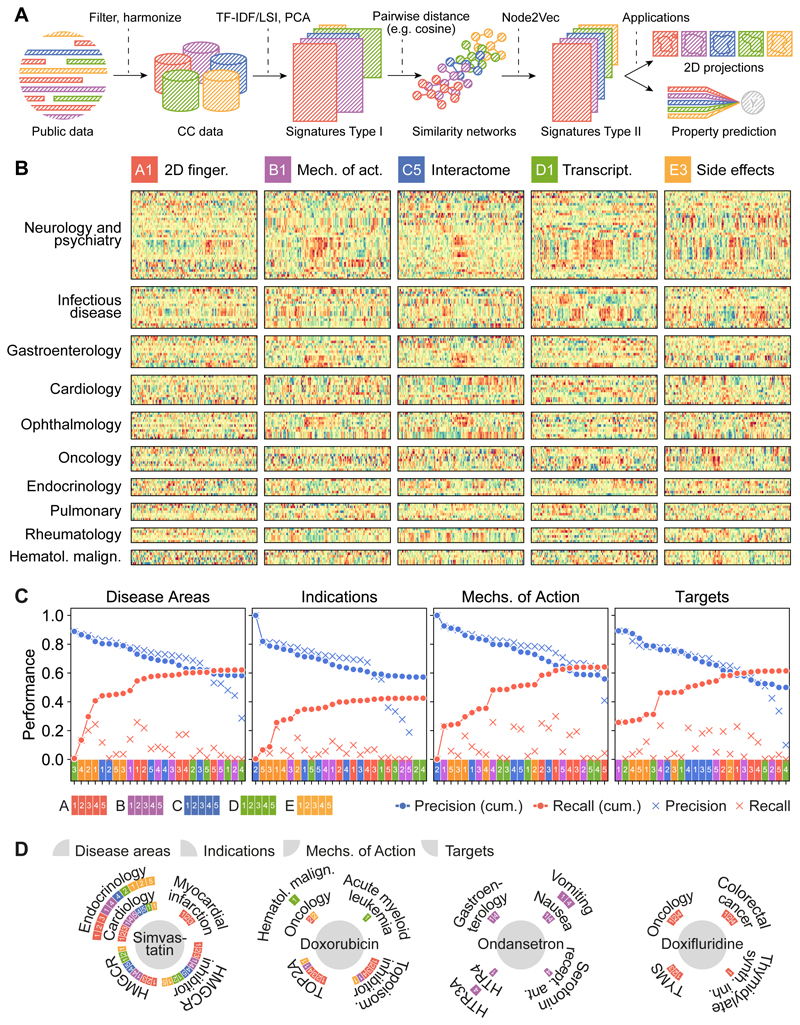
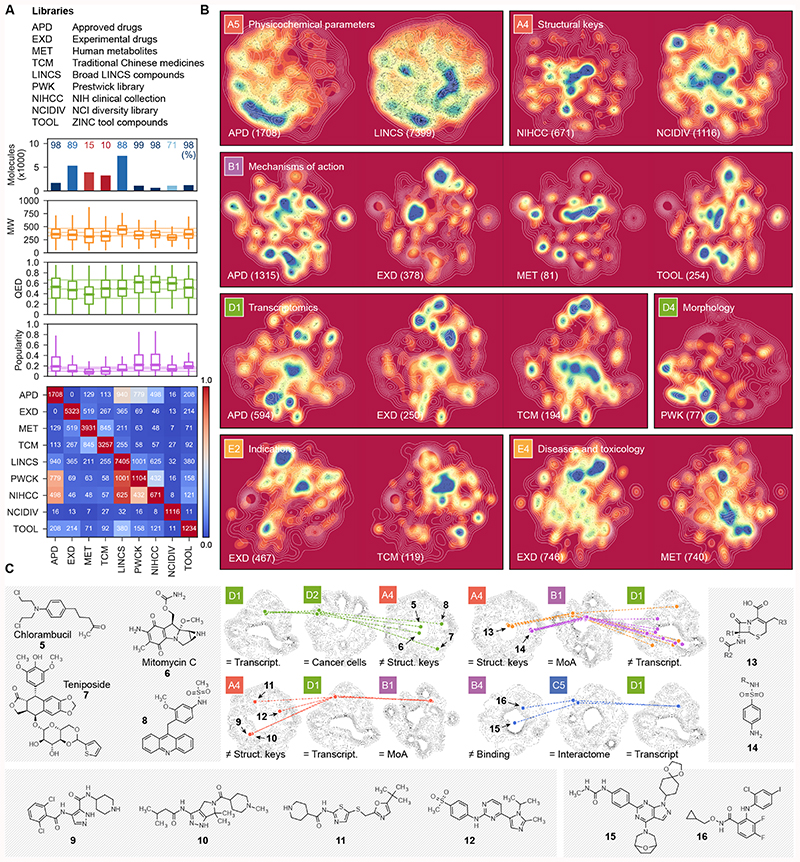
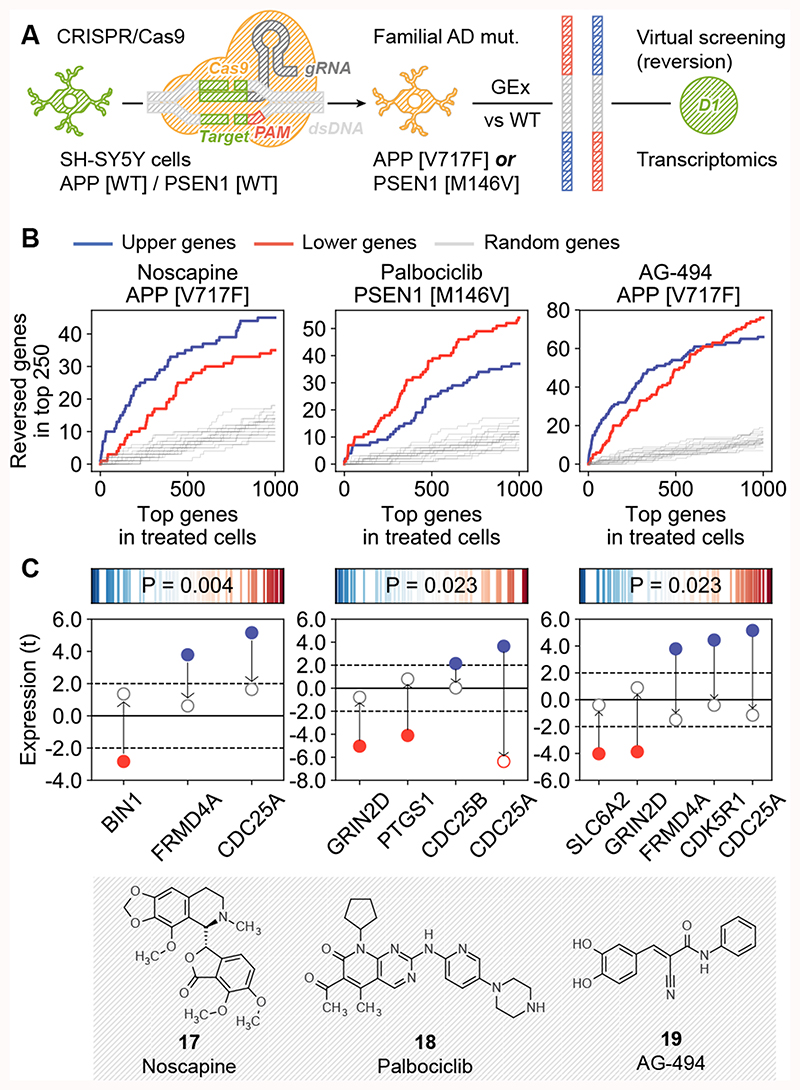
Small molecules are usually compared by their chemical structure, but there is no unified analytic framework for representing and comparing their biological activity. We present the Chemical Checker (CC), which provides processed, harmonized and integrated bioactivity data on ~800,000 small molecules. The CC divides data into five levels of increasing complexity, from the chemical properties of compounds to their clinical outcomes. In between, it includes targets, off-targets, networks and cell-level information, such as omics data, growth inhibition and morphology. Bioactivity data are expressed in a vector format, extending the concept of chemical similarity to similarity between bioactivity signatures. We show how CC signatures can aid drug discovery tasks, including target identification and library characterization. We also demonstrate the discovery of compounds that reverse and mimic biological signatures of disease models and genetic perturbations in cases that could not be addressed using chemical information alone. Overall, the CC signatures facilitate the conversion of bioactivity data to a format that is readily amenable to machine learning methods.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
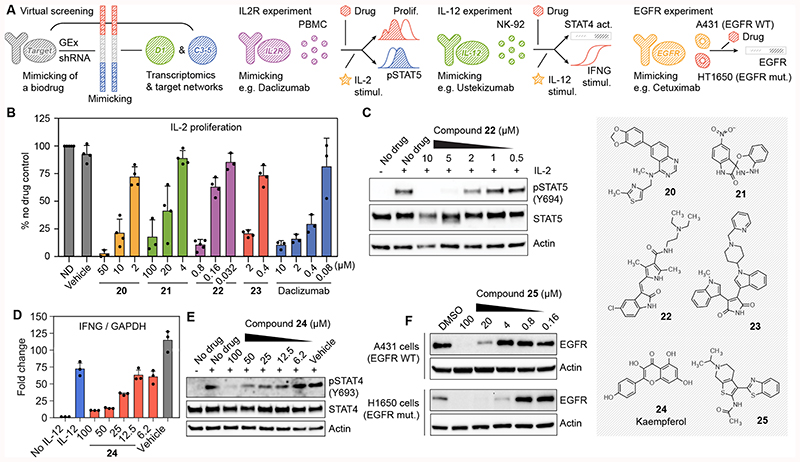
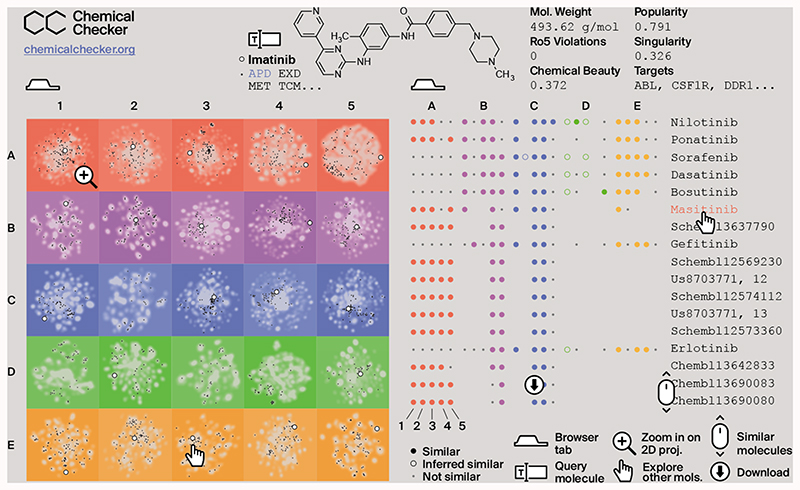
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
