

Interpretable multimodal deep learning for real-time pan-tissue pan-disease pathology search on social media
- PMID: 32467650
- PMCID: PMC7581495
- DOI: 10.1038/s41379-020-0540-1
Interpretable multimodal deep learning for real-time pan-tissue pan-disease pathology search on social media
Abstract
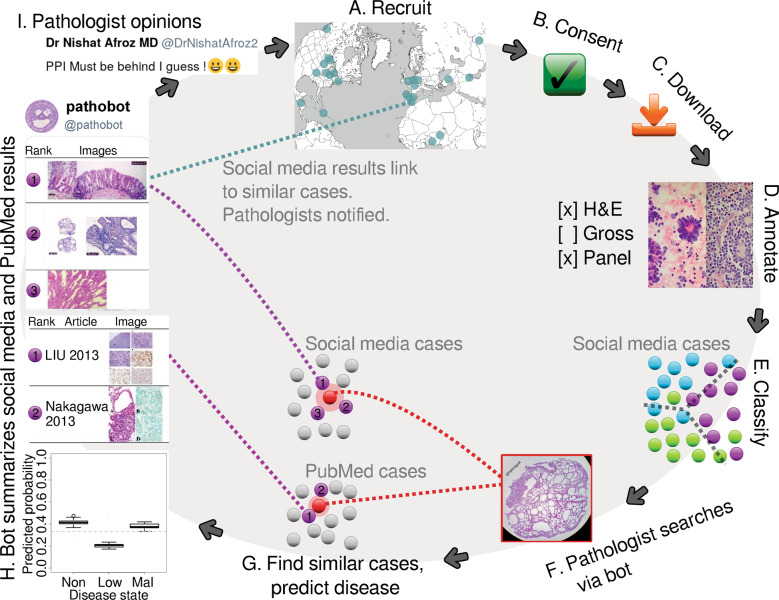
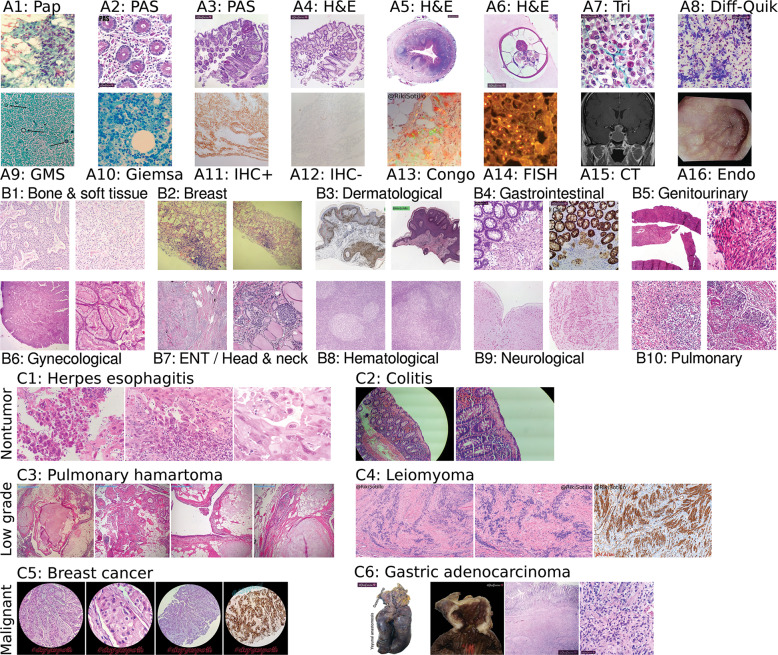
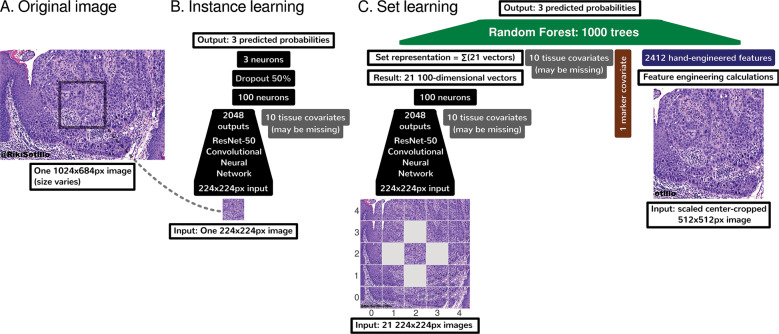
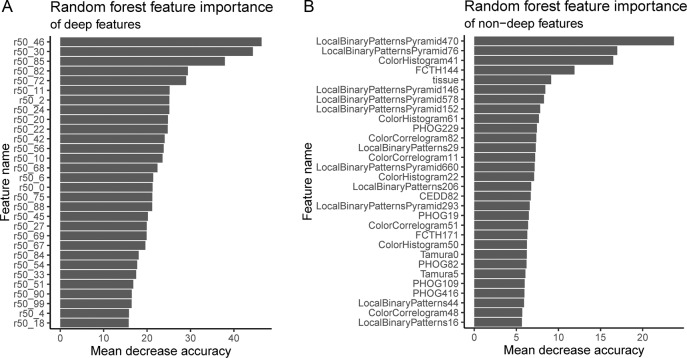
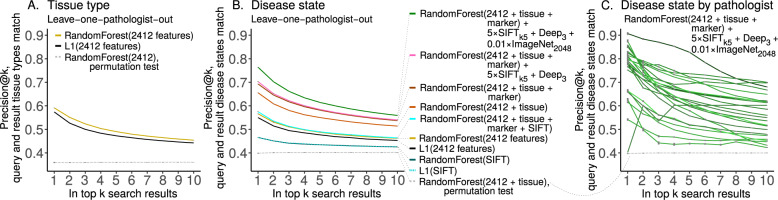
Pathologists are responsible for rapidly providing a diagnosis on critical health issues. Challenging cases benefit from additional opinions of pathologist colleagues. In addition to on-site colleagues, there is an active worldwide community of pathologists on social media for complementary opinions. Such access to pathologists worldwide has the capacity to improve diagnostic accuracy and generate broader consensus on next steps in patient care. From Twitter we curate 13,626 images from 6,351 tweets from 25 pathologists from 13 countries. We supplement the Twitter data with 113,161 images from 1,074,484 PubMed articles. We develop machine learning and deep learning models to (i) accurately identify histopathology stains, (ii) discriminate between tissues, and (iii) differentiate disease states. Area Under Receiver Operating Characteristic (AUROC) is 0.805-0.996 for these tasks. We repurpose the disease classifier to search for similar disease states given an image and clinical covariates. We report precision@k = 1 = 0.7618 ± 0.0018 (chance 0.397 ± 0.004, mean ±stdev ). The classifiers find that texture and tissue are important clinico-visual features of disease. Deep features trained only on natural images (e.g., cats and dogs) substantially improved search performance, while pathology-specific deep features and cell nuclei features further improved search to a lesser extent. We implement a social media bot (@pathobot on Twitter) to use the trained classifiers to aid pathologists in obtaining real-time feedback on challenging cases. If a social media post containing pathology text and images mentions the bot, the bot generates quantitative predictions of disease state (normal/artifact/infection/injury/nontumor, preneoplastic/benign/low-grade-malignant-potential, or malignant) and lists similar cases across social media and PubMed. Our project has become a globally distributed expert system that facilitates pathological diagnosis and brings expertise to underserved regions or hospitals with less expertise in a particular disease. This is the first pan-tissue pan-disease (i.e., from infection to malignancy) method for prediction and search on social media, and the first pathology study prospectively tested in public on social media. We will share data through http://pathobotology.org . We expect our project to cultivate a more connected world of physicians and improve patient care worldwide.
Conflict of interest statement
SY is a consultant and advisory board member for Roche, Bayer, Novartis, Pfizer, and Amgen—receiving an honorarium. TJF is a founder, equity owner, and Chief Scientific Officer of Paige.AI.
Figures

Similar articles
-
Automated processing of social media content for radiologists: applied deep learning to radiological content on twitter during COVID-19 pandemic.Emerg Radiol. 2021 Jun;28(3):477-483. doi: 10.1007/s10140-020-01885-z. Epub 2021 Jan 18. Emerg Radiol. 2021. PMID: 33459907 Free PMC article.
-
Extracting psychiatric stressors for suicide from social media using deep learning.BMC Med Inform Decis Mak. 2018 Jul 23;18(Suppl 2):43. doi: 10.1186/s12911-018-0632-8. BMC Med Inform Decis Mak. 2018. PMID: 30066665 Free PMC article.
-
An End-to-End Platform for Digital Pathology Using Hyperspectral Autofluorescence Microscopy and Deep Learning-Based Virtual Histology.Mod Pathol. 2024 Feb;37(2):100377. doi: 10.1016/j.modpat.2023.100377. Epub 2023 Nov 4. Mod Pathol. 2024. PMID: 37926422
-
#PathMastodon: An Up-In-Coming Platform for Pathology Education Among Pathologists, Trainees, and Medical Students.Adv Anat Pathol. 2024 Jan 1;31(1):52-57. doi: 10.1097/PAP.0000000000000405. Epub 2023 Jul 24. Adv Anat Pathol. 2024. PMID: 37488707 Review.
-
Built to Last? Reproducibility and Reusability of Deep Learning Algorithms in Computational Pathology.Mod Pathol. 2024 Jan;37(1):100350. doi: 10.1016/j.modpat.2023.100350. Epub 2023 Oct 10. Mod Pathol. 2024. PMID: 37827448 Review.
Cited by
-
Data-efficient and weakly supervised computational pathology on whole-slide images.Nat Biomed Eng. 2021 Jun;5(6):555-570. doi: 10.1038/s41551-020-00682-w. Epub 2021 Mar 1. Nat Biomed Eng. 2021. PMID: 33649564 Free PMC article.
-
Communicator-Driven Data Preprocessing Improves Deep Transfer Learning of Histopathological Prediction of Pancreatic Ductal Adenocarcinoma.Cancers (Basel). 2022 Apr 13;14(8):1964. doi: 10.3390/cancers14081964. Cancers (Basel). 2022. PMID: 35454869 Free PMC article.
-
Biased data, biased AI: deep networks predict the acquisition site of TCGA images.Diagn Pathol. 2023 May 17;18(1):67. doi: 10.1186/s13000-023-01355-3. Diagn Pathol. 2023. PMID: 37198691 Free PMC article.
-
A multimodal generative AI copilot for human pathology.Nature. 2024 Oct;634(8033):466-473. doi: 10.1038/s41586-024-07618-3. Epub 2024 Jun 12. Nature. 2024. PMID: 38866050 Free PMC article.
-
Breaking Barriers: AI's Influence on Pathology and Oncology in Resource-Scarce Medical Systems.Cancers (Basel). 2023 Dec 2;15(23):5692. doi: 10.3390/cancers15235692. Cancers (Basel). 2023. PMID: 38067395 Free PMC article. Review.
References
-
- Transforming Our World: The 2030 Agenda for Sustainable Development. In Rosa W, editor. A New Era in Global Health. Springer Publishing Company. ISBN 978-0-8261-9011-6 978-0-8261-9012-3. 2017:545-6.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
