

Detecting cardiac pathologies via machine learning on heart-rate variability time series and related markers
- PMID: 32483156
- PMCID: PMC7264331
- DOI: 10.1038/s41598-020-64083-4
Detecting cardiac pathologies via machine learning on heart-rate variability time series and related markers
Abstract
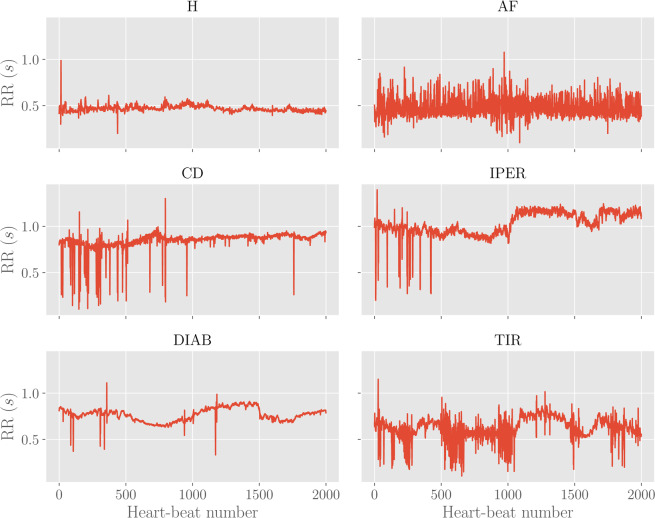
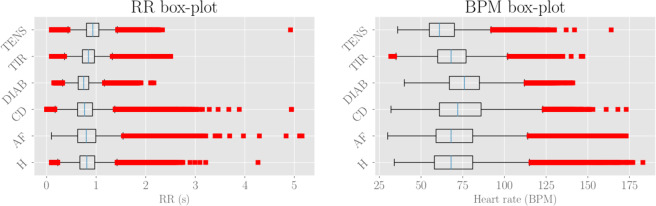
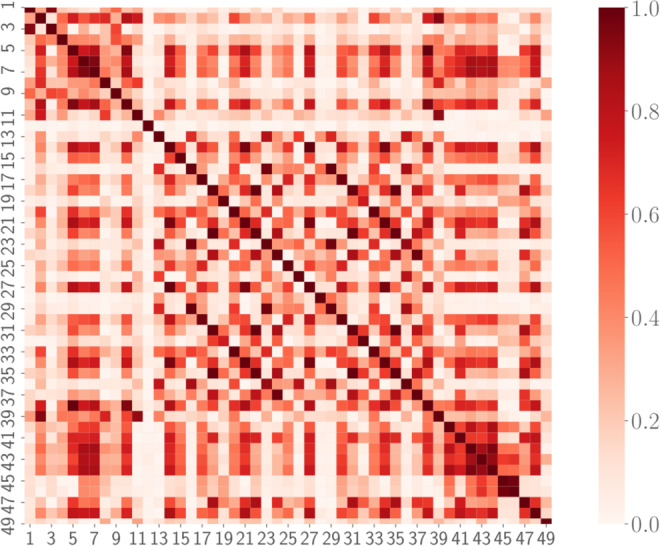
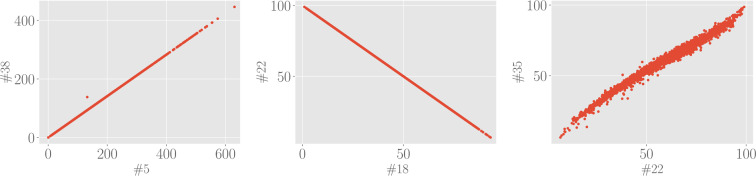
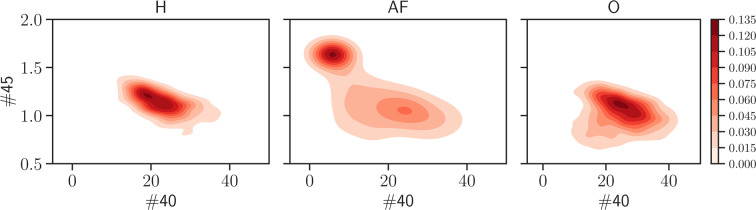
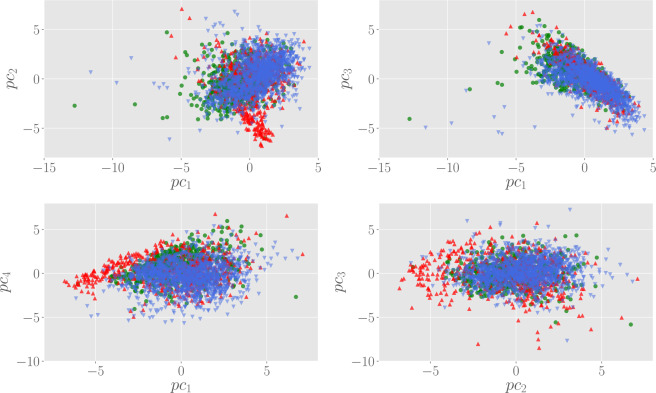
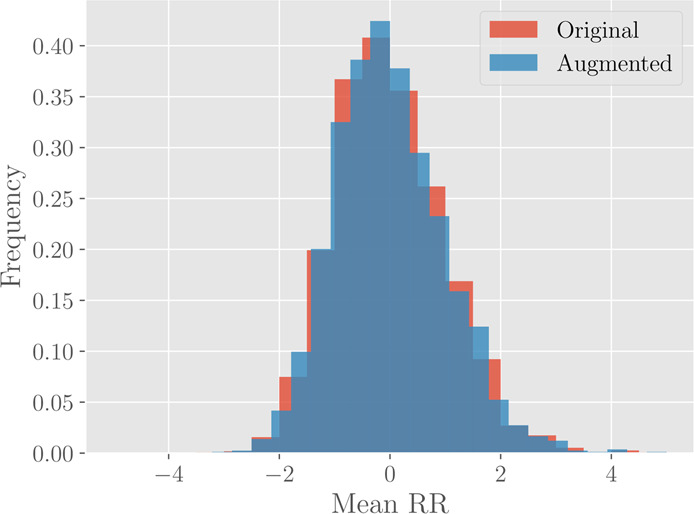
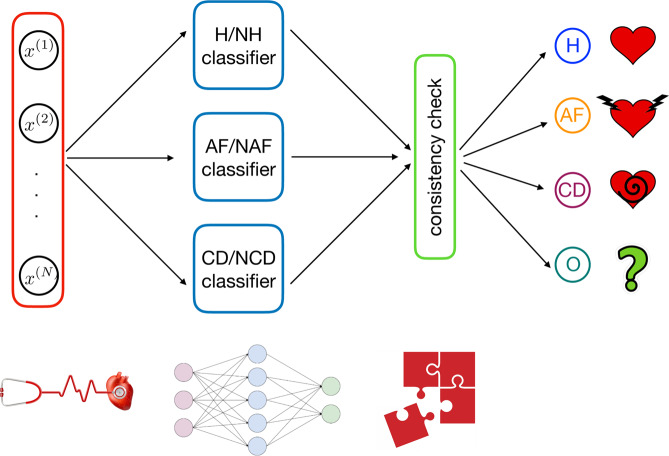
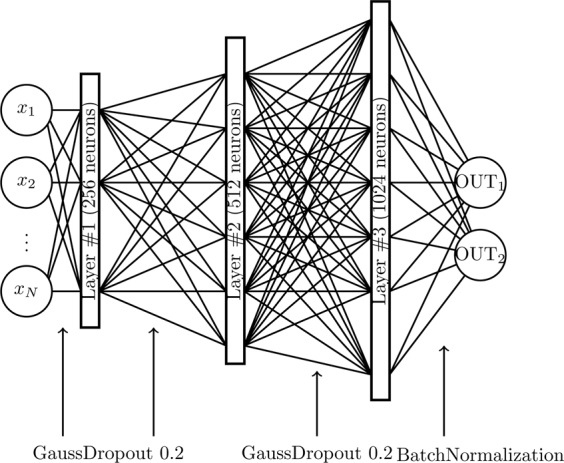
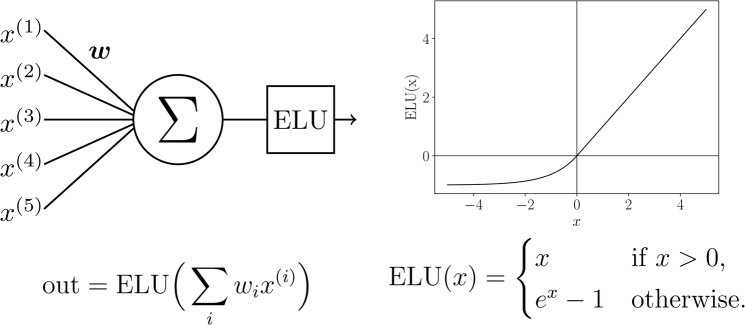
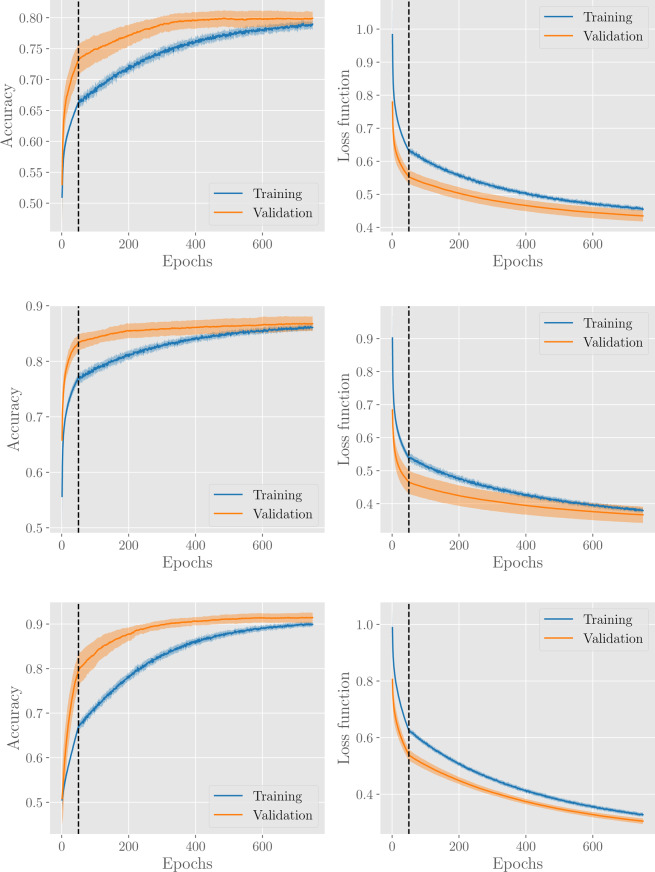
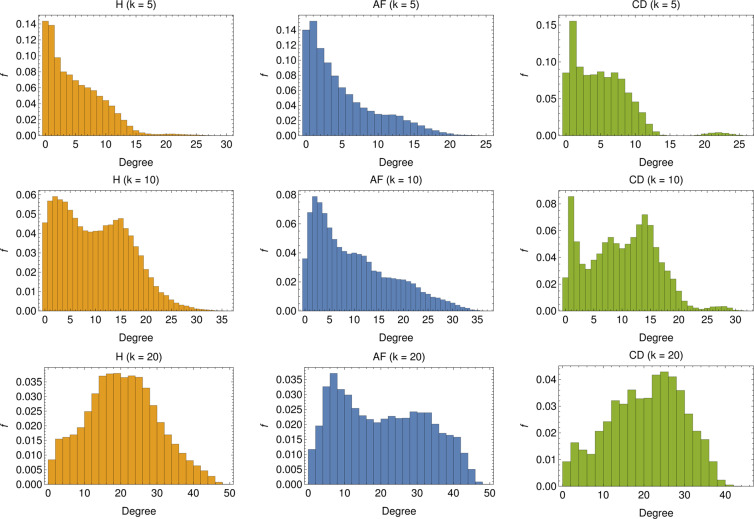
In this paper we develop statistical algorithms to infer possible cardiac pathologies, based on data collected from 24 h Holter recording over a sample of 2829 labelled patients; labels highlight whether a patient is suffering from cardiac pathologies. In the first part of the work we analyze statistically the heart-beat series associated to each patient and we work them out to get a coarse-grained description of heart variability in terms of 49 markers well established in the reference community. These markers are then used as inputs for a multi-layer feed-forward neural network that we train in order to make it able to classify patients. However, before training the network, preliminary operations are in order to check the effective number of markers (via principal component analysis) and to achieve data augmentation (because of the broadness of the input data). With such groundwork, we finally train the network and show that it can classify with high accuracy (at most ~85% successful identifications) patients that are healthy from those displaying atrial fibrillation or congestive heart failure. In the second part of the work, we still start from raw data and we get a classification of pathologies in terms of their related networks: patients are associated to nodes and links are drawn according to a similarity measure between the related heart-beat series. We study the emergent properties of these networks looking for features (e.g., degree, clustering, clique proliferation) able to robustly discriminate between networks built over healthy patients or over patients suffering from cardiac pathologies. We find overall very good agreement among the two paved routes.
Conflict of interest statement
The authors declare no competing interests.
Figures

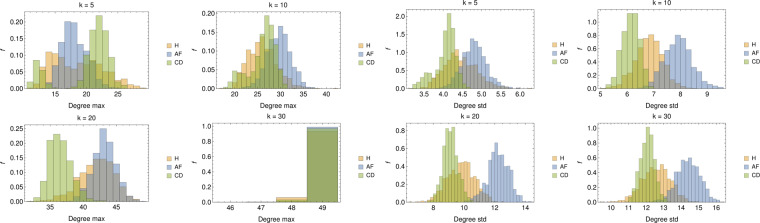
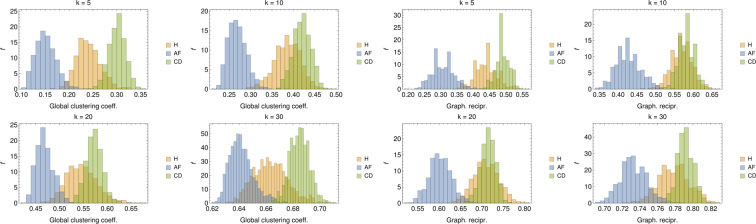
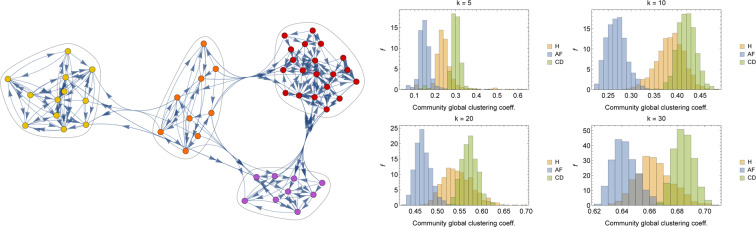
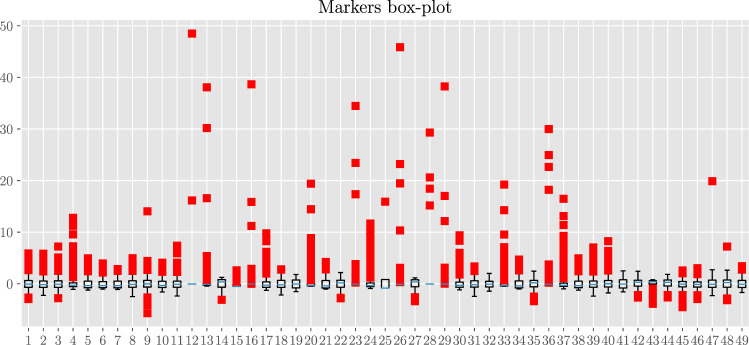
References
-
- Ascent of machine learning in medicine. Nature Materials18(5), 407–407 (2019). - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Medical
