

Dopaminergic modulation of the exploration/exploitation trade-off in human decision-making
- PMID: 32484779
- PMCID: PMC7266623
- DOI: 10.7554/eLife.51260
Dopaminergic modulation of the exploration/exploitation trade-off in human decision-making
Abstract
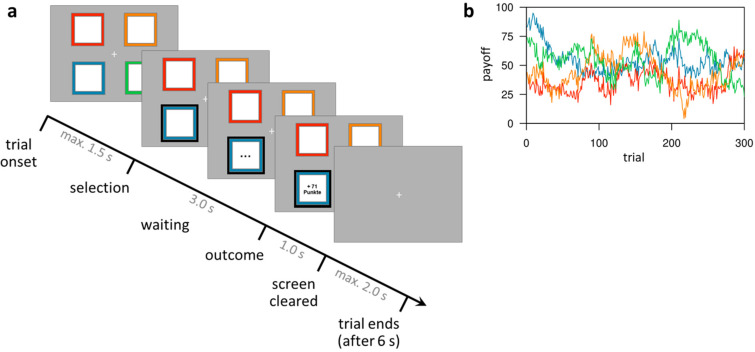
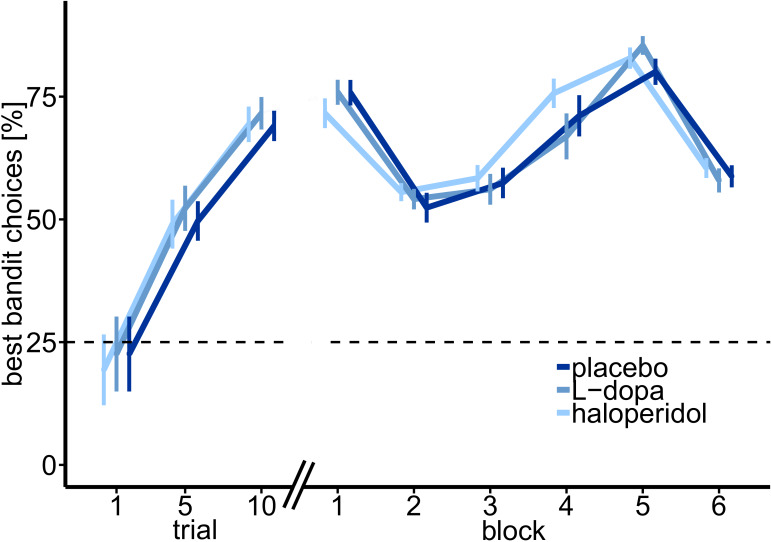
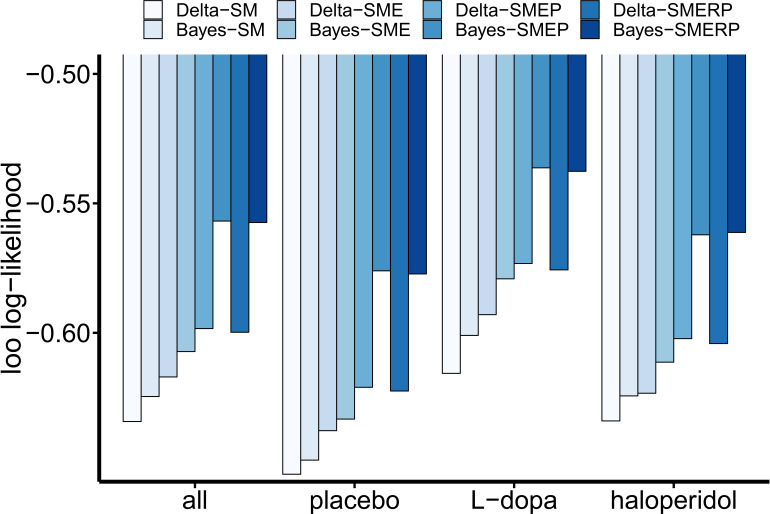
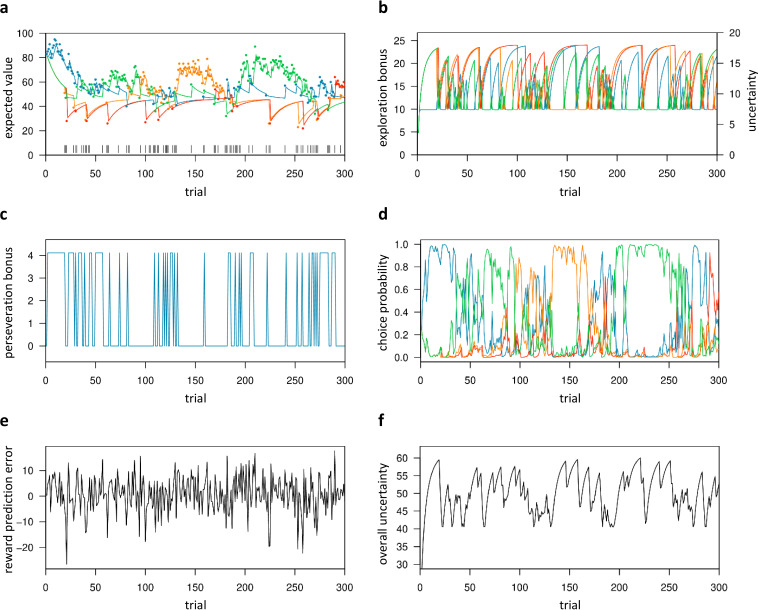
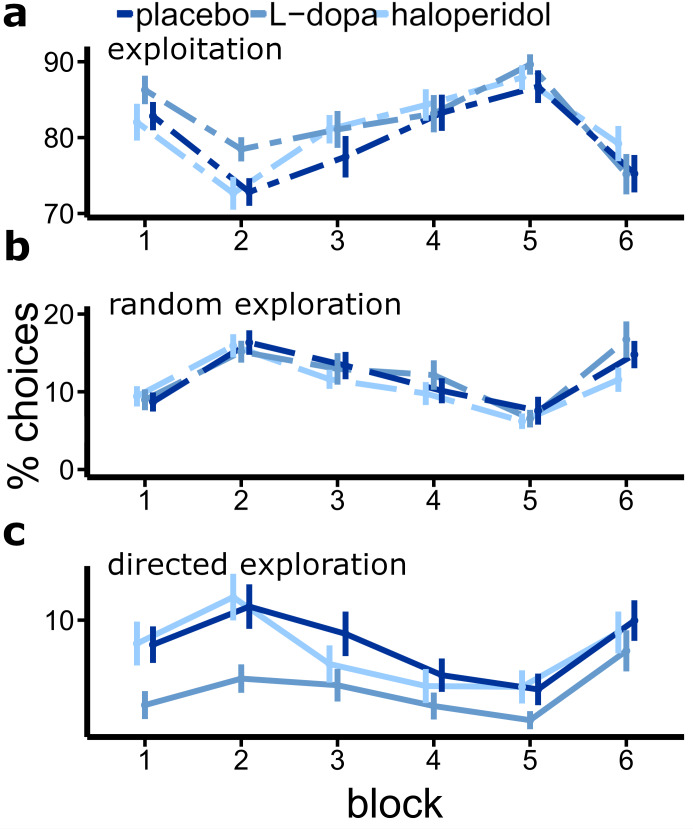
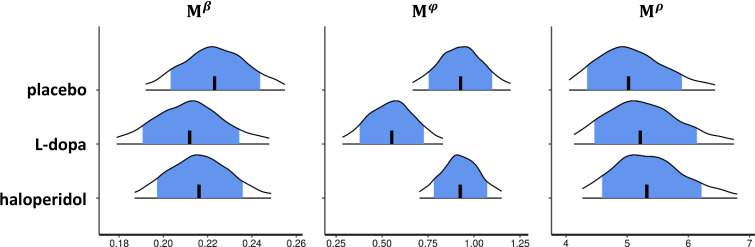
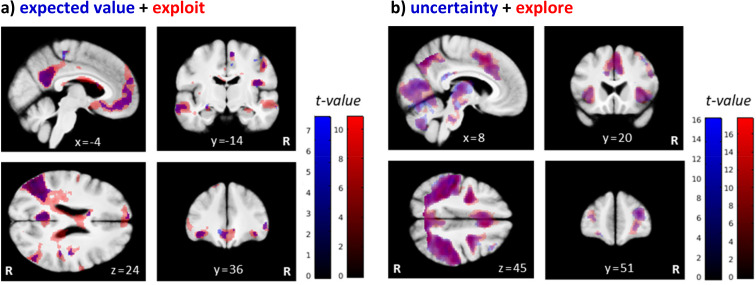
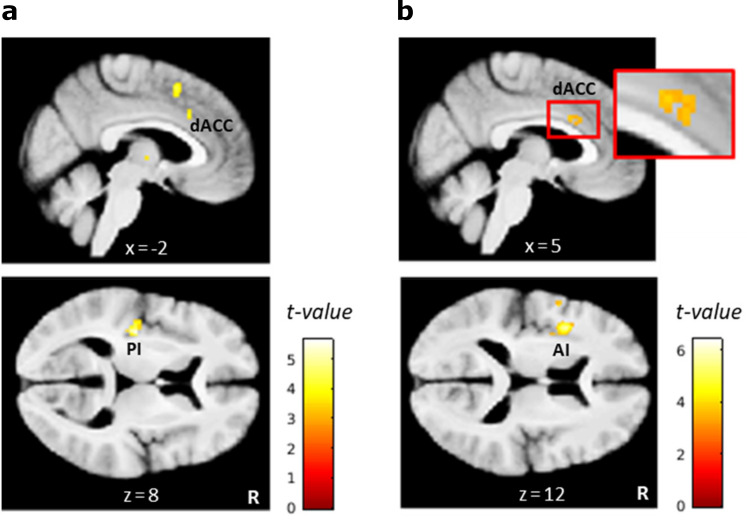
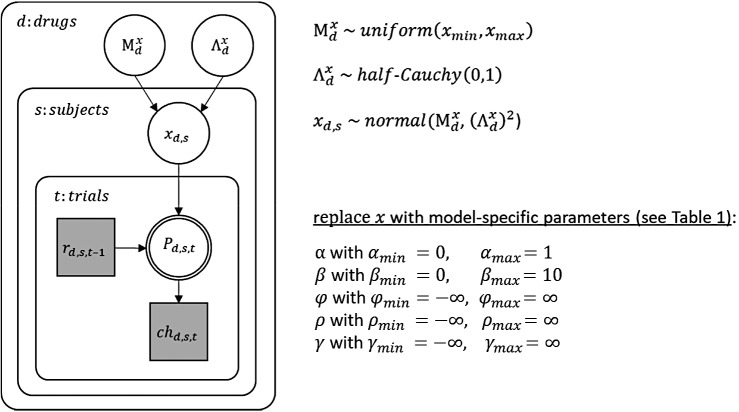
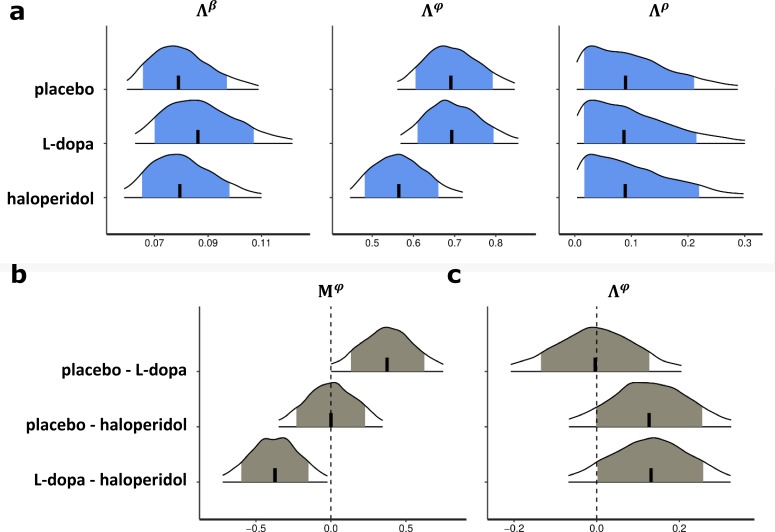
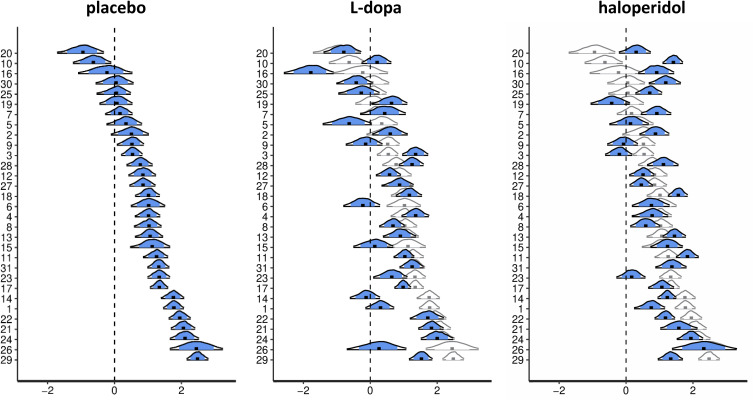
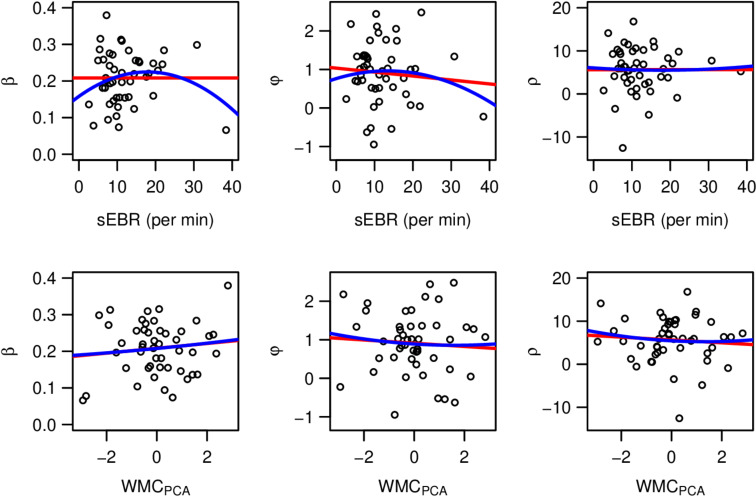
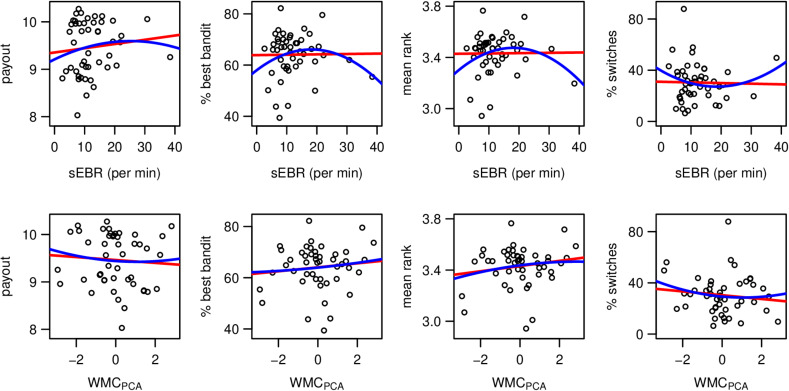
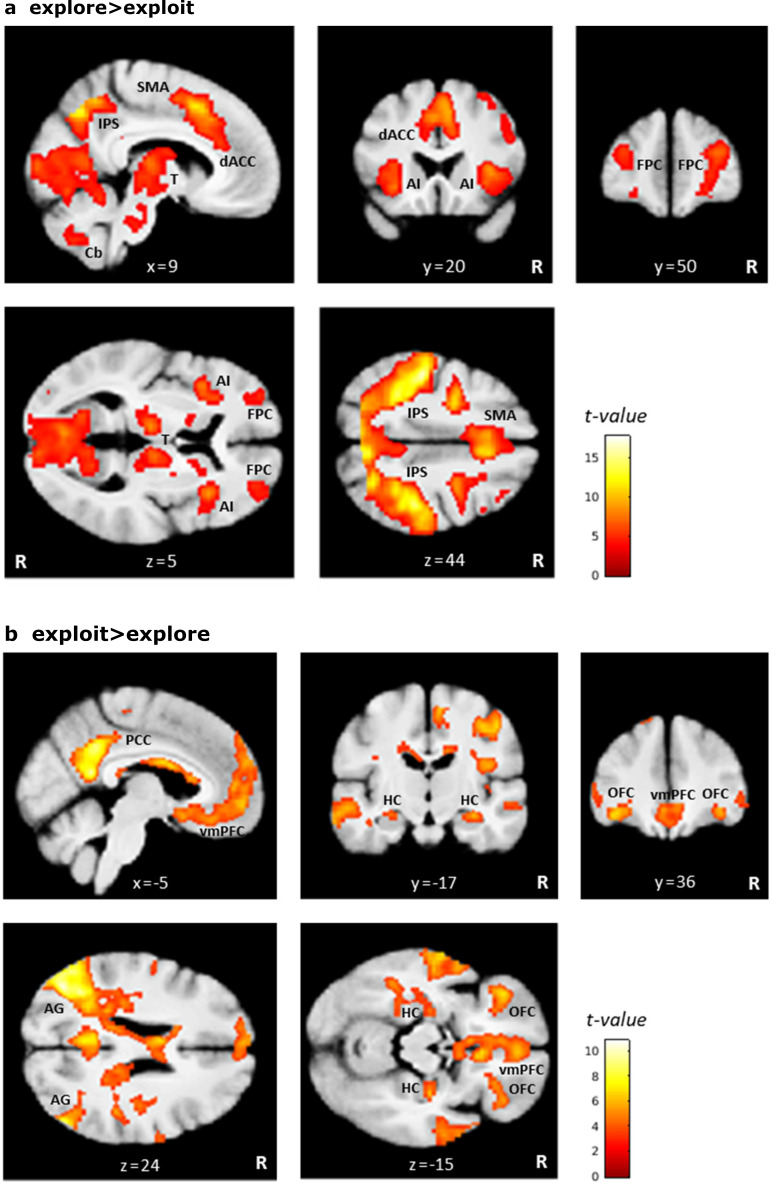
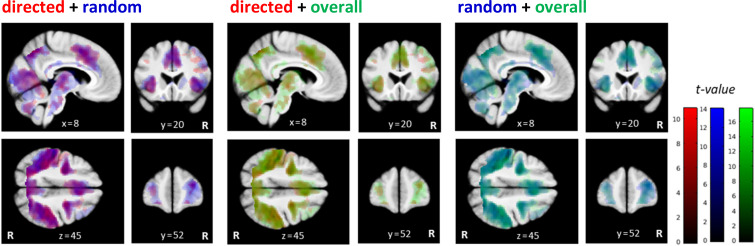
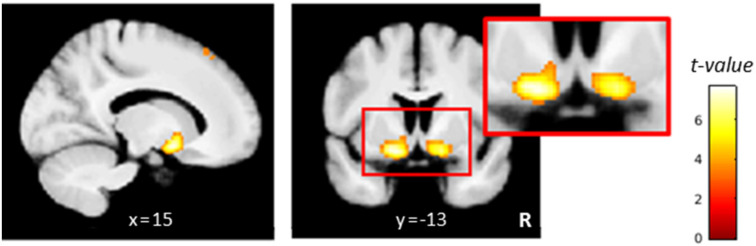
Involvement of dopamine in regulating exploration during decision-making has long been hypothesized, but direct causal evidence in humans is still lacking. Here, we use a combination of computational modeling, pharmacological intervention and functional magnetic resonance imaging to address this issue. Thirty-one healthy male participants performed a restless four-armed bandit task in a within-subjects design under three drug conditions: 150 mg of the dopamine precursor L-dopa, 2 mg of the D2 receptor antagonist haloperidol, and placebo. Choices were best explained by an extension of an established Bayesian learning model accounting for perseveration, directed exploration and random exploration. Modeling revealed attenuated directed exploration under L-dopa, while neural signatures of exploration, exploitation and prediction error were unaffected. Instead, L-dopa attenuated neural representations of overall uncertainty in insula and dorsal anterior cingulate cortex. Our results highlight the computational role of these regions in exploration and suggest that dopamine modulates how this circuit tracks accumulating uncertainty during decision-making.
Keywords: computational modeling; decision-making; dopamine; exploration; human; neuroscience; pharmacological fMRI.
© 2020, Chakroun et al.
Conflict of interest statement
KC, DM, AW, FG, JP No competing interests declared
Figures
References
-
- Anderson BDO, Moore JB. Optimal Filtering. Prentice Hall Information and System Sciences Series. Prentice-Hall; 1979.
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
