

A map of object space in primate inferotemporal cortex
- PMID: 32494012
- PMCID: PMC8088388
- DOI: 10.1038/s41586-020-2350-5
A map of object space in primate inferotemporal cortex
Abstract
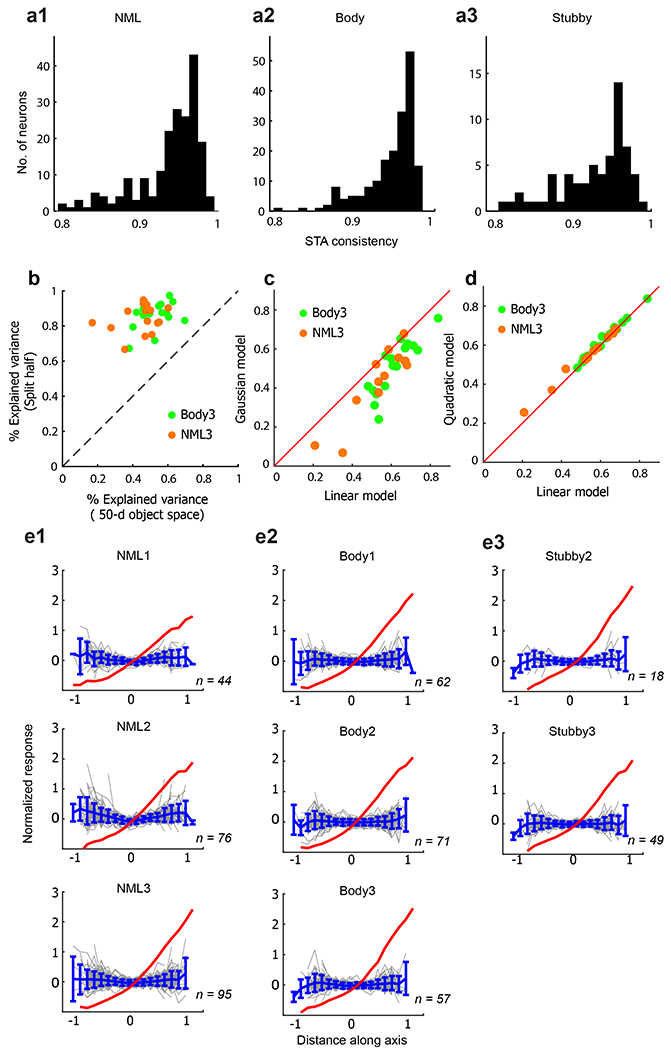
The inferotemporal (IT) cortex is responsible for object recognition, but it is unclear how the representation of visual objects is organized in this part of the brain. Areas that are selective for categories such as faces, bodies, and scenes have been found1-5, but large parts of IT cortex lack any known specialization, raising the question of what general principle governs IT organization. Here we used functional MRI, microstimulation, electrophysiology, and deep networks to investigate the organization of macaque IT cortex. We built a low-dimensional object space to describe general objects using a feedforward deep neural network trained on object classification6. Responses of IT cells to a large set of objects revealed that single IT cells project incoming objects onto specific axes of this space. Anatomically, cells were clustered into four networks according to the first two components of their preferred axes, forming a map of object space. This map was repeated across three hierarchical stages of increasing view invariance, and cells that comprised these maps collectively harboured sufficient coding capacity to approximately reconstruct objects. These results provide a unified picture of IT organization in which category-selective regions are part of a coarse map of object space whose dimensions can be extracted from a deep network.
Figures















References
-
- Downing PE, Jiang Y, Shuman M & Kanwisher N A cortical area selective for visual processing of the human body. Science 293, 2470–2473 (2001). - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
