

Theoretical issues in deep networks
- PMID: 32518109
- PMCID: PMC7720221
- DOI: 10.1073/pnas.1907369117
Theoretical issues in deep networks
Abstract
While deep learning is successful in a number of applications, it is not yet well understood theoretically. A theoretical characterization of deep learning should answer questions about their approximation power, the dynamics of optimization, and good out-of-sample performance, despite overparameterization and the absence of explicit regularization. We review our recent results toward this goal. In approximation theory both shallow and deep networks are known to approximate any continuous functions at an exponential cost. However, we proved that for certain types of compositional functions, deep networks of the convolutional type (even without weight sharing) can avoid the curse of dimensionality. In characterizing minimization of the empirical exponential loss we consider the gradient flow of the weight directions rather than the weights themselves, since the relevant function underlying classification corresponds to normalized networks. The dynamics of normalized weights turn out to be equivalent to those of the constrained problem of minimizing the loss subject to a unit norm constraint. In particular, the dynamics of typical gradient descent have the same critical points as the constrained problem. Thus there is implicit regularization in training deep networks under exponential-type loss functions during gradient flow. As a consequence, the critical points correspond to minimum norm infima of the loss. This result is especially relevant because it has been recently shown that, for overparameterized models, selection of a minimum norm solution optimizes cross-validation leave-one-out stability and thereby the expected error. Thus our results imply that gradient descent in deep networks minimize the expected error.
Keywords: approximation; deep learning; generalization; machine learning; optimization.
Conflict of interest statement
The authors declare no competing interest.
Figures
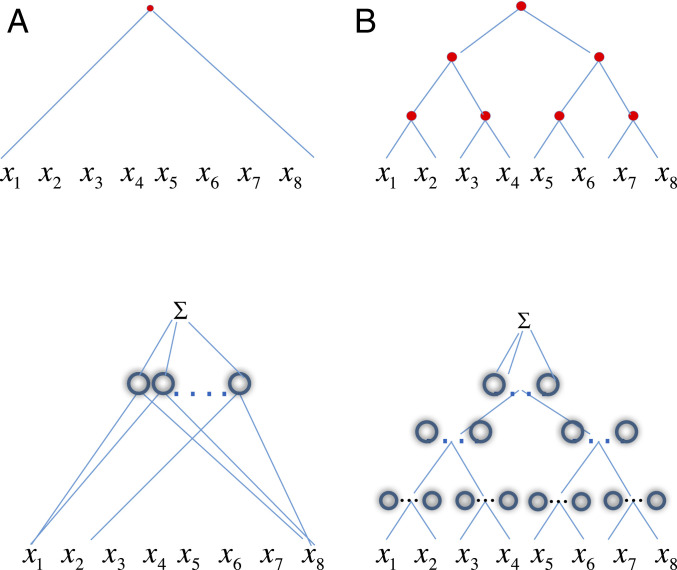
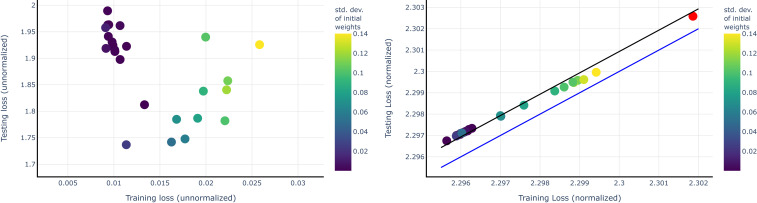
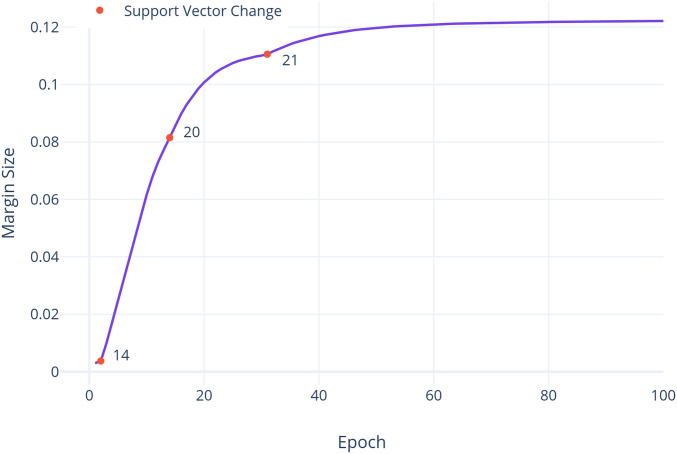
References
-
- Niyogi P., Girosi F., On the relationship between generalization error, hypothesis complexity, and sample complexity for radial basis functions. Neural Comput. 8, 819–842 (1996).
-
- Poggio T., Smale S., The mathematics of learning: Dealing with data. Not. Am. Math. Soc. 50, 537–544 (2003).
-
- Poggio T., Mhaskar H., Rosasco L., Miranda B., Liao Q., Why and when can deep-but not shallow-networks avoid the curse of dimensionality: A review. Int. J. Autom. Comput. 14, 503–519 (2017).
-
- Banburski A., et al. , Theory of Deep Learning III: Dynamics and Generalization in Deep Networks (Center for Brains, Minds and Machines [CBMM], Cambridge, MA, 2019).
Publication types
LinkOut - more resources
Full Text Sources
Research Materials
