

Machine learning and natural language processing methods to identify ischemic stroke, acuity and location from radiology reports
- PMID: 32559211
- PMCID: PMC7304623
- DOI: 10.1371/journal.pone.0234908
Machine learning and natural language processing methods to identify ischemic stroke, acuity and location from radiology reports
Abstract
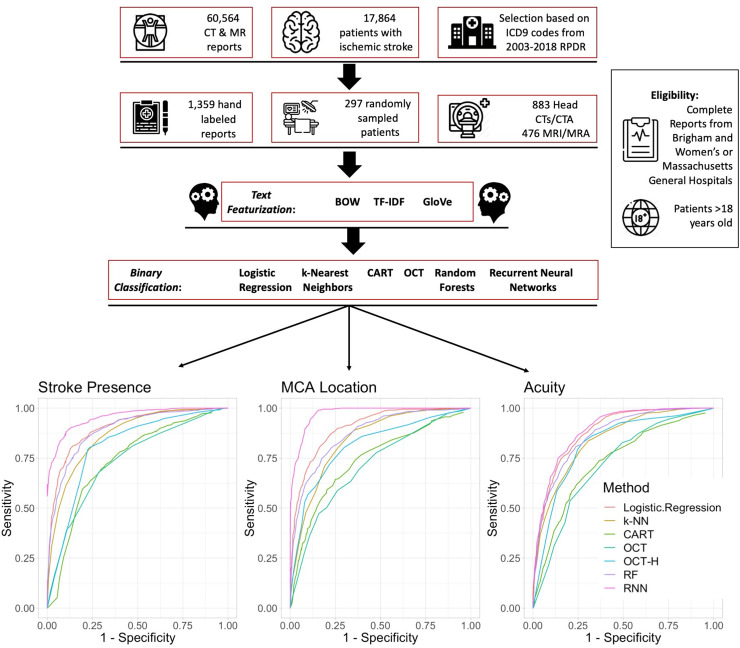
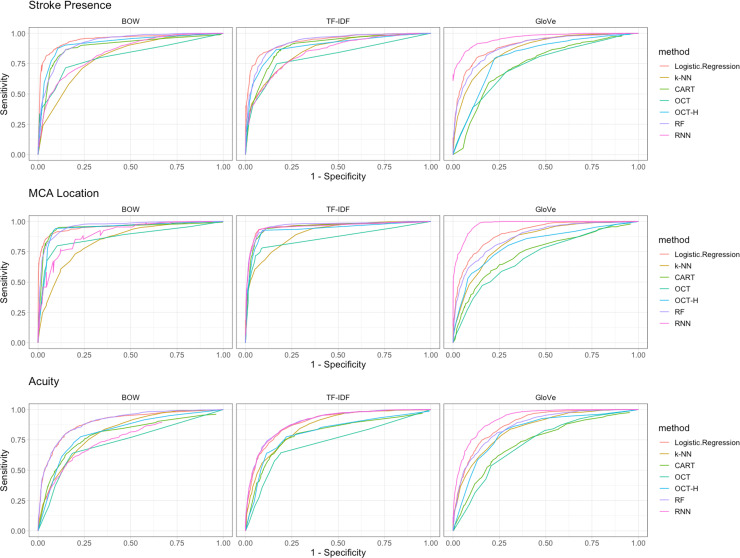
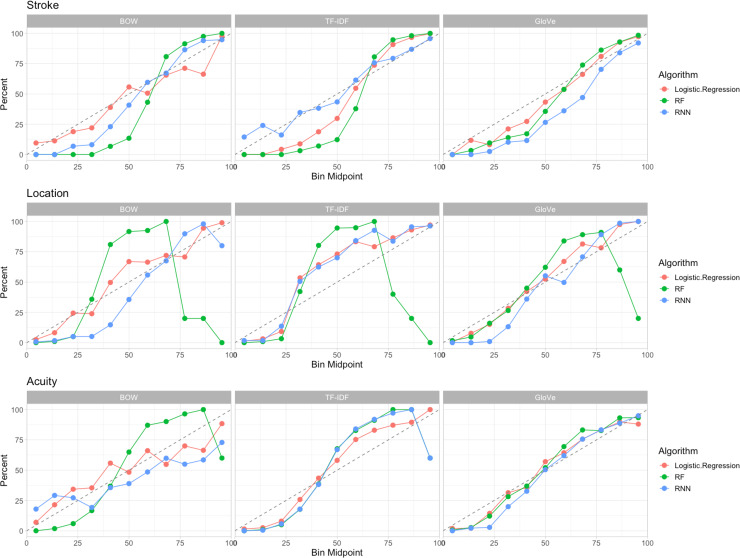
Accurate, automated extraction of clinical stroke information from unstructured text has several important applications. ICD-9/10 codes can misclassify ischemic stroke events and do not distinguish acuity or location. Expeditious, accurate data extraction could provide considerable improvement in identifying stroke in large datasets, triaging critical clinical reports, and quality improvement efforts. In this study, we developed and report a comprehensive framework studying the performance of simple and complex stroke-specific Natural Language Processing (NLP) and Machine Learning (ML) methods to determine presence, location, and acuity of ischemic stroke from radiographic text. We collected 60,564 Computed Tomography and Magnetic Resonance Imaging Radiology reports from 17,864 patients from two large academic medical centers. We used standard techniques to featurize unstructured text and developed neurovascular specific word GloVe embeddings. We trained various binary classification algorithms to identify stroke presence, location, and acuity using 75% of 1,359 expert-labeled reports. We validated our methods internally on the remaining 25% of reports and externally on 500 radiology reports from an entirely separate academic institution. In our internal population, GloVe word embeddings paired with deep learning (Recurrent Neural Networks) had the best discrimination of all methods for our three tasks (AUCs of 0.96, 0.98, 0.93 respectively). Simpler NLP approaches (Bag of Words) performed best with interpretable algorithms (Logistic Regression) for identifying ischemic stroke (AUC of 0.95), MCA location (AUC 0.96), and acuity (AUC of 0.90). Similarly, GloVe and Recurrent Neural Networks (AUC 0.92, 0.89, 0.93) generalized better in our external test set than BOW and Logistic Regression for stroke presence, location and acuity, respectively (AUC 0.89, 0.86, 0.80). Our study demonstrates a comprehensive assessment of NLP techniques for unstructured radiographic text. Our findings are suggestive that NLP/ML methods can be used to discriminate stroke features from large data cohorts for both clinical and research-related investigations.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
-
- Manning CD, Manning CD, Schütze H. Foundations of statistical natural language processing: MIT press; 1999.
-
- Pennington J, Socher R, Manning C, editors. Glove: Global vectors for word representation. Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP); 2014.
-
- Mikolov T, Chen K, Corrado G, Dean J. Efficient estimation of word representations in vector space. arXiv preprint arXiv:13013781. 2013.
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
