

Development and Validation of Forecasting Next Reported Seizure Using e-Diaries
- PMID: 32567720
- PMCID: PMC7720795
- DOI: 10.1002/ana.25812
Development and Validation of Forecasting Next Reported Seizure Using e-Diaries
Abstract
Objective: There are no validated methods for predicting the timing of seizures. Using machine learning, we sought to forecast 24-hour risk of self-reported seizure from e-diaries.
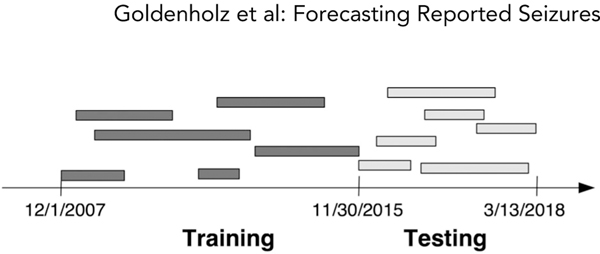
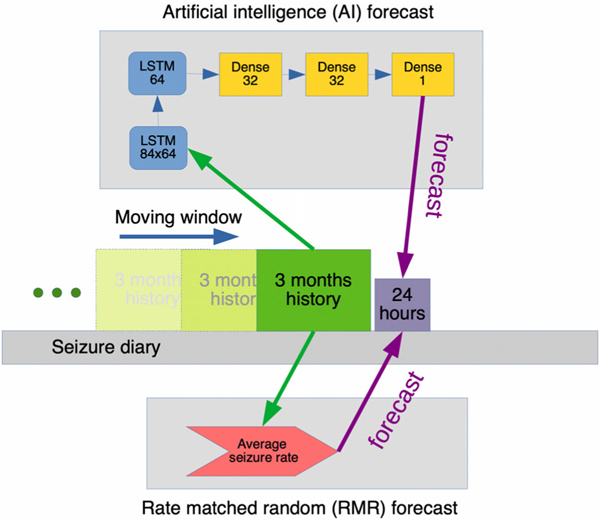
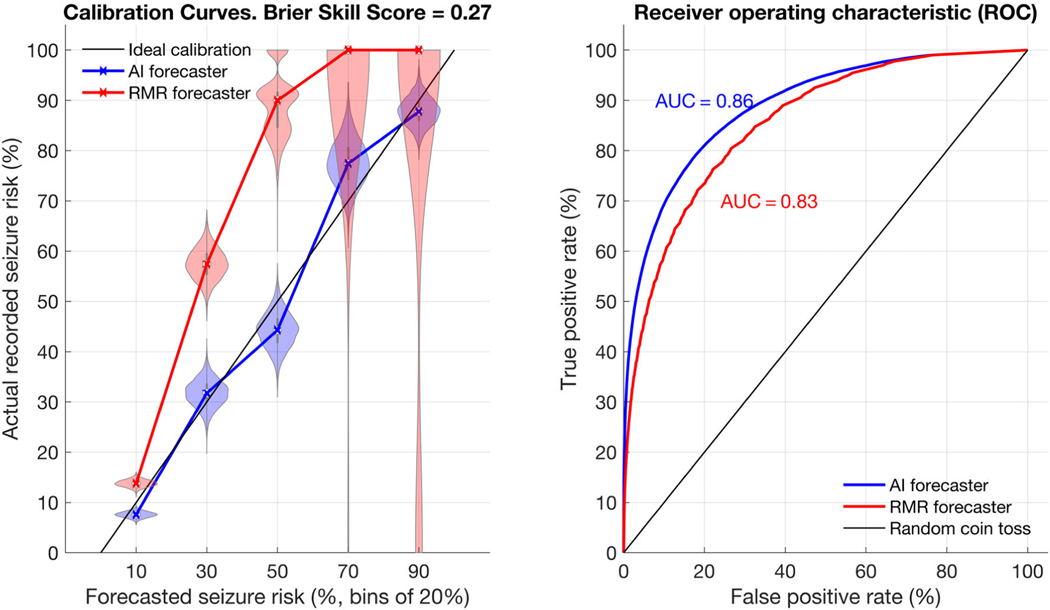
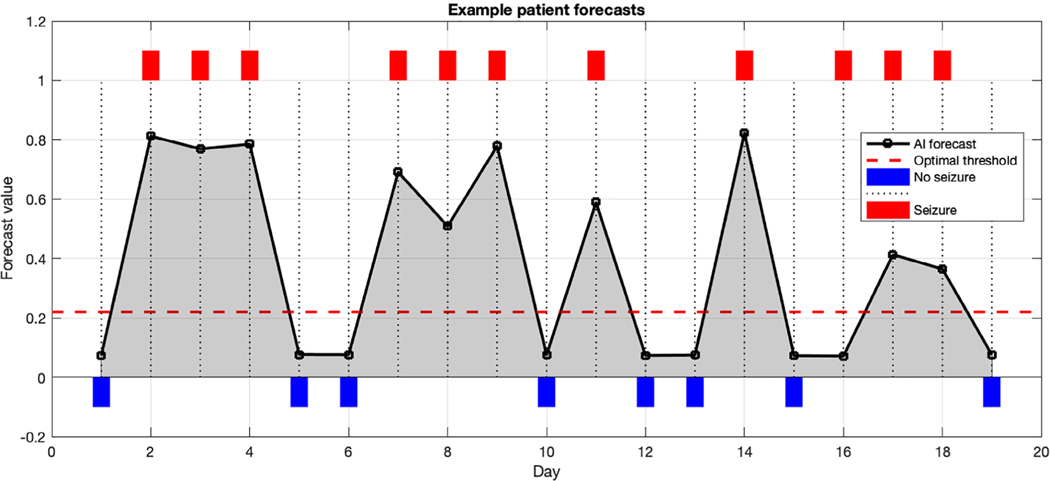
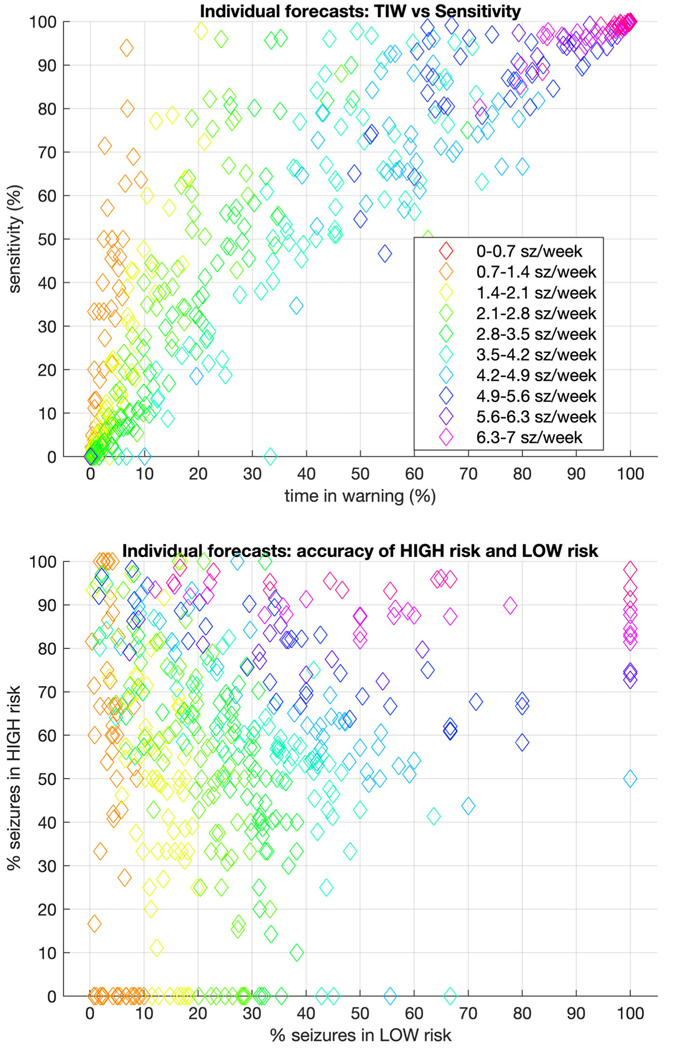
Methods: Data from 5,419 patients on SeizureTracker.com (including seizure count, type, and duration) were split into training (3,806 patients/1,665,215 patient-days) and testing (1,613 patients/549,588 patient-days) sets with no overlapping patients. An artificial intelligence (AI) program, consisting of recurrent networks followed by a multilayer perceptron ("deep learning" model), was trained to produce risk forecasts. Forecasts were made from a sliding window of 3-month diary history for each day of each patient's diary. After training, the model parameters were held constant and the testing set was scored. A rate-matched random (RMR) forecast was compared to the AI. Comparisons were made using the area under the receiver operating characteristic curve (AUC), a measure of binary discrimination performance, and the Brier score, a measure of forecast calibration. The Brier skill score (BSS) measured the improvement of the AI Brier score compared to the benchmark RMR Brier score. Confidence intervals (CIs) on performance statistics were obtained via bootstrapping.
Results: The AUC was 0.86 (95% CI = 0.85-0.88) for AI and 0.83 (95% CI = 0.81-0.85) for RMR, favoring AI (p < 0.001). Overall (all patients combined), BSS was 0.27 (95% CI = 0.23-0.31), also favoring AI (p < 0.001).
Interpretation: The AI produced a valid forecast superior to a chance forecaster, and provided meaningful forecasts in the majority of patients. Future studies will be needed to quantify the clinical value of these forecasts for patients. ANN NEUROL 2020;88:588-595.
© 2020 American Neurological Association.
Conflict of interest statement
Potential Conflicts of Interest
Nothing to report.
Figures
References
-
- Institute of Medicine (US) Committee on the Public Health Dimensions of the Epilepsies In: England MJ, Liverman CT, Schultz AM, Strawbridge LM, eds. Epilepsy across the spectrum: promoting health and understanding. Washington, DC: National Academies Press, 2012. - PubMed
-
- Janse SA, Dumanis SB, Huwig T, et al. Patient and caregiver preferences for the potential benefits and risks of a seizure forecasting device: a best-worst scaling. Epilepsy Behav 2019;96:183–191. - PubMed
-
- Herzog AG, Fowler KM, Sperling MR, Massaro JM. Distribution of seizures across the menstrual cycle in women with epilepsy. Epilepsia 2015;56:e58–e62. - PubMed
-
- Karoly PJ, Goldenholz DM, Freestone DR, et al. Circadian and circaseptan rhythms in human epilepsy: a retrospective cohort study. Lancet Neurol 2018;17:977–985. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
