

Phasic dopamine reinforces distinct striatal stimulus encoding in the olfactory tubercle driving dopaminergic reward prediction
- PMID: 32651365
- PMCID: PMC7351739
- DOI: 10.1038/s41467-020-17257-7
Phasic dopamine reinforces distinct striatal stimulus encoding in the olfactory tubercle driving dopaminergic reward prediction
Abstract
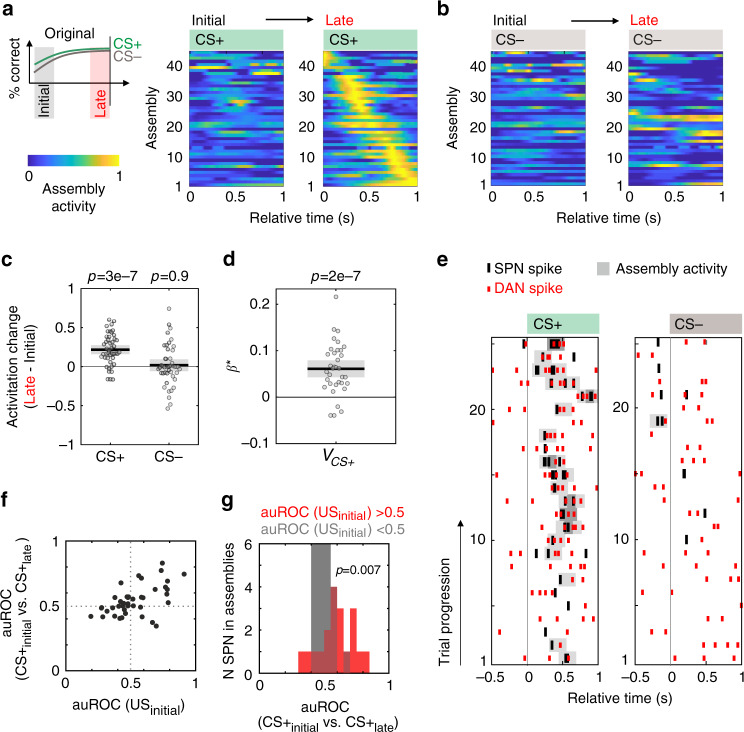
The learning of stimulus-outcome associations allows for predictions about the environment. Ventral striatum and dopaminergic midbrain neurons form a larger network for generating reward prediction signals from sensory cues. Yet, the network plasticity mechanisms to generate predictive signals in these distributed circuits have not been entirely clarified. Also, direct evidence of the underlying interregional assembly formation and information transfer is still missing. Here we show that phasic dopamine is sufficient to reinforce the distinctness of stimulus representations in the ventral striatum even in the absence of reward. Upon such reinforcement, striatal stimulus encoding gives rise to interregional assemblies that drive dopaminergic neurons during stimulus-outcome learning. These assemblies dynamically encode the predicted reward value of conditioned stimuli. Together, our data reveal that ventral striatal and midbrain reward networks form a reinforcing loop to generate reward prediction coding.
Conflict of interest statement
The authors declare no competing interests.
Figures
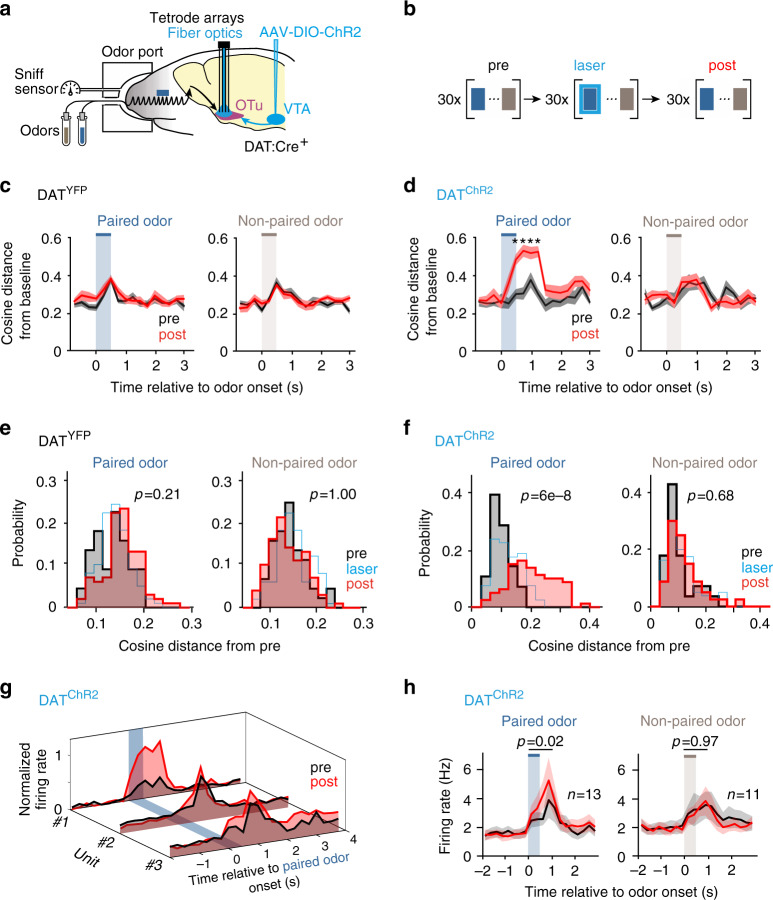
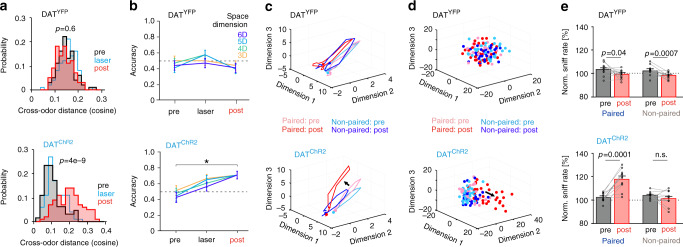
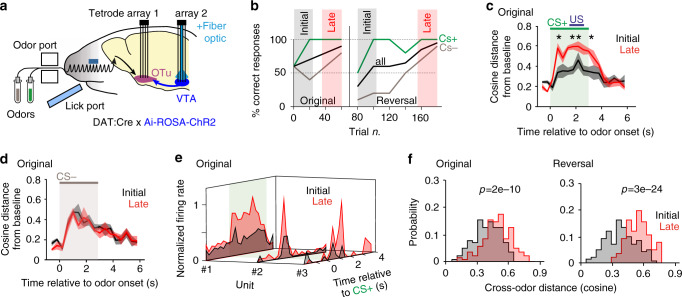
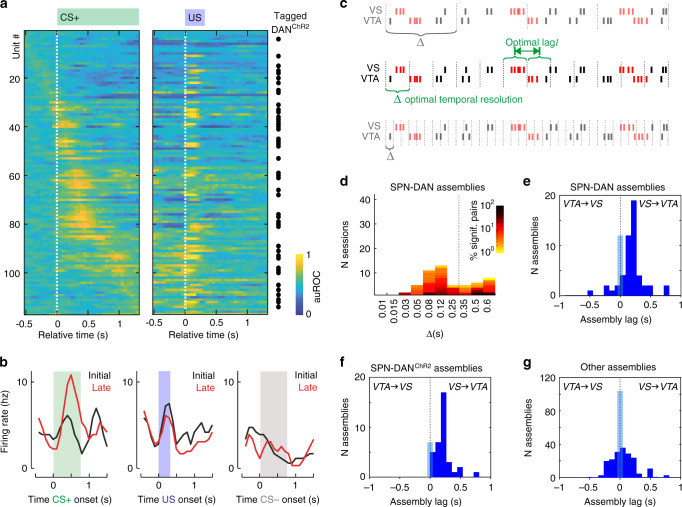
References
-
- Schultz W. Multiple reward signals in the brain. Nat. Rev. Neurosci. 2000;1:199. - PubMed
-
- Fiorillo CD, Tobler PN, Schultz W. Discrete coding of reward probability and uncertainty by dopamine neurons. Science. 2003;299:1898–1902. - PubMed
-
- Seymour B, et al. Temporal difference models describe higher-order learning in humans. Nature. 2004;429:664–667. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
