

Conditional permutation importance revisited
- PMID: 32664864
- PMCID: PMC7362659
- DOI: 10.1186/s12859-020-03622-2
Conditional permutation importance revisited
Abstract
Background: Random forest based variable importance measures have become popular tools for assessing the contributions of the predictor variables in a fitted random forest. In this article we reconsider a frequently used variable importance measure, the Conditional Permutation Importance (CPI). We argue and illustrate that the CPI corresponds to a more partial quantification of variable importance and suggest several improvements in its methodology and implementation that enhance its practical value. In addition, we introduce the threshold value in the CPI algorithm as a parameter that can make the CPI more partial or more marginal.
Results: By means of extensive simulations, where the original version of the CPI is used as the reference, we examine the impact of the proposed methodological improvements. The simulation results show how the improved CPI methodology increases the interpretability and stability of the computations. In addition, the newly proposed implementation decreases the computation times drastically and is more widely applicable. The improved CPI algorithm is made freely available as an add-on package to the open-source software R.
Conclusion: The proposed methodology and implementation of the CPI is computationally faster and leads to more stable results. It has a beneficial impact on practical research by making random forest analyses more interpretable.
Keywords: Conditional permutation importance; R; Random forest.
Conflict of interest statement
The authors declare that they have no competing interests.
Figures

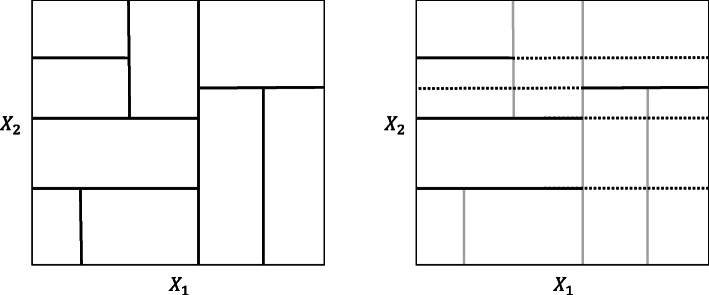
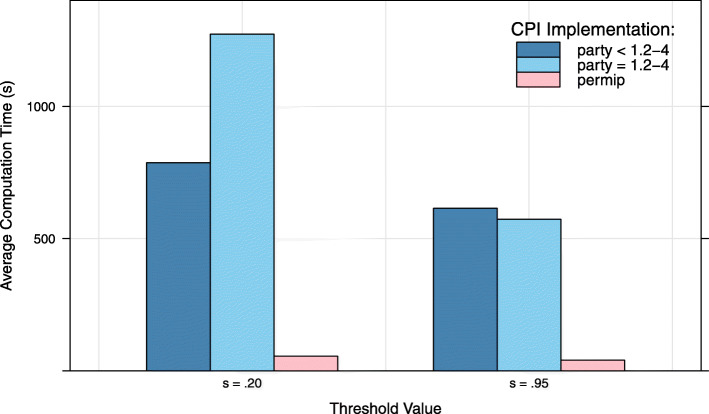

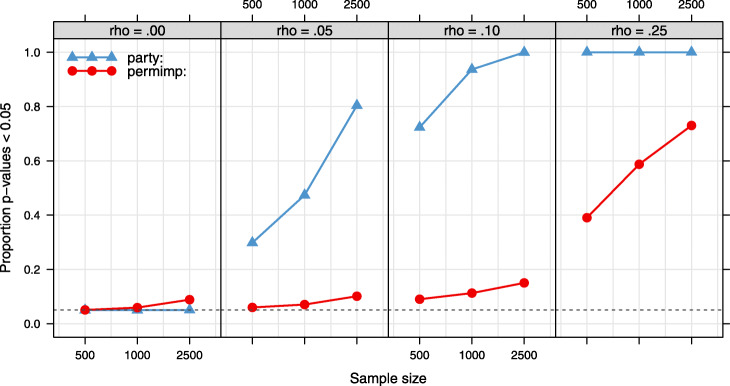
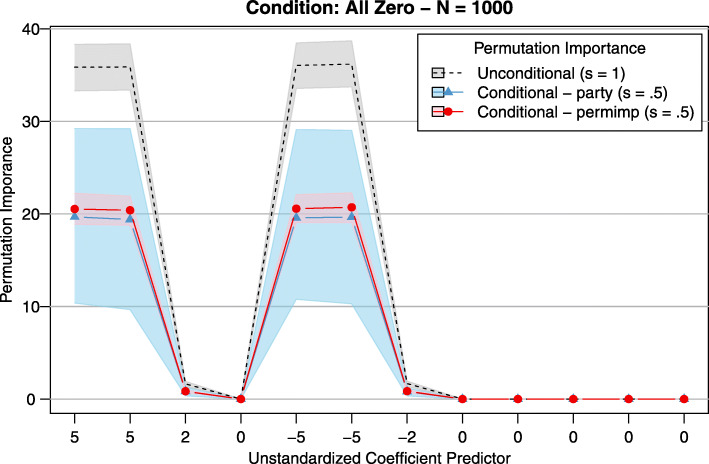
References
-
- Breiman L. Random forests. Mach Learn. 2001;45(1):5–32.
-
- Breiman L, Cutler A. Technical report: Random forests manual v4: UC Berkeley; 2003. https://www.stat.berkeley.edu/~breiman/Using_random_forests_v4.0.pdf.
-
- Ishwaran H, et al. Variable importance in binary regression trees and forests. Electron J Stat. 2007;1:519–37.
-
- Ishwaran H, Kogalur UB, Gorodeski EZ, Minn AJ, Lauer MS. High-dimensional variable selection for survival data. J Am Stat Assoc. 2010;105(489):205–17.
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
