

Rapid detection of microbiota cell type diversity using machine-learned classification of flow cytometry data
- PMID: 32669688
- PMCID: PMC7363847
- DOI: 10.1038/s42003-020-1106-y
Rapid detection of microbiota cell type diversity using machine-learned classification of flow cytometry data
Abstract
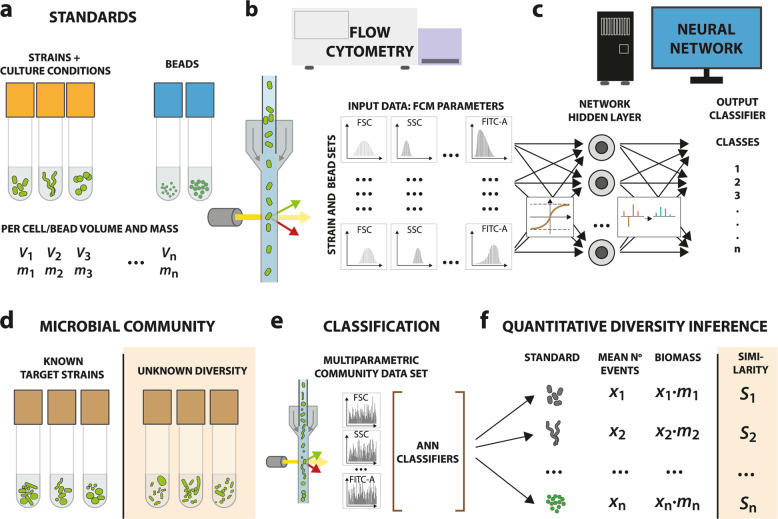
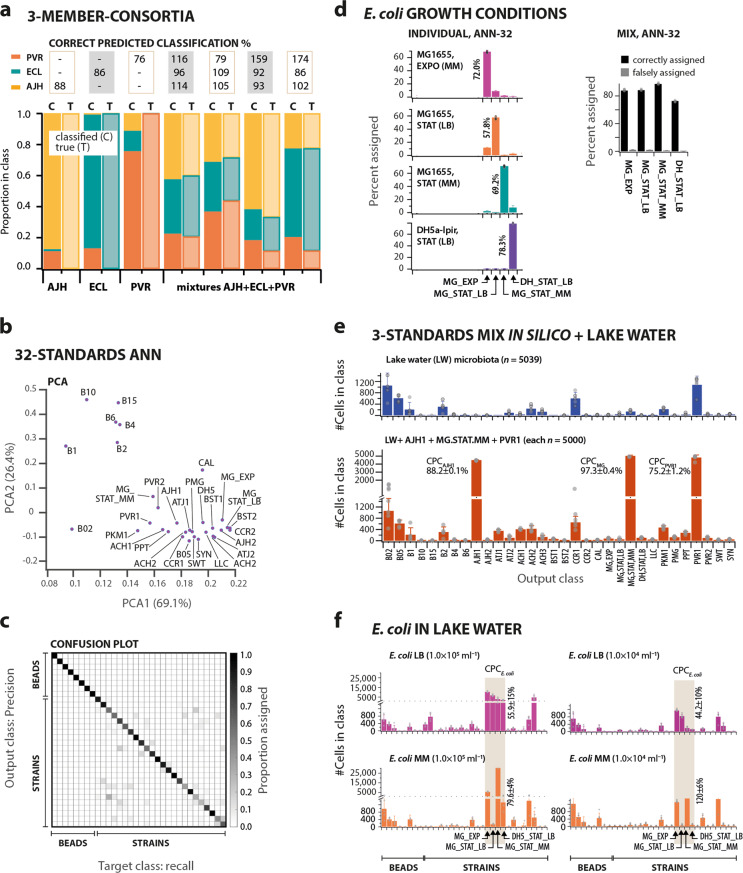
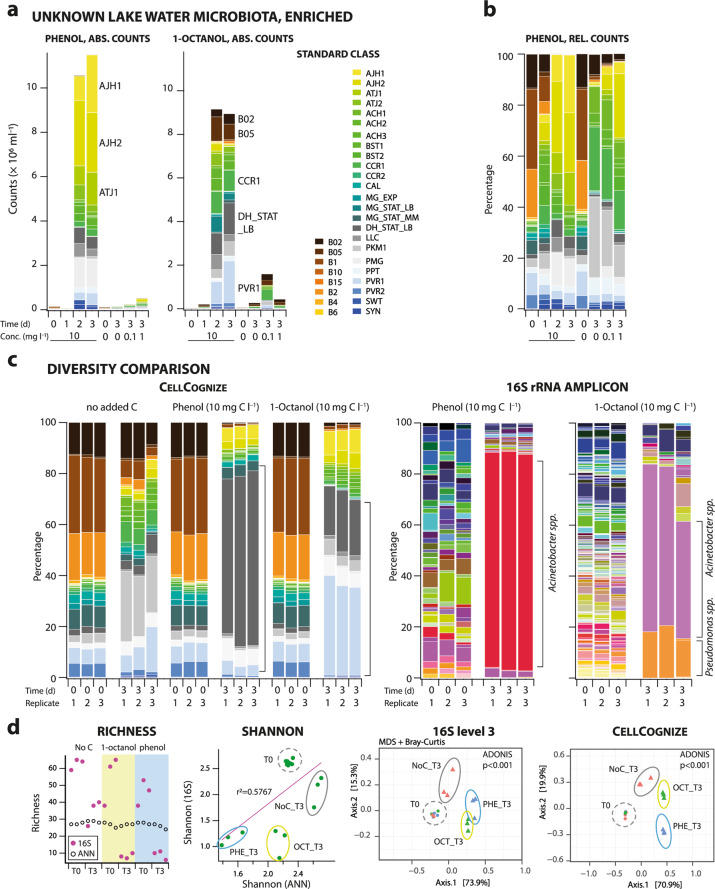
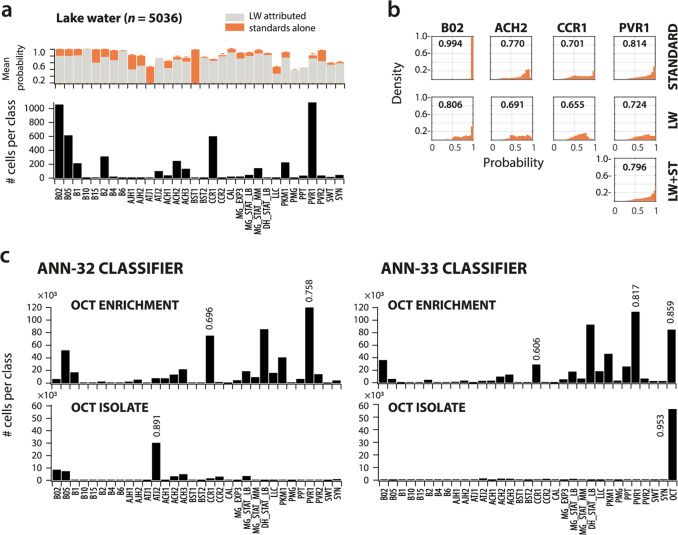
The study of complex microbial communities typically entails high-throughput sequencing and downstream bioinformatics analyses. Here we expand and accelerate microbiota analysis by enabling cell type diversity quantification from multidimensional flow cytometry data using a supervised machine learning algorithm of standard cell type recognition (CellCognize). As a proof-of-concept, we trained neural networks with 32 microbial cell and bead standards. The resulting classifiers were extensively validated in silico on known microbiota, showing on average 80% prediction accuracy. Furthermore, the classifiers could detect shifts in microbial communities of unknown composition upon chemical amendment, comparable to results from 16S-rRNA-amplicon analysis. CellCognize was also able to quantify population growth and estimate total community biomass productivity, providing estimates similar to those from 14C-substrate incorporation. CellCognize complements current sequencing-based methods by enabling rapid routine cell diversity analysis. The pipeline is suitable to optimize cell recognition for recurring microbiota types, such as in human health or engineered systems.
Conflict of interest statement
The authors declare no competing financial interests but the following competing non-financial interests: B.D.Ö.D. is the inventor on a patent application by the University of Lausanne that covers the CellCognize concept.
Figures
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Research Materials
