

Rapid, deep and precise profiling of the plasma proteome with multi-nanoparticle protein corona
- PMID: 32699280
- PMCID: PMC7376165
- DOI: 10.1038/s41467-020-17033-7
Rapid, deep and precise profiling of the plasma proteome with multi-nanoparticle protein corona
Abstract
Large-scale, unbiased proteomics studies are constrained by the complexity of the plasma proteome. Here we report a highly parallel protein quantitation platform integrating nanoparticle (NP) protein coronas with liquid chromatography-mass spectrometry for efficient proteomic profiling. A protein corona is a protein layer adsorbed onto NPs upon contact with biofluids. Varying the physicochemical properties of engineered NPs translates to distinct protein corona patterns enabling differential and reproducible interrogation of biological samples, including deep sampling of the plasma proteome. Spike experiments confirm a linear signal response. The median coefficient of variation was 22%. We screened 43 NPs and selected a panel of 5, which detect more than 2,000 proteins from 141 plasma samples using a 96-well automated workflow in a pilot non-small cell lung cancer classification study. Our streamlined workflow combines depth of coverage and throughput with precise quantification based on unique interactions between proteins and NPs engineered for deep and scalable quantitative proteomic studies.
Conflict of interest statement
O.C.F. has financial interest in Selecta Biosciences, Tarveda Therapeutics, and Seer. R.L. is involved, compensated or uncompensated, in the entities listed in Supplementary Note 2. V.F. has financial interest in Celect and Seer. S.C. has financial interest in Kymera, PTM BioLabs, Pfizer, Biogen, and Seer. J.E.B, W.C.M., G.T., M.F., L.H., T.L.P., X.Z., R.A.C, P.A.E., M.K., H.L., E.M.E., M.M., S.F., C.S., R.B., B.H., H.X., D.H., A.S., and P.M. have financial interest in Seer. Only Seer, and no other companies mentioned here, was involved in the study design, data collection and analysis, and manuscript writing/editing.
Figures

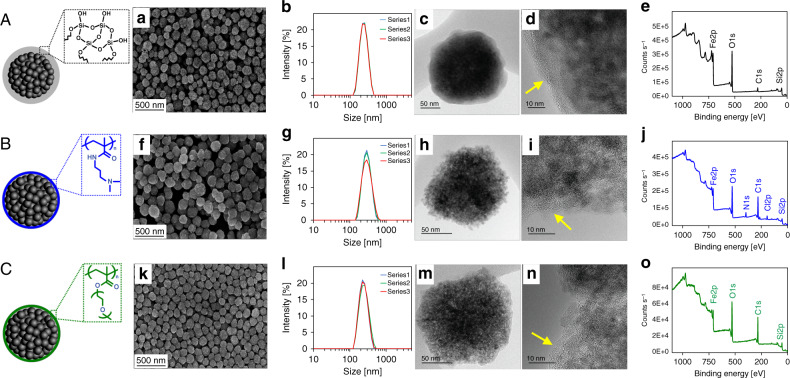

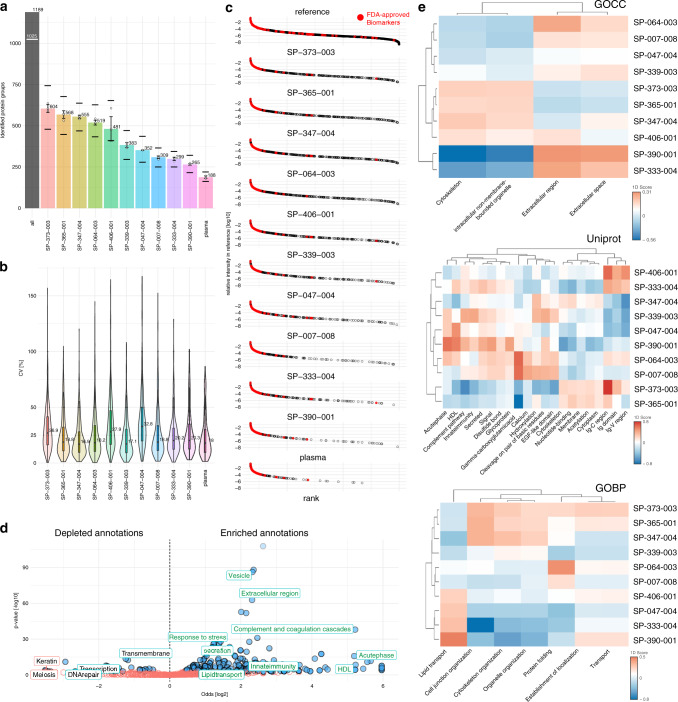
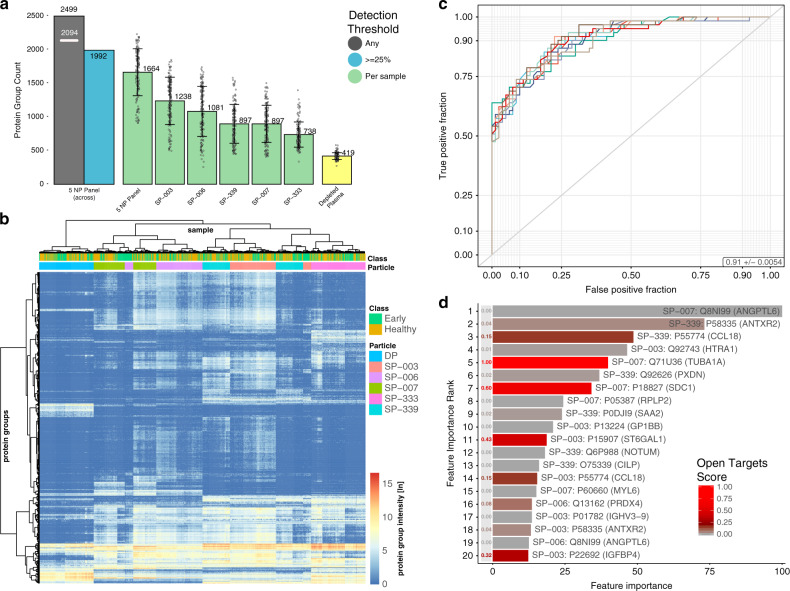
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Molecular Biology Databases
Miscellaneous
