

Accuracy of random-forest-based imputation of missing data in the presence of non-normality, non-linearity, and interaction
- PMID: 32711455
- PMCID: PMC7382855
- DOI: 10.1186/s12874-020-01080-1
Accuracy of random-forest-based imputation of missing data in the presence of non-normality, non-linearity, and interaction
Abstract
Background: Missing data are common in statistical analyses, and imputation methods based on random forests (RF) are becoming popular for handling missing data especially in biomedical research. Unlike standard imputation approaches, RF-based imputation methods do not assume normality or require specification of parametric models. However, it is still inconclusive how they perform for non-normally distributed data or when there are non-linear relationships or interactions.
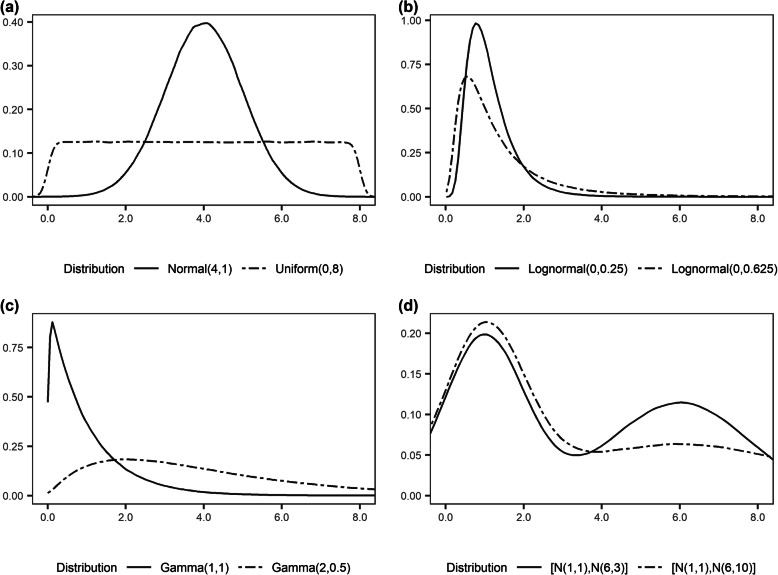
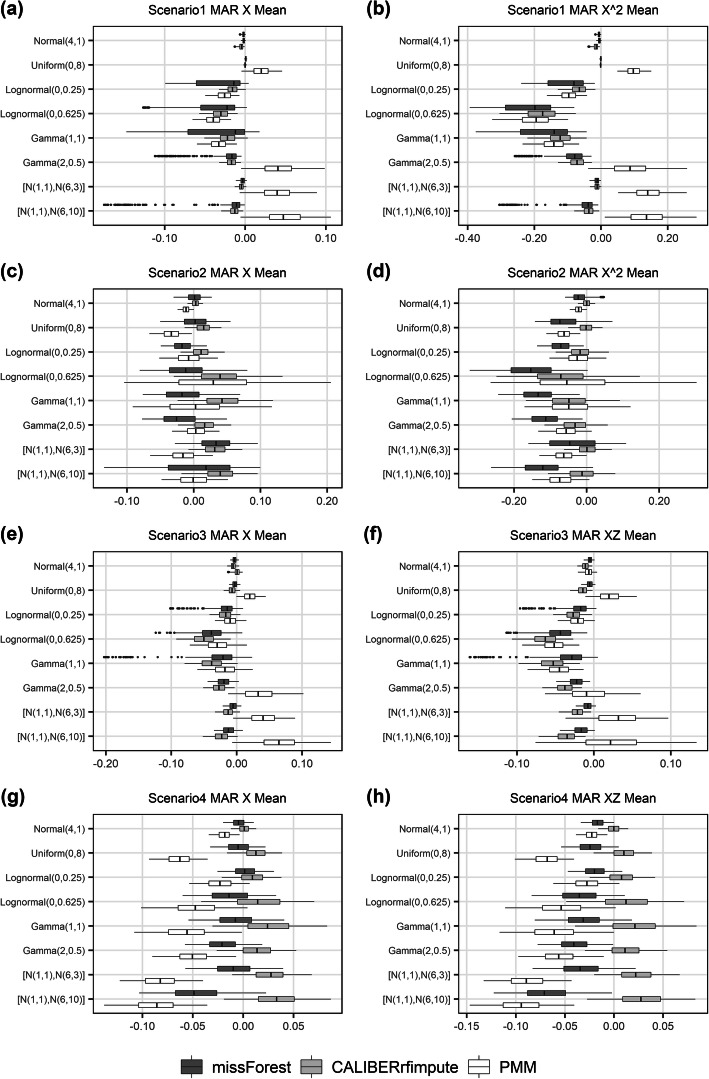
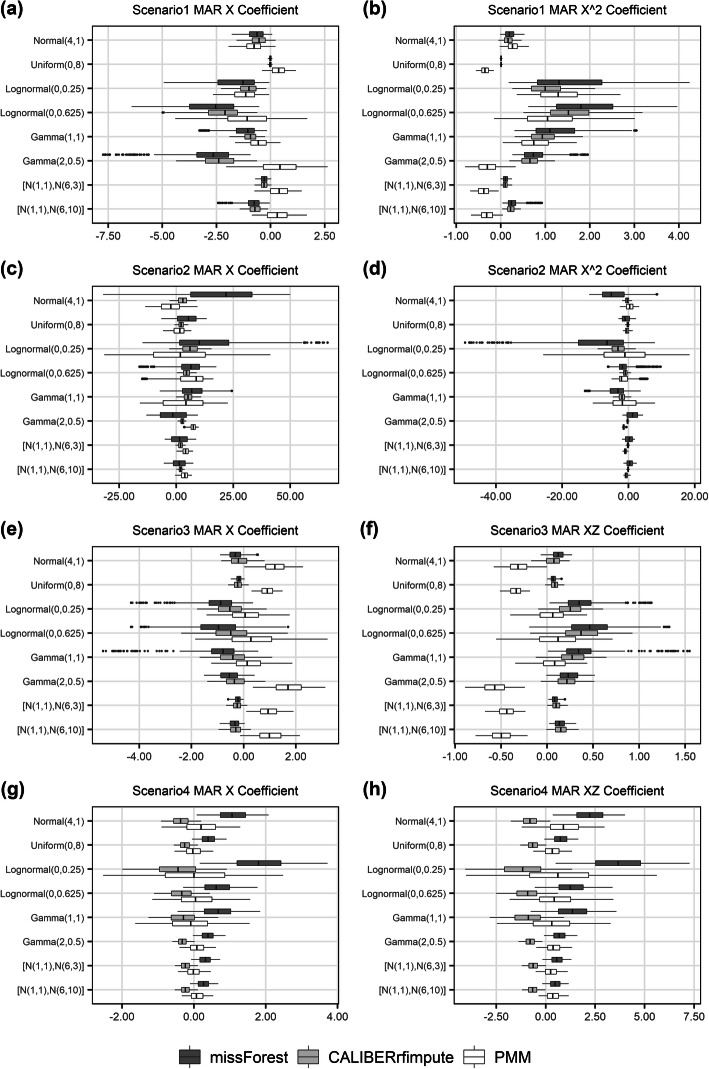
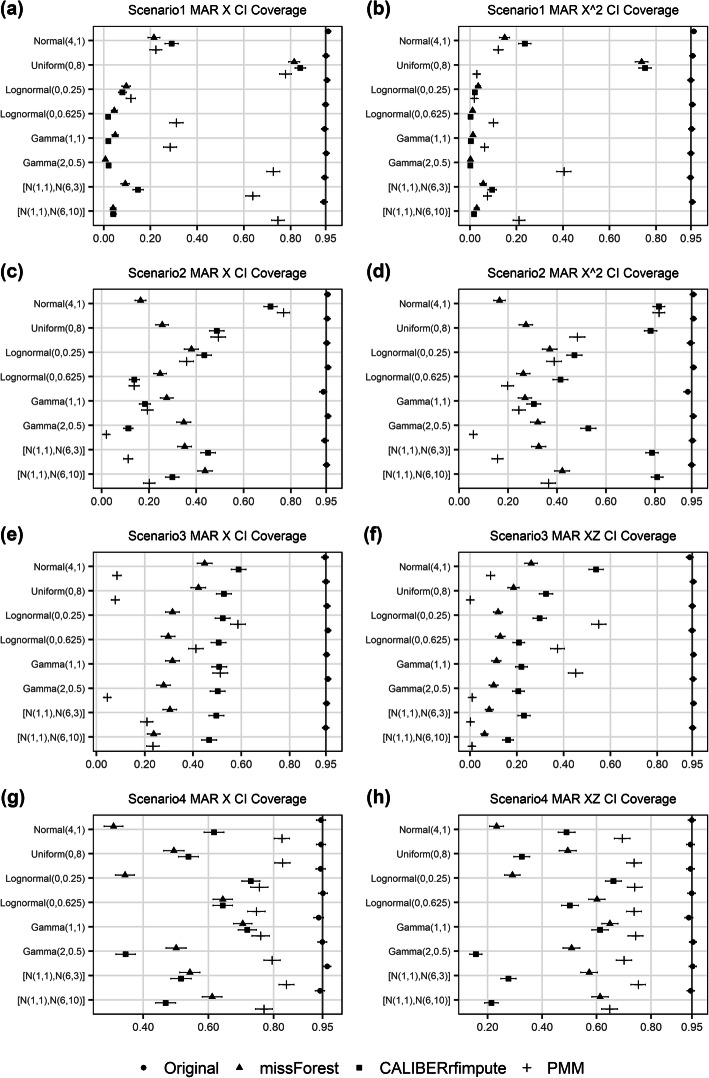
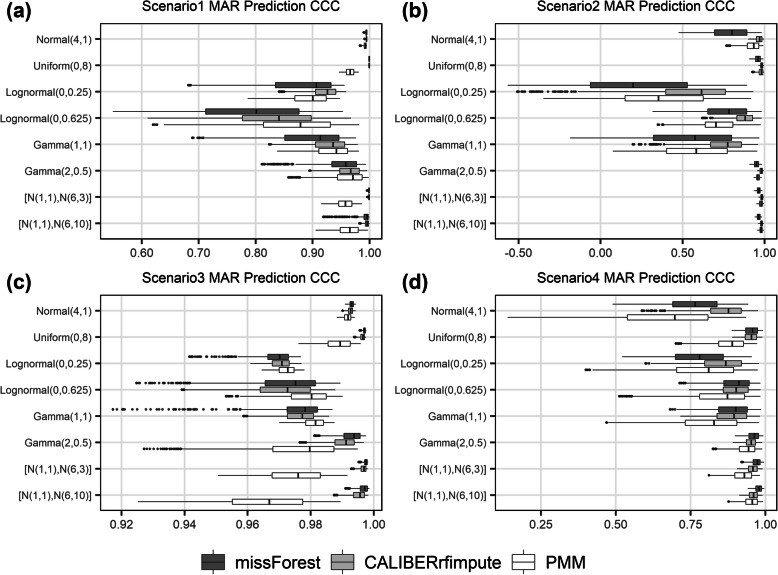
Methods: To examine the effects of these three factors, a variety of datasets were simulated with outcome-dependent missing at random (MAR) covariates, and the performances of the RF-based imputation methods missForest and CALIBERrfimpute were evaluated in comparison with predictive mean matching (PMM).
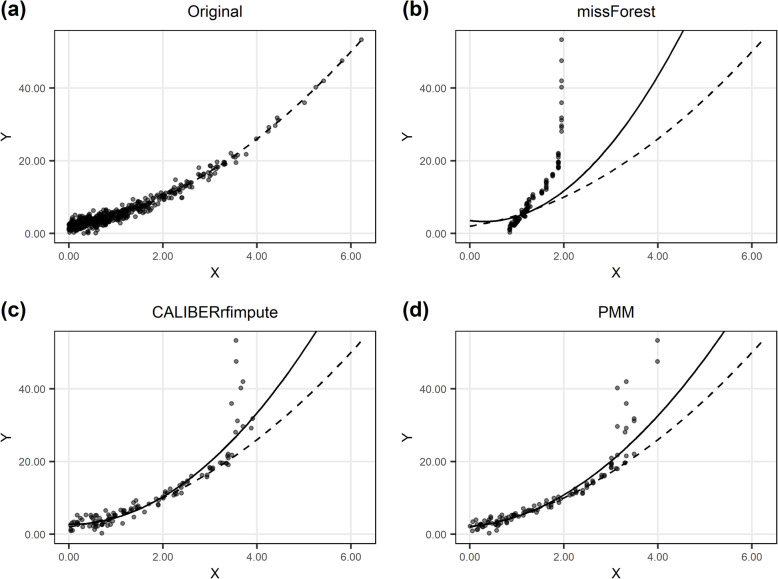
Results: Both missForest and CALIBERrfimpute have high predictive accuracy but missForest can produce severely biased regression coefficient estimates and downward biased confidence interval coverages, especially for highly skewed variables in nonlinear models. CALIBERrfimpute typically outperforms missForest when estimating regression coefficients, although its biases are still substantial and can be worse than PMM for logistic regression relationships with interaction.
Conclusions: RF-based imputation, in particular missForest, should not be indiscriminately recommended as a panacea for imputing missing data, especially when data are highly skewed and/or outcome-dependent MAR. A correct analysis requires a careful critique of the missing data mechanism and the inter-relationships between the variables in the data.
Keywords: Imputation accuracy; Missing data imputation; Random forest.
Conflict of interest statement
Authors declare that they have no competing interests.
Figures
References
-
- Van Buuren S. Flexible imputation of missing data: chapman and hall/CRC. 2018.
-
- Ramosaj B, Pauly M. Predicting missing values: A comparative study on non-parametric approaches for imputation. Comput Stat. 2019;34(4):1741–1764.
MeSH terms
Associated data
LinkOut - more resources
Full Text Sources
