

Constrained sampling from deep generative image models reveals mechanisms of human target detection
- PMID: 32729908
- PMCID: PMC7424951
- DOI: 10.1167/jov.20.7.32
Constrained sampling from deep generative image models reveals mechanisms of human target detection
Abstract
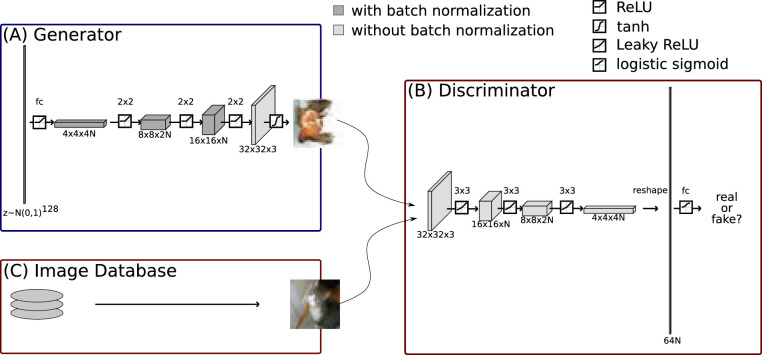
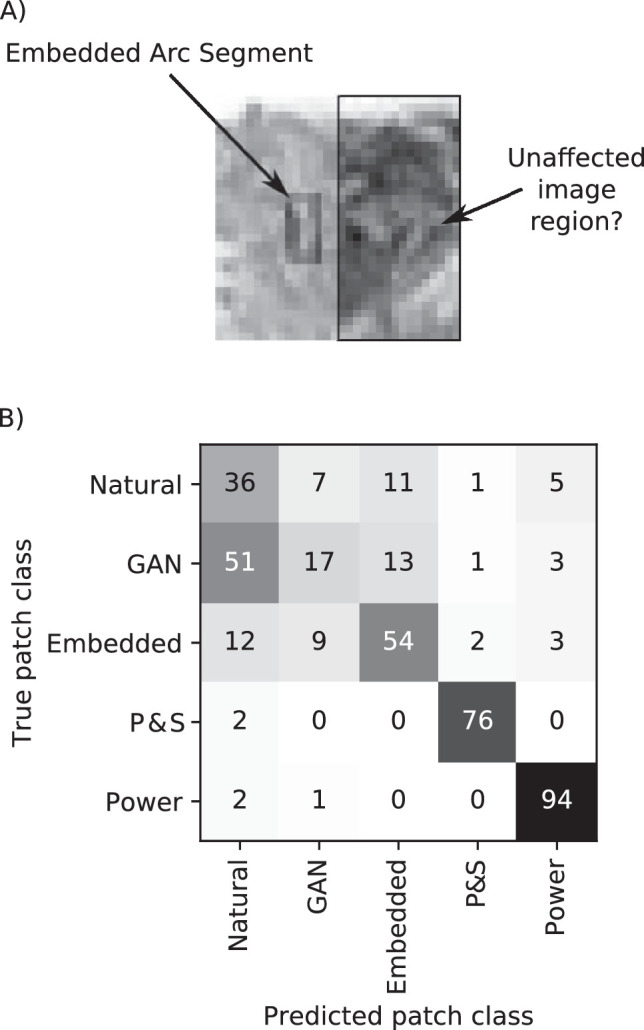
The first steps of visual processing are often described as a bank of oriented filters followed by divisive normalization. This approach has been tremendously successful at predicting contrast thresholds in simple visual displays. However, it is unclear to what extent this kind of architecture also supports processing in more complex visual tasks performed in naturally looking images. We used a deep generative image model to embed arc segments with different curvatures in naturalistic images. These images contain the target as part of the image scene, resulting in considerable appearance variation of target as well as background. Three observers localized arc targets in these images, with an average accuracy of 74.7%. Data were fit by several biologically inspired models, four standard deep convolutional neural networks (CNNs), and a five-layer CNN specifically trained for this task. Four models predicted observer responses particularly well; (1) a bank of oriented filters, similar to complex cells in primate area V1; (2) a bank of oriented filters followed by tuned gain control, incorporating knowledge about cortical surround interactions; (3) a bank of oriented filters followed by local normalization; and (4) the five-layer CNN. A control experiment with optimized stimuli based on these four models showed that the observers' data were best explained by model (2) with tuned gain control. These data suggest that standard models of early vision provide good descriptions of performance in much more complex tasks than what they were designed for, while general-purpose non linear models such as convolutional neural networks do not.
Figures










Similar articles
-
Computational mechanisms underlying cortical responses to the affordance properties of visual scenes.PLoS Comput Biol. 2018 Apr 23;14(4):e1006111. doi: 10.1371/journal.pcbi.1006111. eCollection 2018 Apr. PLoS Comput Biol. 2018. PMID: 29684011 Free PMC article.
-
Deep convolutional models improve predictions of macaque V1 responses to natural images.PLoS Comput Biol. 2019 Apr 23;15(4):e1006897. doi: 10.1371/journal.pcbi.1006897. eCollection 2019 Apr. PLoS Comput Biol. 2019. PMID: 31013278 Free PMC article.
-
fMRI volume classification using a 3D convolutional neural network robust to shifted and scaled neuronal activations.Neuroimage. 2020 Dec;223:117328. doi: 10.1016/j.neuroimage.2020.117328. Epub 2020 Sep 5. Neuroimage. 2020. PMID: 32896633
-
Visual Object Recognition: Do We (Finally) Know More Now Than We Did?Annu Rev Vis Sci. 2016 Oct 14;2:377-396. doi: 10.1146/annurev-vision-111815-114621. Epub 2016 Aug 3. Annu Rev Vis Sci. 2016. PMID: 28532357 Review.
-
From convolutional neural networks to models of higher-level cognition (and back again).Ann N Y Acad Sci. 2021 Dec;1505(1):55-78. doi: 10.1111/nyas.14593. Epub 2021 Mar 22. Ann N Y Acad Sci. 2021. PMID: 33754368 Free PMC article. Review.
Cited by
-
On the synthesis of visual illusions using deep generative models.J Vis. 2022 Jul 11;22(8):2. doi: 10.1167/jov.22.8.2. J Vis. 2022. PMID: 35833884 Free PMC article.
References
-
- Adelson E. H., & Bergen J. R. (1985). Spatiotemporal energy models for the perception of motion. Journal of the Optical Society of America A, Optics and Image Science, 2, 284–299. - PubMed
-
- Albrecht D. G., & Geisler W. S. (1991). Motion selectivity and the contrast-response function of simple cells in the visual cortex. Visual Neuroscience, 7, 531–546. - PubMed
-
- Arjovsky M., Chintala S., & Bottou L. (2017). Wasserstein GAN. In Precup D., Teh Y. W. (Eds.), Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017. Proceedings of Machine Learning Research 70.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
