

Active listening
- PMID: 32732017
- PMCID: PMC7812378
- DOI: 10.1016/j.heares.2020.107998
Active listening
Abstract
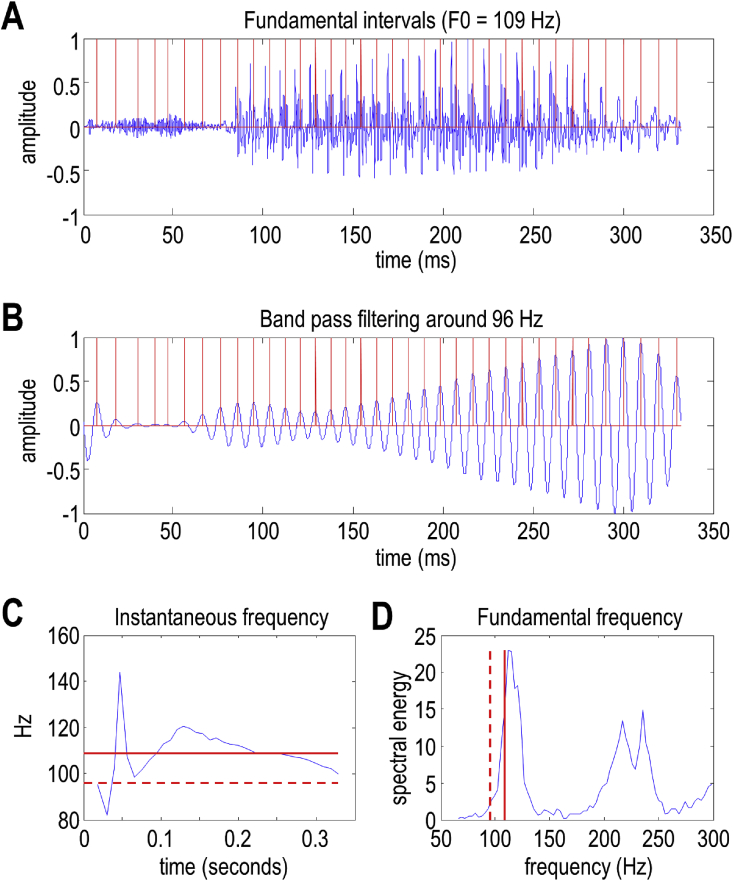
This paper introduces active listening, as a unified framework for synthesising and recognising speech. The notion of active listening inherits from active inference, which considers perception and action under one universal imperative: to maximise the evidence for our (generative) models of the world. First, we describe a generative model of spoken words that simulates (i) how discrete lexical, prosodic, and speaker attributes give rise to continuous acoustic signals; and conversely (ii) how continuous acoustic signals are recognised as words. The 'active' aspect involves (covertly) segmenting spoken sentences and borrows ideas from active vision. It casts speech segmentation as the selection of internal actions, corresponding to the placement of word boundaries. Practically, word boundaries are selected that maximise the evidence for an internal model of how individual words are generated. We establish face validity by simulating speech recognition and showing how the inferred content of a sentence depends on prior beliefs and background noise. Finally, we consider predictive validity by associating neuronal or physiological responses, such as the mismatch negativity and P300, with belief updating under active listening, which is greatest in the absence of accurate prior beliefs about what will be heard next.
Keywords: Audition; Segmentation; Variational Bayes; Voice; active inference; active listening; speech recognition.
Copyright © 2020 The Authors. Published by Elsevier B.V. All rights reserved.
Conflict of interest statement
Declaration of competing interest The authors have no disclosures or conflict of interest.
Figures











References
-
- Abberton E., Fourcin A.J. Intonation and speaker identification. Lang. Speech. 1978;21(4):305–318. - PubMed
-
- Altenberg E.P. The perception of word boundaries in a second language. Sec. Lang. Res. 2005;21(4):325–358.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
