

Machine learning for early detection of sepsis: an internal and temporal validation study
- PMID: 32734166
- PMCID: PMC7382639
- DOI: 10.1093/jamiaopen/ooaa006
Machine learning for early detection of sepsis: an internal and temporal validation study
Abstract
Objective: Determine if deep learning detects sepsis earlier and more accurately than other models. To evaluate model performance using implementation-oriented metrics that simulate clinical practice.
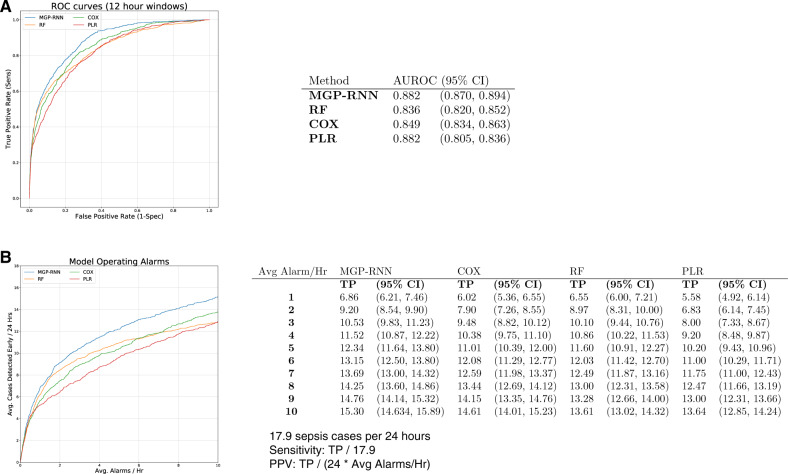
Materials and methods: We trained internally and temporally validated a deep learning model (multi-output Gaussian process and recurrent neural network [MGP-RNN]) to detect sepsis using encounters from adult hospitalized patients at a large tertiary academic center. Sepsis was defined as the presence of 2 or more systemic inflammatory response syndrome (SIRS) criteria, a blood culture order, and at least one element of end-organ failure. The training dataset included demographics, comorbidities, vital signs, medication administrations, and labs from October 1, 2014 to December 1, 2015, while the temporal validation dataset was from March 1, 2018 to August 31, 2018. Comparisons were made to 3 machine learning methods, random forest (RF), Cox regression (CR), and penalized logistic regression (PLR), and 3 clinical scores used to detect sepsis, SIRS, quick Sequential Organ Failure Assessment (qSOFA), and National Early Warning Score (NEWS). Traditional discrimination statistics such as the C-statistic as well as metrics aligned with operational implementation were assessed.
Results: The training set and internal validation included 42 979 encounters, while the temporal validation set included 39 786 encounters. The C-statistic for predicting sepsis within 4 h of onset was 0.88 for the MGP-RNN compared to 0.836 for RF, 0.849 for CR, 0.822 for PLR, 0.756 for SIRS, 0.619 for NEWS, and 0.481 for qSOFA. MGP-RNN detected sepsis a median of 5 h in advance. Temporal validation assessment continued to show the MGP-RNN outperform all 7 clinical risk score and machine learning comparisons.
Conclusions: We developed and validated a novel deep learning model to detect sepsis. Using our data elements and feature set, our modeling approach outperformed other machine learning methods and clinical scores.
Keywords: ROC curve; adult; clinical; decision; electronic health records/statistics and numerical data; emergency service; hospital/statistics and numerical data; hospitalization/statistics and numerical data; machine learning; retrospective studies; sepsis/mortality; support systems.
© The Author(s) 2020. Published by Oxford University Press on behalf of the American Medical Informatics Association.
Figures



References
-
- Liu V, Escobar GJ, Greene JD, et al. Hospital deaths in patients with sepsis from 2 independent cohorts. JAMA 2014; 312 (1): 90–2. - PubMed
-
- Epstein L, Dantes R, Magill S, Fiore A.. Varying estimates of sepsis mortality using death certificates and administrative codes—United States, 1999-2014. MMWR Morb Mortal Wkly Rep 2016; 65 (13): 342–5. - PubMed
LinkOut - more resources
Full Text Sources
Miscellaneous