

This is a preprint.
Large-scale Multi-omic Analysis of COVID-19 Severity
- PMID: 32743614
- PMCID: PMC7388490
- DOI: 10.1101/2020.07.17.20156513
Large-scale Multi-omic Analysis of COVID-19 Severity
Update in
-
Large-Scale Multi-omic Analysis of COVID-19 Severity.Cell Syst. 2021 Jan 20;12(1):23-40.e7. doi: 10.1016/j.cels.2020.10.003. Epub 2020 Oct 8. Cell Syst. 2021. PMID: 33096026 Free PMC article.
Abstract
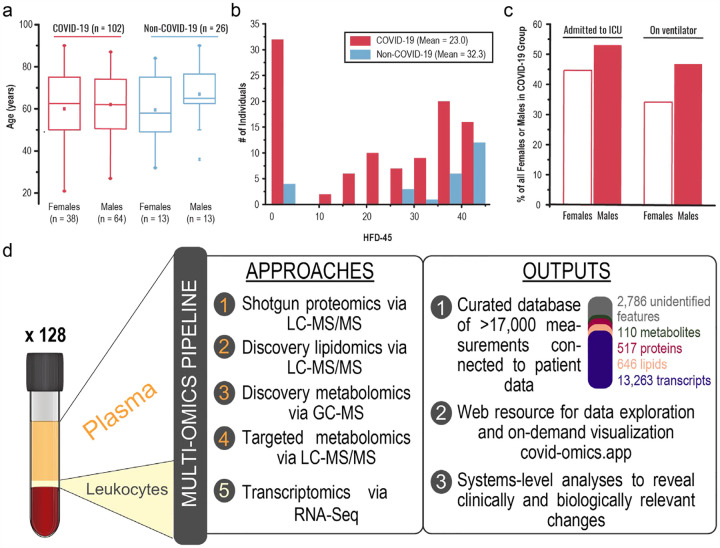
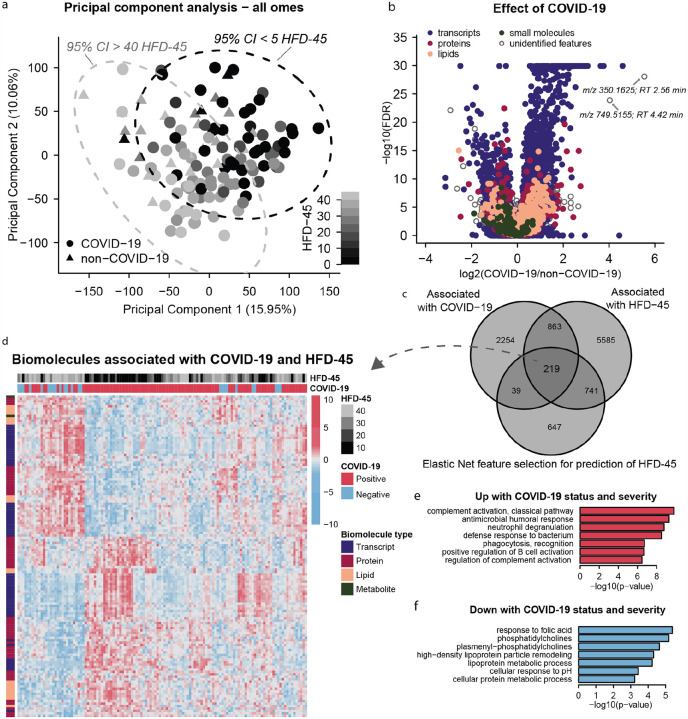
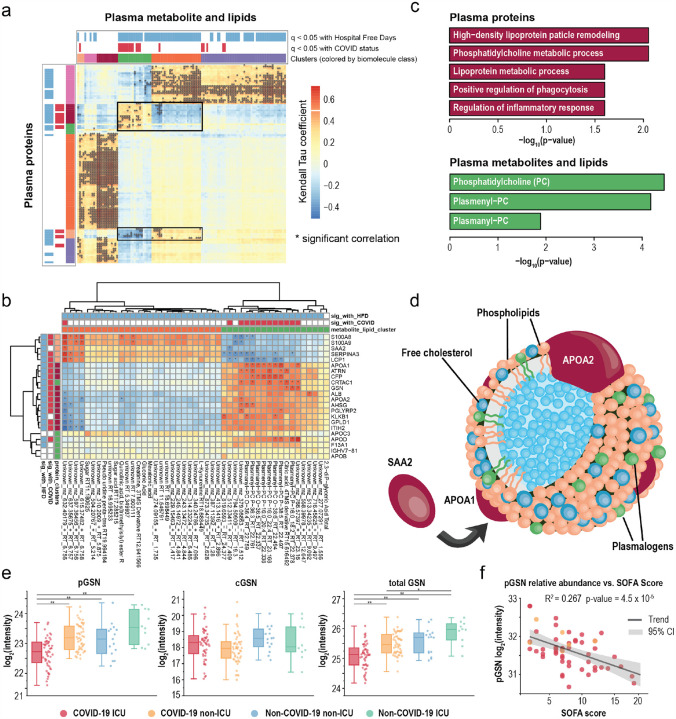
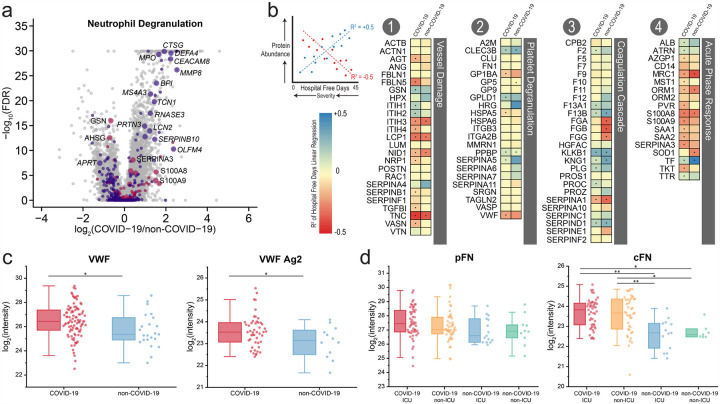
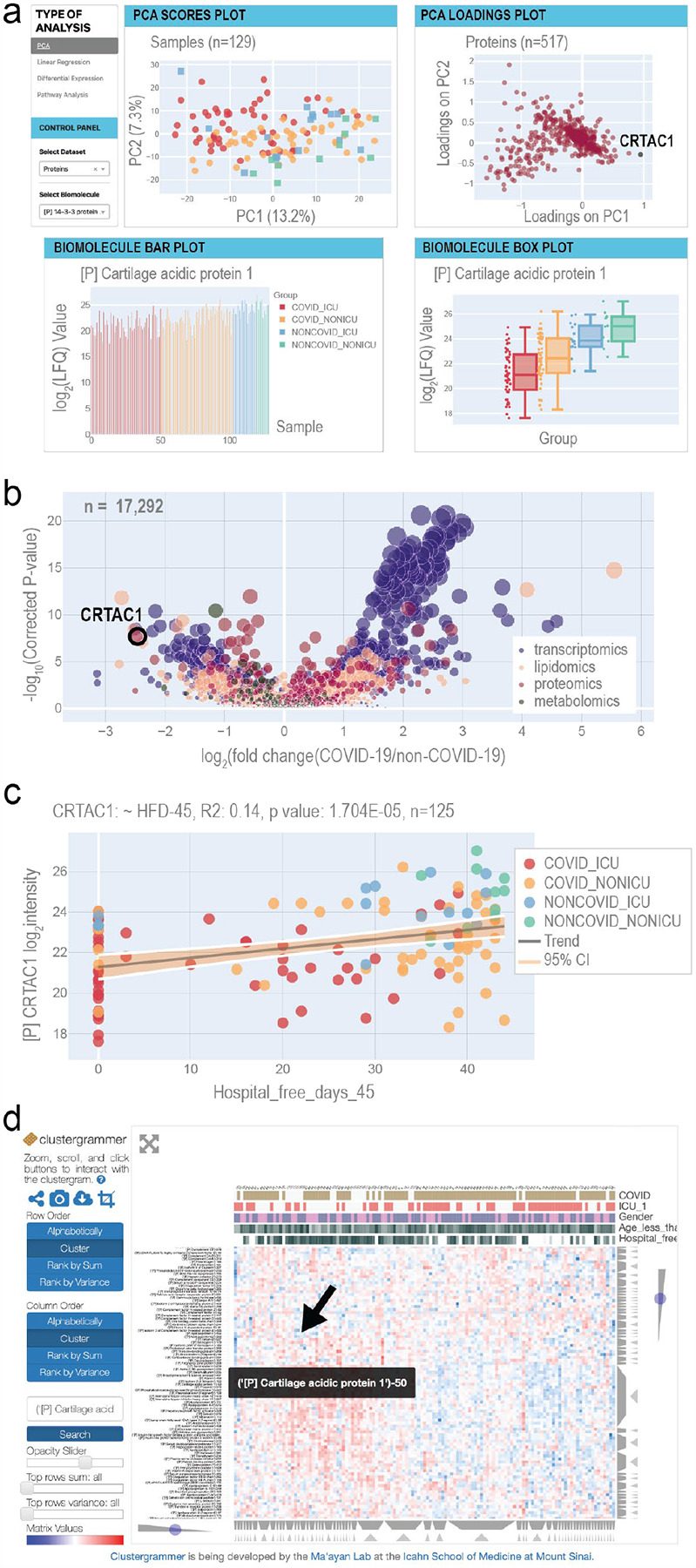
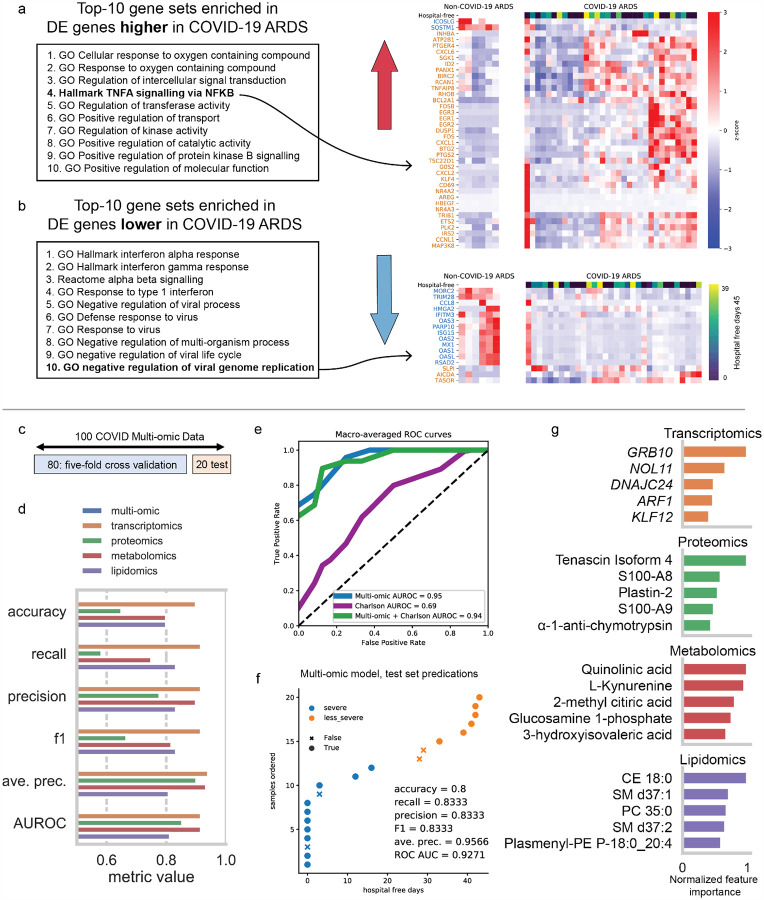
We performed RNA-Seq and high-resolution mass spectrometry on 128 blood samples from COVID-19 positive and negative patients with diverse disease severities. Over 17,000 transcripts, proteins, metabolites, and lipids were quantified and associated with clinical outcomes in a curated relational database, uniquely enabling systems analysis and cross-ome correlations to molecules and patient prognoses. We mapped 219 molecular features with high significance to COVID-19 status and severity, many involved in complement activation, dysregulated lipid transport, and neutrophil activation. We identified sets of covarying molecules, e.g., protein gelsolin and metabolite citrate or plasmalogens and apolipoproteins, offering pathophysiological insights and therapeutic suggestions. The observed dysregulation of platelet function, blood coagulation, acute phase response, and endotheliopathy further illuminated the unique COVID-19 phenotype. We present a web-based tool (covid-omics.app) enabling interactive exploration of our compendium and illustrate its utility through a comparative analysis with published data and a machine learning approach for prediction of COVID-19 severity.
Figures
Comment in
-
COVID-19 biomarkers for severity mapped to polycystic ovary syndrome.J Transl Med. 2020 Dec 22;18(1):490. doi: 10.1186/s12967-020-02669-2. J Transl Med. 2020. PMID: 33353554 Free PMC article. No abstract available.
References
-
- Antcliffe D.B., Burnham K.L., Al-Beidh F., Santhakumaran S., Brett S.J., Hinds C.J., Ashby D., Knight J.C., and Gordon A.C. (2019). Transcriptomic Signatures in Sepsis and a Differential Response to Steroids. From the VANISH Randomized Trial. Am. J. Respir. Crit. Care Med. 199, 980–986. - PMC - PubMed
-
- Arndt S., Turvey C., and Andreasen N.C. (1999). Correlating and predicting psychiatric symptom ratings: Spearman’s r versus Kendall’s tau correlation. J. Psychiatr. Res. 33, 97–104. - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials