

Deep neural networks enable quantitative movement analysis using single-camera videos
- PMID: 32792511
- PMCID: PMC7426855
- DOI: 10.1038/s41467-020-17807-z
Deep neural networks enable quantitative movement analysis using single-camera videos
Abstract
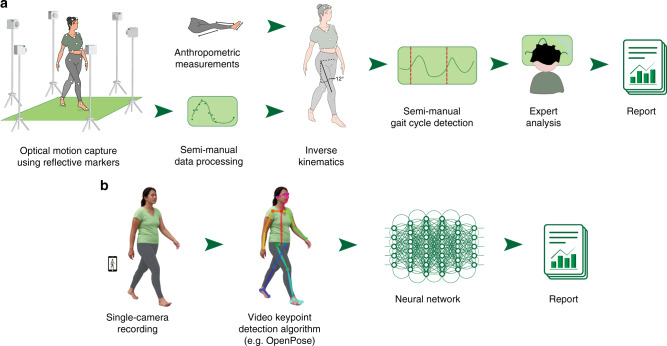
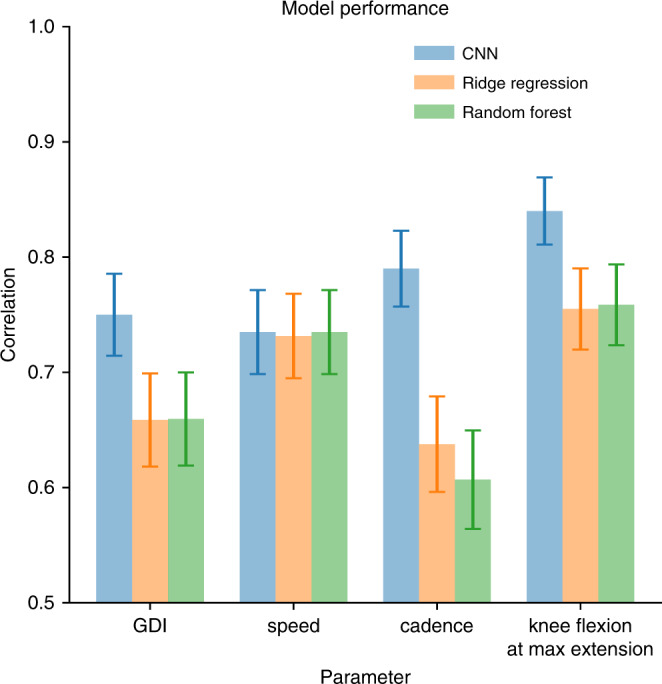
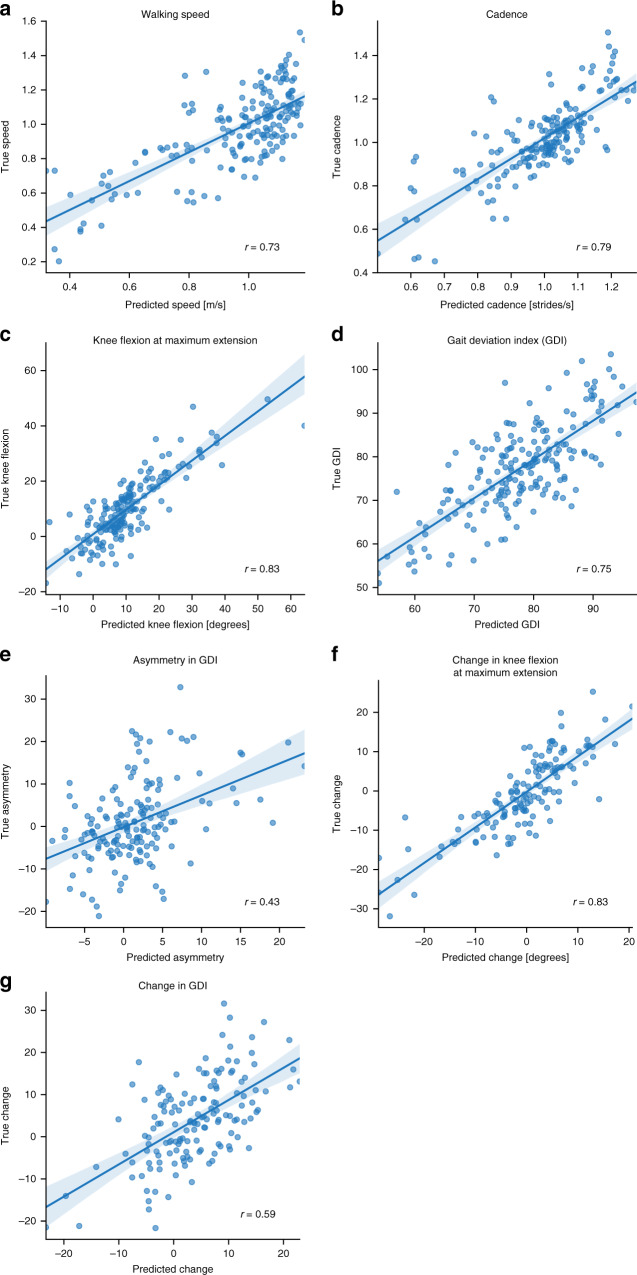
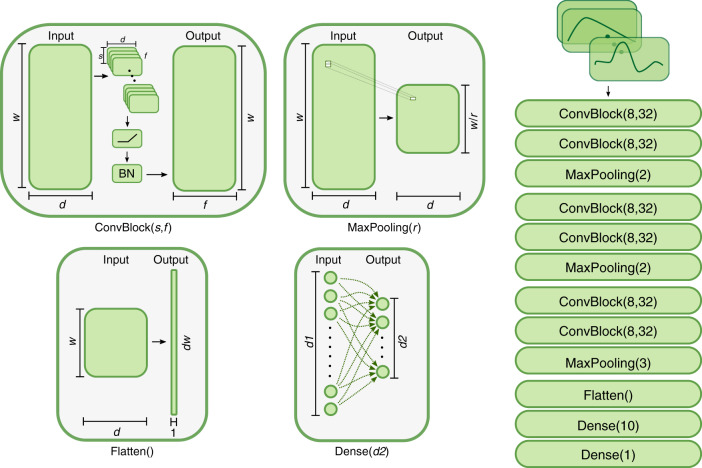
Many neurological and musculoskeletal diseases impair movement, which limits people's function and social participation. Quantitative assessment of motion is critical to medical decision-making but is currently possible only with expensive motion capture systems and highly trained personnel. Here, we present a method for predicting clinically relevant motion parameters from an ordinary video of a patient. Our machine learning models predict parameters include walking speed (r = 0.73), cadence (r = 0.79), knee flexion angle at maximum extension (r = 0.83), and Gait Deviation Index (GDI), a comprehensive metric of gait impairment (r = 0.75). These correlation values approach the theoretical limits for accuracy imposed by natural variability in these metrics within our patient population. Our methods for quantifying gait pathology with commodity cameras increase access to quantitative motion analysis in clinics and at home and enable researchers to conduct large-scale studies of neurological and musculoskeletal disorders.
Conflict of interest statement
The authors declare no competing interests.
Figures

References
-
- von Schroeder HP, Coutts RD, Lyden PD, Billings E, Jr, Nickel VL. Gait parameters following stroke: a practical assessment. J. Rehabil. Res. Dev. 1995;32:25–31. - PubMed
-
- Gage, J. R., Schwartz, M. H., Koop, S. E. & Novacheck, T. F. The identification and treatment of gait problems in cerebral palsy. (John Wiley & Sons, 2009).
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
