

Prospective Deployment of Deep Learning in MRI: A Framework for Important Considerations, Challenges, and Recommendations for Best Practices
- PMID: 32830874
- PMCID: PMC8639049
- DOI: 10.1002/jmri.27331
Prospective Deployment of Deep Learning in MRI: A Framework for Important Considerations, Challenges, and Recommendations for Best Practices
Abstract
Artificial intelligence algorithms based on principles of deep learning (DL) have made a large impact on the acquisition, reconstruction, and interpretation of MRI data. Despite the large number of retrospective studies using DL, there are fewer applications of DL in the clinic on a routine basis. To address this large translational gap, we review the recent publications to determine three major use cases that DL can have in MRI, namely, that of model-free image synthesis, model-based image reconstruction, and image or pixel-level classification. For each of these three areas, we provide a framework for important considerations that consist of appropriate model training paradigms, evaluation of model robustness, downstream clinical utility, opportunities for future advances, as well recommendations for best current practices. We draw inspiration for this framework from advances in computer vision in natural imaging as well as additional healthcare fields. We further emphasize the need for reproducibility of research studies through the sharing of datasets and software. LEVEL OF EVIDENCE: 5 TECHNICAL EFFICACY STAGE: 2.
Keywords: MRI reconstruction; artificial intelligence; classification; convolutional neural networks; deep learning; segmentation.
© 2020 International Society for Magnetic Resonance in Medicine.
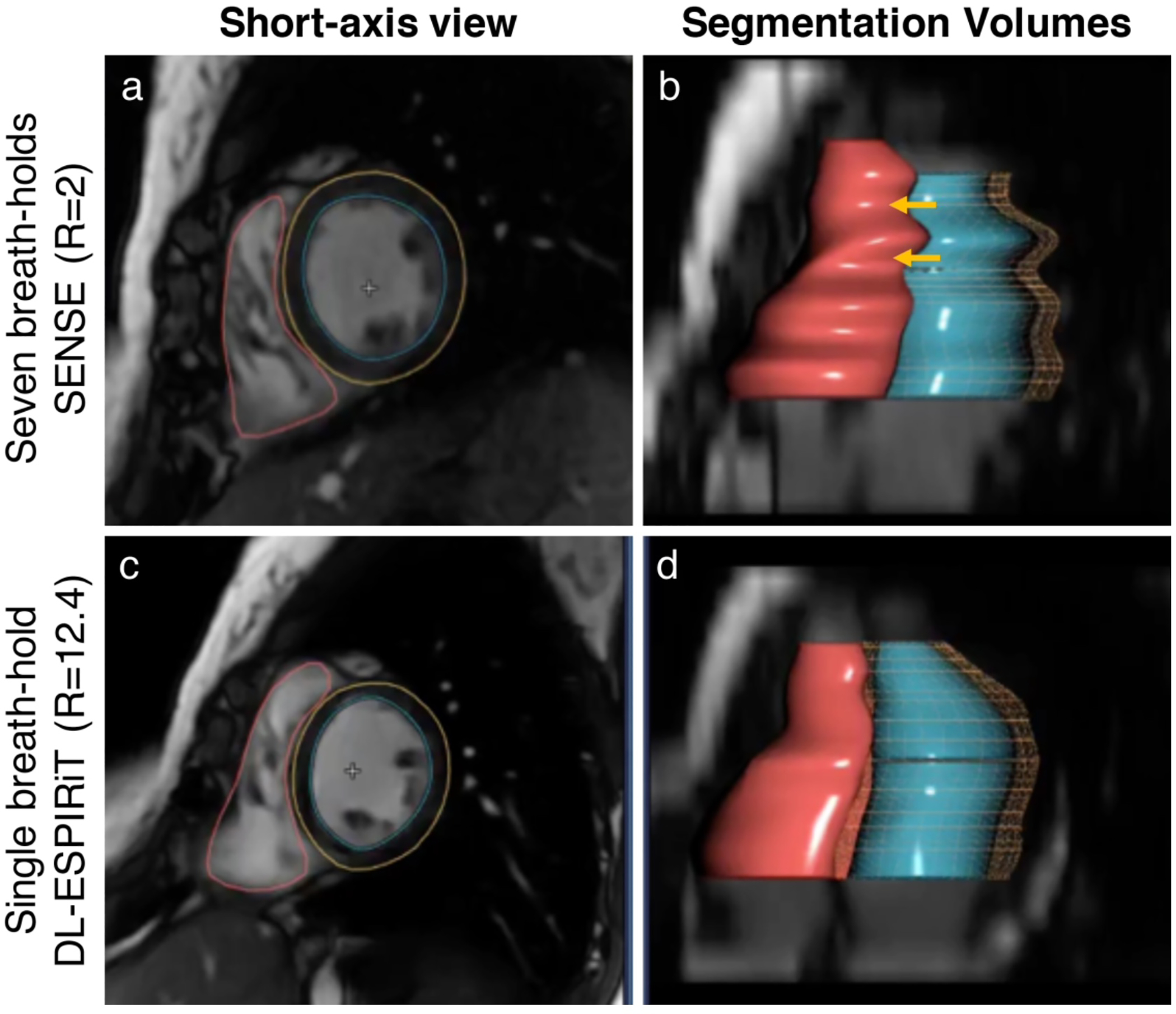
Figures







References
-
- Greenspan H, van Ginneken B, Summers RM: Guest Editorial Deep Learning in Medical Imaging: Overview and Future Promise of an Exciting New Technique. IEEE Trans Med Imaging 2016; 35:1153–1159.
-
- Lundervold AS, Lundervold A: An overview of deep learning in medical imaging focusing on MRI. Z Med Phys 2019; 29:102–127. - PubMed
-
- LeCun Y, Bengio Y, Hinton G: Deep learning. Nature 2015; 521:436–444. - PubMed
-
- FDA Cleared AI Algorithms
Publication types
MeSH terms
Grants and funding
- GE Healthcare (research support) and Philips. The content is solely the responsibility of the authors and does not necessarily represent the official views of any sponsoring institution
- R01 EB002524/NH/NIH HHS/United States
- P41 EB015891/EB/NIBIB NIH HHS/United States
- GE Healthcare
- R01 AR063643/NH/NIH HHS/United States
- Philips
- R01 LM012966/LM/NLM NIH HHS/United States
- K24 AR062068/NH/NIH HHS/United States
- NIH R01 AR063643/National Institutes of Health (NIH)
- R01 EB002524/EB/NIBIB NIH HHS/United States
- R01 EB009690/EB/NIBIB NIH HHS/United States
- R01 AR063643/AR/NIAMS NIH HHS/United States
- R01 EB009690/NH/NIH HHS/United States
- R01 AR077604/AR/NIAMS NIH HHS/United States
- K24 AR062068/AR/NIAMS NIH HHS/United States
- R01 LM012966/NH/NIH HHS/United States
- P41 EB015891/NH/NIH HHS/United States
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
Miscellaneous
