

Dynamic causal modelling of COVID-19
- PMID: 32832701
- PMCID: PMC7431977
- DOI: 10.12688/wellcomeopenres.15881.2
Dynamic causal modelling of COVID-19
Abstract
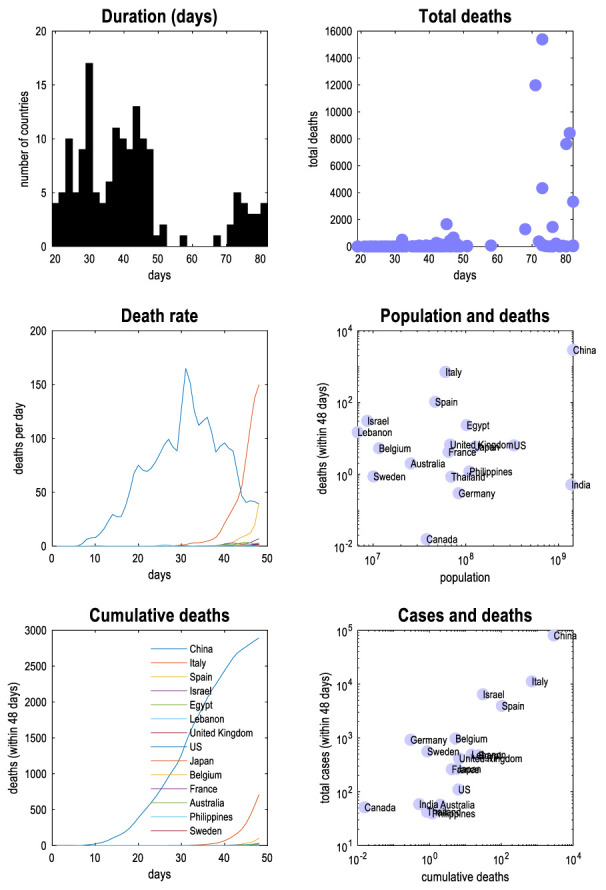
This technical report describes a dynamic causal model of the spread of coronavirus through a population. The model is based upon ensemble or population dynamics that generate outcomes, like new cases and deaths over time. The purpose of this model is to quantify the uncertainty that attends predictions of relevant outcomes. By assuming suitable conditional dependencies, one can model the effects of interventions (e.g., social distancing) and differences among populations (e.g., herd immunity) to predict what might happen in different circumstances. Technically, this model leverages state-of-the-art variational (Bayesian) model inversion and comparison procedures, originally developed to characterise the responses of neuronal ensembles to perturbations. Here, this modelling is applied to epidemiological populations-to illustrate the kind of inferences that are supported and how the model per se can be optimised given timeseries data. Although the purpose of this paper is to describe a modelling protocol, the results illustrate some interesting perspectives on the current pandemic; for example, the nonlinear effects of herd immunity that speak to a self-organised mitigation process.
Keywords: Bayesian; compartmental models; coronavirus; dynamic causal modelling; epidemiology; variational.
Copyright: © 2020 Friston KJ et al.
Conflict of interest statement
No competing interests were disclosed.
Figures












References
-
- Berger JO: Statistical decision theory and Bayesian analysis.Springer, New York; London. 2011. 10.1007/978-1-4757-4286-2 - DOI
-
- Bressloff PC, Newby JM: Stochastic models of intracellular transport. Rev Mod Phys. 2013;85:135–196. 10.1103/RevModPhys.85.135 - DOI
-
- Davidson L: Uncertainty in Economics. Uncertainty, International Money, Employment and Theory: Volume 3: The Collected Writings of Paul Davidson.Palgrave Macmillan UK London. 1999;30–37. 10.1007/978-1-349-14991-9_2 - DOI
Associated data
Grants and funding
LinkOut - more resources
Full Text Sources
