

Molecular biology of coronaviruses: current knowledge
- PMID: 32835122
- PMCID: PMC7430346
- DOI: 10.1016/j.heliyon.2020.e04743
Molecular biology of coronaviruses: current knowledge
Abstract
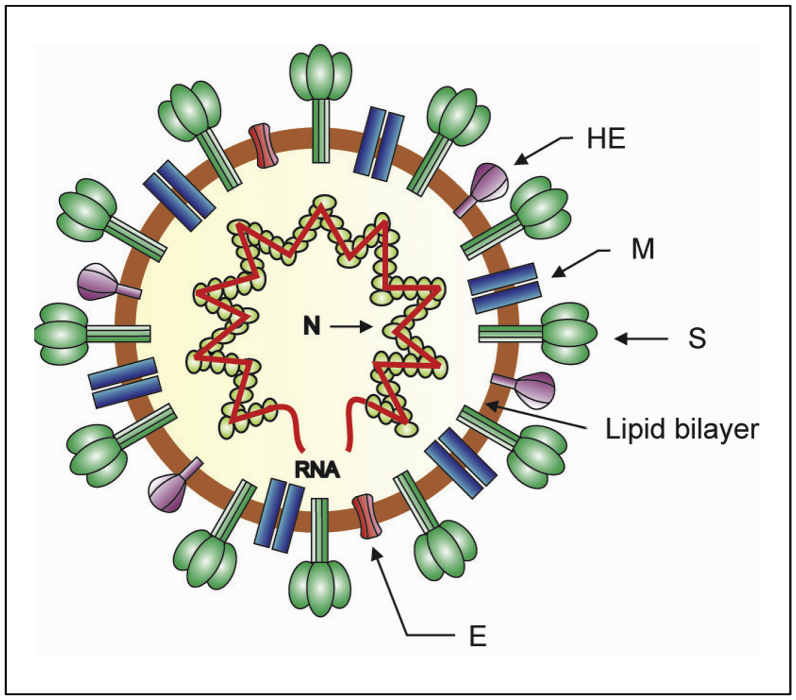
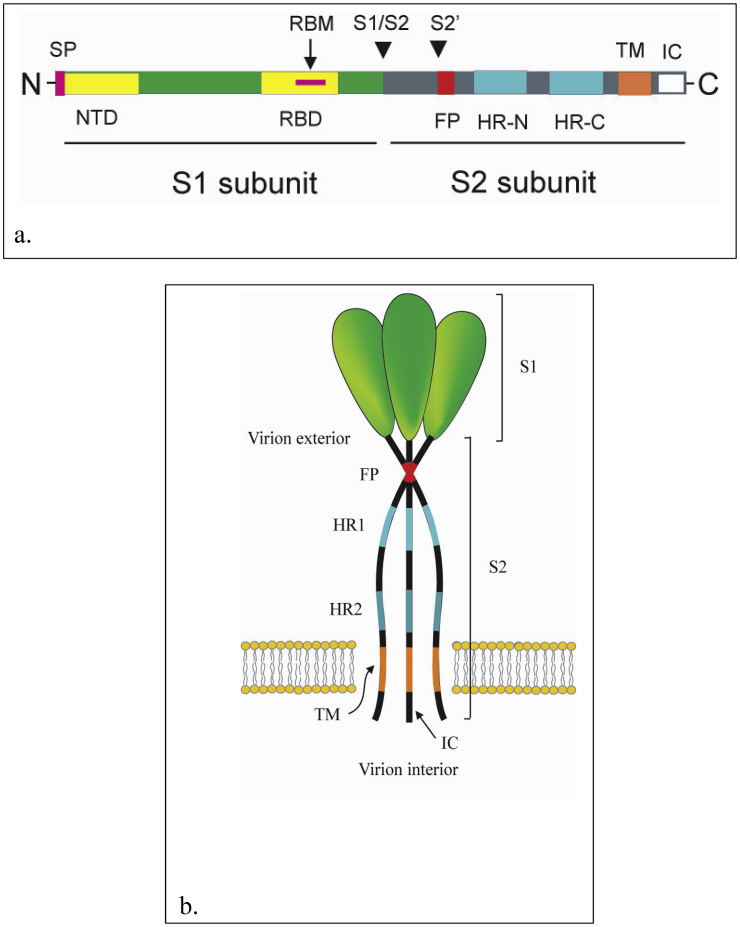
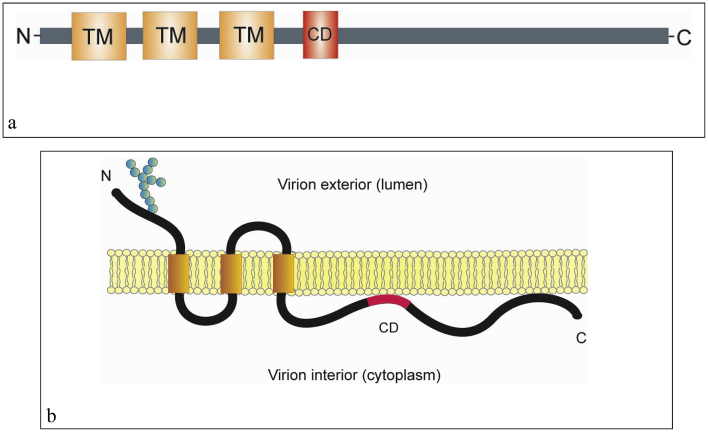
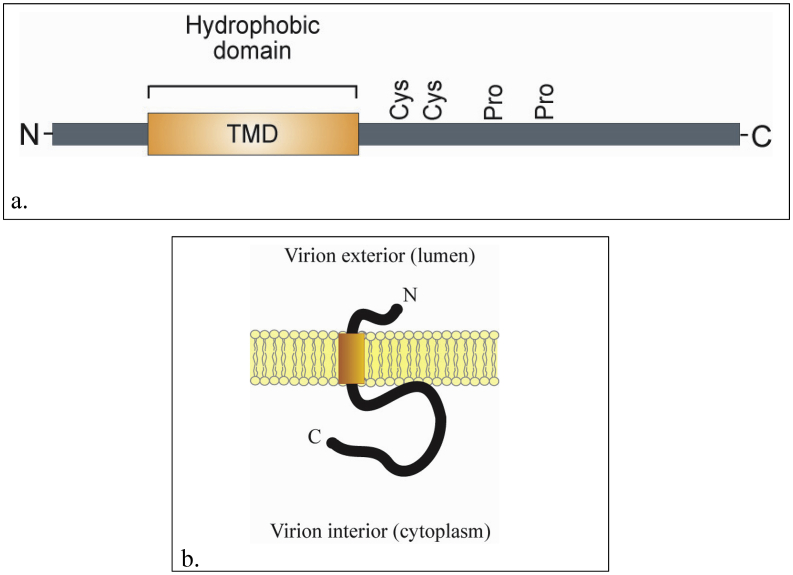
The emergence of the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) late December 2019 in Wuhan, China, marked the third introduction of a highly pathogenic coronavirus into the human population in the twenty-first century. The constant spillover of coronaviruses from natural hosts to humans has been linked to human activities and other factors. The seriousness of this infection and the lack of effective, licensed countermeasures clearly underscore the need of more detailed and comprehensive understanding of coronavirus molecular biology. Coronaviruses are large, enveloped viruses with a positive sense single-stranded RNA genome. Currently, coronaviruses are recognized as one of the most rapidly evolving viruses due to their high genomic nucleotide substitution rates and recombination. At the molecular level, the coronaviruses employ complex strategies to successfully accomplish genome expression, virus particle assembly and virion progeny release. As the health threats from coronaviruses are constant and long-term, understanding the molecular biology of coronaviruses and controlling their spread has significant implications for global health and economic stability. This review is intended to provide an overview of our current basic knowledge of the molecular biology of coronaviruses, which is important as basic knowledge for the development of coronavirus countermeasures.
Keywords: Biochemistry; Cell biology; Coronaviruses; Covid-19; Genetics; MERS-CoV; Microbiology; Molecular biology; SARS-CoV; SARS-CoV-2; Virology.
© 2020 The Author(s).
Figures
References
-
- Adedeji A.O., Lazarus H. Biochemical characterization of Middle East respiratory syndrome coronavirus helicase. mSphere. 2016;1:1–14. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5014916/ - PMC - PubMed
-
- Anand K., Ziebuhr J., Wadhwani P., Mesters J.R., Hilgenfeld R. Coronavirus main proteinase (3CLpro) structure: basis for design of anti-SARS drugs. Science. 2003;300:1763–1767. https://science.sciencemag.org/content/300/5626/1763 - PubMed
-
- Angelini A.M., Akhlaghpour M., Neuman B.W., Buchmeier M.J. Severe acute respiratory syndrome coronavirus nonstructural proteins 3, 4, and 6 induce double-membrane vesicles. mBio. 2013;4:1–10. https://mbio.asm.org/content/4/4/e00524-13 - PMC - PubMed
-
- Anindita P.D., Sasaki M., Setiyono A., Handharyani E., Orba Y., Kobayashi S., Rahmadani I., Taha S., Adiani S., Subangkit M., Nakamura I., Sawa H., Kimura T. Detection of coronavirus genomes in Moluccan naked-backed fruit bats in Indonesia. Arch. Virol. 2015;160:1113–1118. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7086880/ - PMC - PubMed
Publication types
LinkOut - more resources
Full Text Sources
Research Materials
Miscellaneous
