

Understanding the role of individual units in a deep neural network
- PMID: 32873639
- PMCID: PMC7720226
- DOI: 10.1073/pnas.1907375117
Understanding the role of individual units in a deep neural network
Abstract
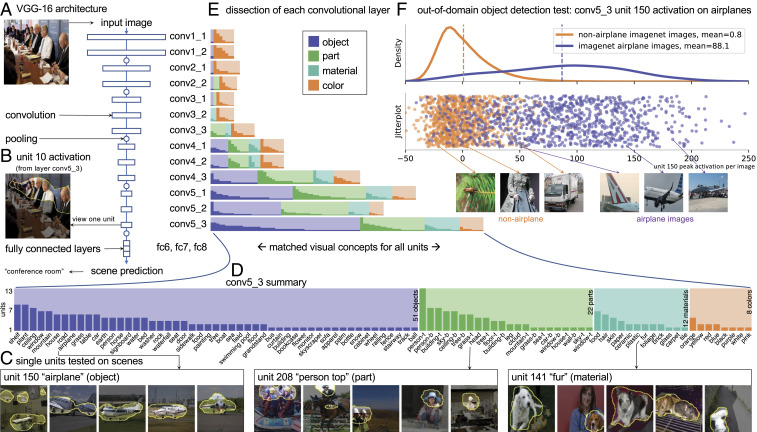
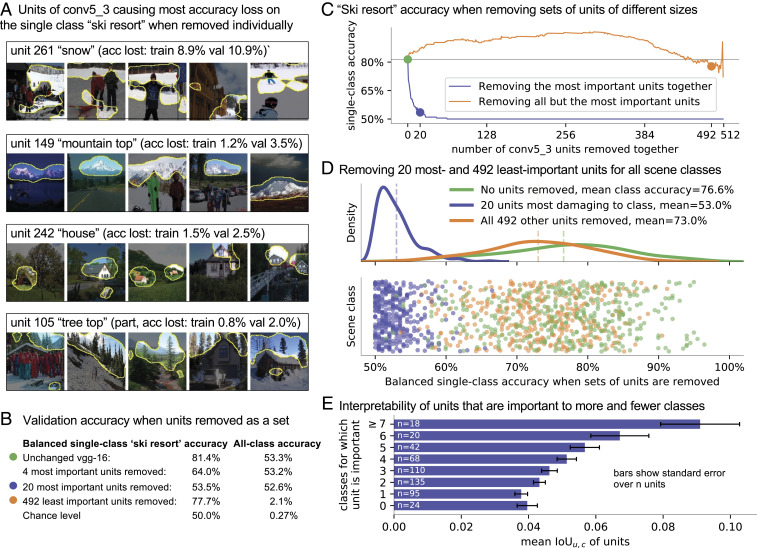
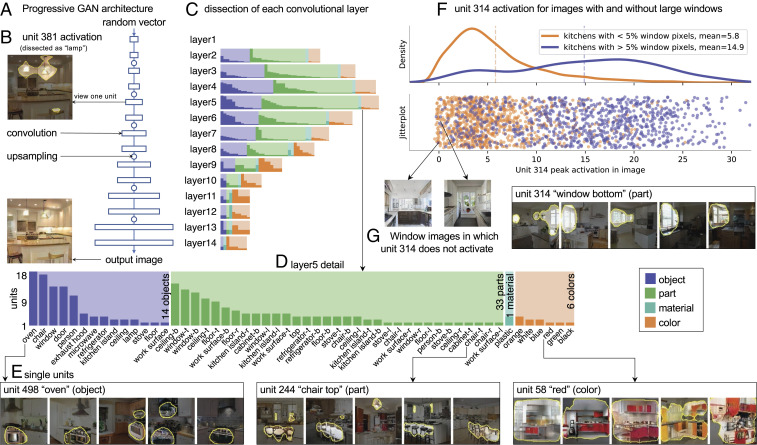
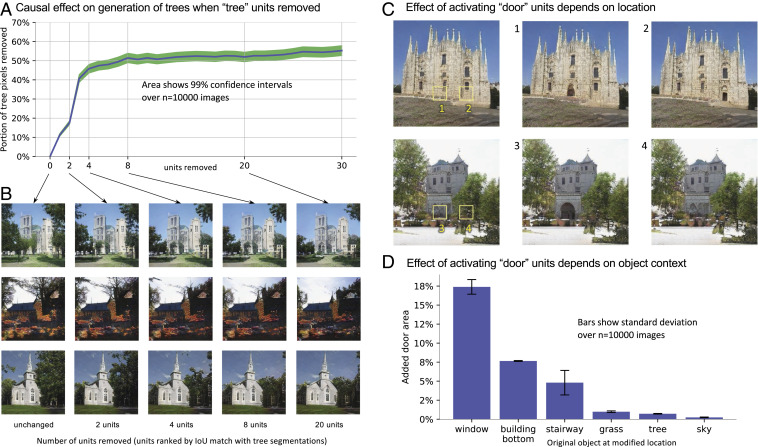
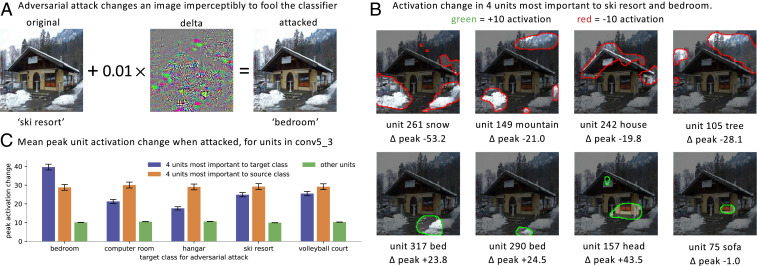
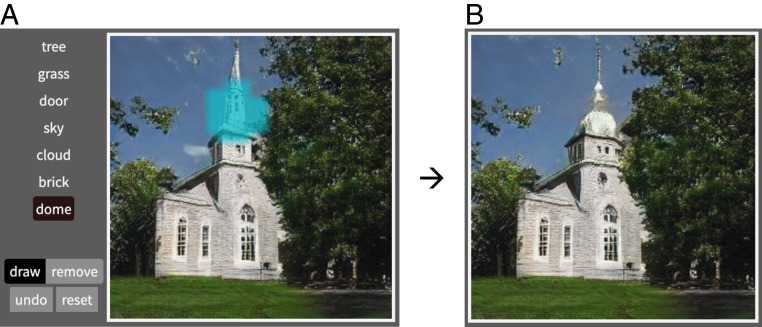
Deep neural networks excel at finding hierarchical representations that solve complex tasks over large datasets. How can we humans understand these learned representations? In this work, we present network dissection, an analytic framework to systematically identify the semantics of individual hidden units within image classification and image generation networks. First, we analyze a convolutional neural network (CNN) trained on scene classification and discover units that match a diverse set of object concepts. We find evidence that the network has learned many object classes that play crucial roles in classifying scene classes. Second, we use a similar analytic method to analyze a generative adversarial network (GAN) model trained to generate scenes. By analyzing changes made when small sets of units are activated or deactivated, we find that objects can be added and removed from the output scenes while adapting to the context. Finally, we apply our analytic framework to understanding adversarial attacks and to semantic image editing.
Keywords: computer vision; deep networks; machine learning.
Conflict of interest statement
The authors declare no competing interest.
Figures
References
-
- Zhou B., Khosla A., Lapedriza A., Oliva A., Torralba A., Object detectors emerge in deep scene CNNs. arXiv:1412.6856 (22 December 2014).
-
- Zeiler M. D., Fergus R., “Visualizing and understanding convolutional networks” in European Conference on Computer Vision (Springer, Berlin, Germany, 2014), pp. 818–833.
-
- Mahendran A., Vedaldi A., “Understanding deep image representations by inverting them” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (IEEE, New York, NY, 2015), pp. 5188–5196.
-
- Olah C., et al. , The building blocks of interpretability. Distill 3, e10 (2018).
-
- Bau A., et al. , Identifying and controlling important neurons in neural machine translation. https://openreview.net/pdf?id=H1z-PsR5KX. Accessed 24 August 2020.
Publication types
LinkOut - more resources
Full Text Sources
Other Literature Sources
