

NanoReviser: An Error-Correction Tool for Nanopore Sequencing Based on a Deep Learning Algorithm
- PMID: 32903372
- PMCID: PMC7434944
- DOI: 10.3389/fgene.2020.00900
NanoReviser: An Error-Correction Tool for Nanopore Sequencing Based on a Deep Learning Algorithm
Abstract
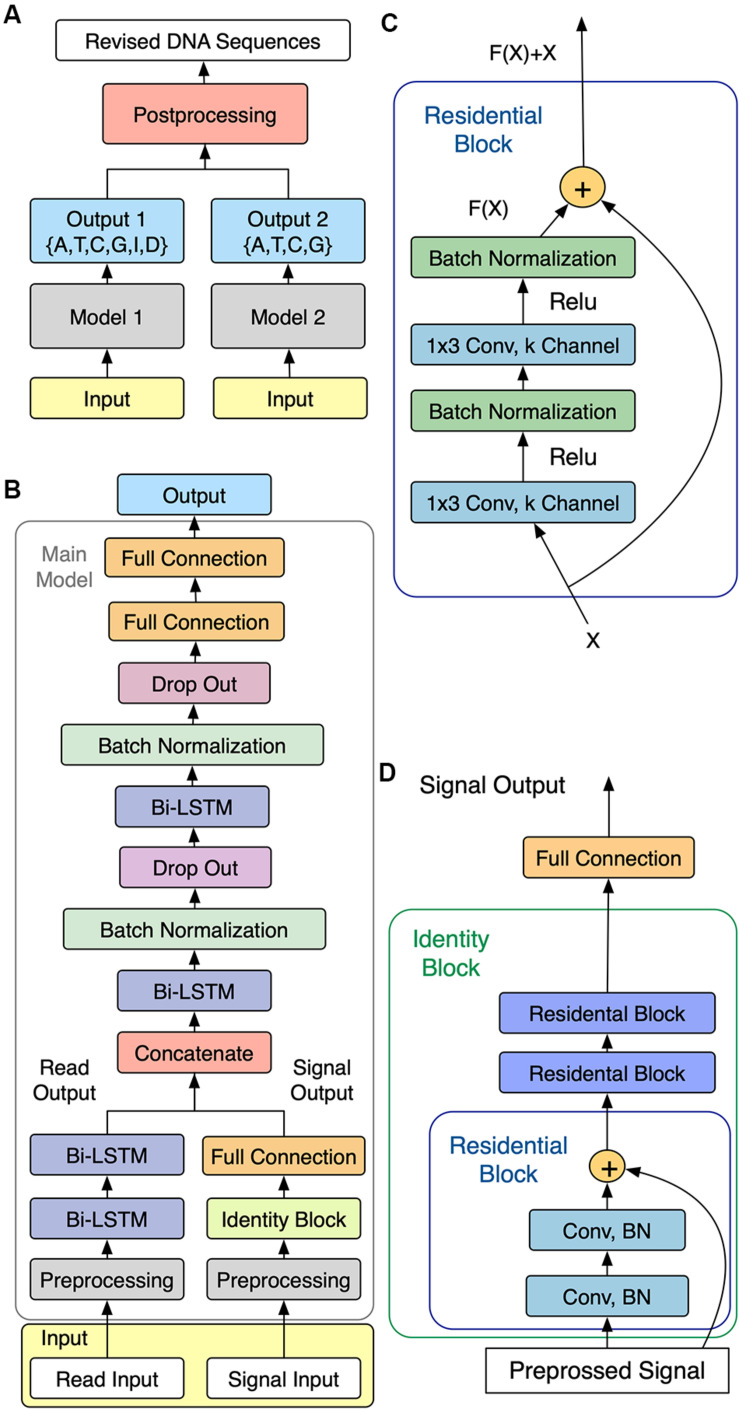
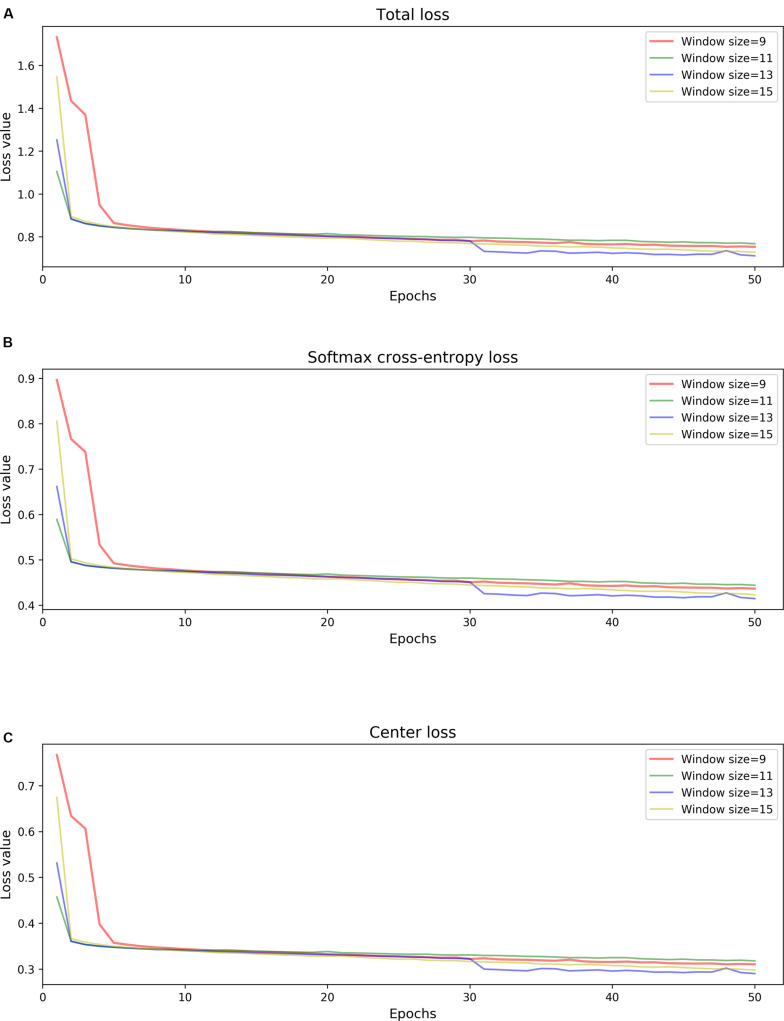
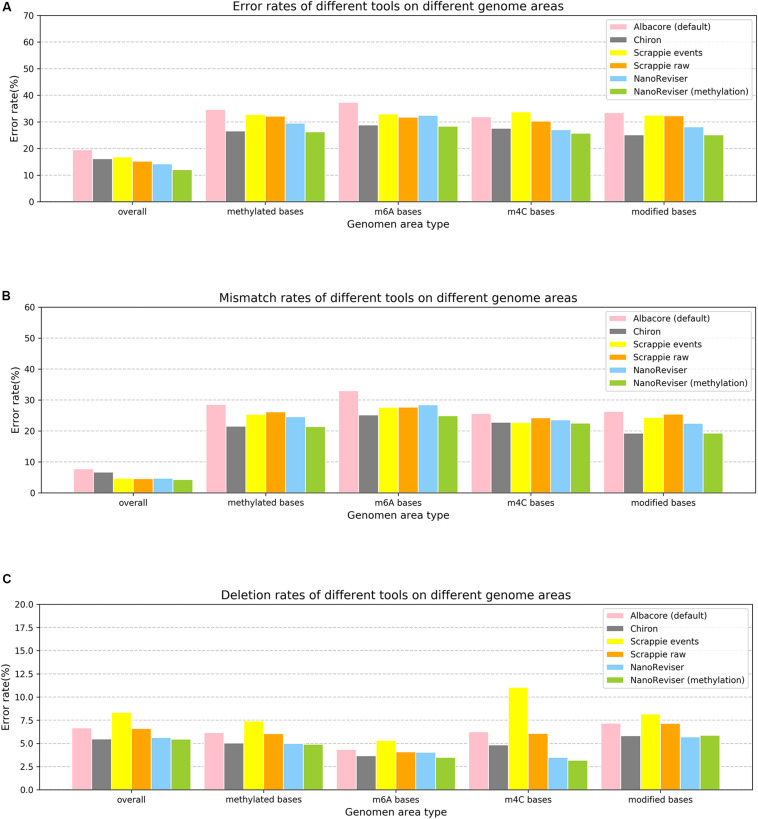
Nanopore sequencing is regarded as one of the most promising third-generation sequencing (TGS) technologies. Since 2014, Oxford Nanopore Technologies (ONT) has developed a series of devices based on nanopore sequencing to produce very long reads, with an expected impact on genomics. However, the nanopore sequencing reads are susceptible to a fairly high error rate owing to the difficulty in identifying the DNA bases from the complex electrical signals. Although several basecalling tools have been developed for nanopore sequencing over the past years, it is still challenging to correct the sequences after applying the basecalling procedure. In this study, we developed an open-source DNA basecalling reviser, NanoReviser, based on a deep learning algorithm to correct the basecalling errors introduced by current basecallers provided by default. In our module, we re-segmented the raw electrical signals based on the basecalled sequences provided by the default basecallers. By employing convolution neural networks (CNNs) and bidirectional long short-term memory (Bi-LSTM) networks, we took advantage of the information from the raw electrical signals and the basecalled sequences from the basecallers. Our results showed NanoReviser, as a post-basecalling reviser, significantly improving the basecalling quality. After being trained on standard ONT sequencing reads from public E. coli and human NA12878 datasets, NanoReviser reduced the sequencing error rate by over 5% for both the E. coli dataset and the human dataset. The performance of NanoReviser was found to be better than those of all current basecalling tools. Furthermore, we analyzed the modified bases of the E. coli dataset and added the methylation information to train our module. With the methylation annotation, NanoReviser reduced the error rate by 7% for the E. coli dataset and specifically reduced the error rate by over 10% for the regions of the sequence rich in methylated bases. To the best of our knowledge, NanoReviser is the first post-processing tool after basecalling to accurately correct the nanopore sequences without the time-consuming procedure of building the consensus sequence. The NanoReviser package is freely available at https://github.com/pkubioinformatics/NanoReviser.
Keywords: DNA methylation; convolution neural network; deep learning; long short-term memory networks; nanopore sequencing; sequencing revising.
Copyright © 2020 Wang, Qu, Yang, Wang and Zhu.
Figures
References
-
- Bouthillier X., Konda K., Vincent P., Memisevic R. (2015). Dropout as data augmentation. arXiv [Preprint] Available online at: http://arxiv.org/abs/1506.08700 (accessed February 16, 2019).
LinkOut - more resources
Full Text Sources
Miscellaneous